







Redis集群第一篇之哨兵(Sentinel)
Redis单机存在的问题:
- 单点故障
- 容量有限
- 压力过大
Redis使用默认的异步复制,其特点是低延迟和高性能
解决方案思路:
使用AKF拆分原则:
AKF旨在提供一个系统化的扩展思路。AKF 把系统扩展分为以下三个维度:
- X 轴:直接水平复制应用进程来扩展系统。
- Y 轴:将功能拆分出来扩展系统。
- Z 轴:基于用户信息扩展系统。

redis做主从或主备
主从、主备区别:
主备:客户端只能访问主,备机只为了接替主机,备机不参与业务。
主从:客户端主机备机都可访问。
企业当中主要选择的是主从复制的方式,主机提供读写,备机一般只用来查询。
如下图所示:

但是主(master)依然是单节点,存在单机故障问题,所以需要对master做HA(高可用),如下图所示:
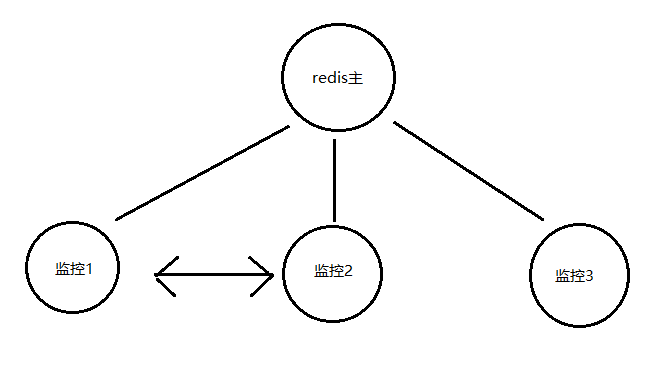
监控服务工作方式:
用3个监控服务对master进行监控,当达到2个以上监控服务认为master挂掉后,从(slave)顶上接替master。
企业一般会使用奇数台监控服务对master进行监控:
-
如果两台监控服务,则每个监控服务都能做决定,会出现网络分区(脑裂)问题。
-
所以如果有n个监控服务,则需要达到n/2+1(过半)个监控服务达成一致判断master存活状态才能决定master是否挂掉。
-
为什么是2n+1:
举个例子:如果有3台监控服务,在满足过半公式的情况下,可以允许1台监控服务故障。
如果有4台监控服务,在满足过半公式的情况下,也只能允许1台监控服务故障,但是4台比3台显然发生一台监控服务故 障的概率更高。
下面实操一下:
#创建一个测试目录
[root@djh ~]# mkdir test
#创建三个redis实例,并将conf文件拷贝到改目录下对其进行部分改造以便接下来的测试
[root@djh test]# cp /etc/redis/* ./
[root@djh test]# ls
6379.conf 6380.conf 6381.conf
[root@djh test]#
修改6379.conf、6380.conf、6381.conf
#默认是后台运行的,我们改成前台运行方便查看日志
daemonize no
#注释掉日志输出,让日志在控制台直接打印
#logfile /var/log/redis_6379.log
#AOF日志关掉
appendonly no
将三个实例的持久化目录清空掉
[root@djh test]# cd /var/lib/redis/
[root@djh redis]# ll
总用量 12
drwxr-xr-x 2 root root 4096 4月 10 17:35 6379
drwxr-xr-x 2 root root 4096 4月 10 17:34 6380
drwxr-xr-x 2 root root 4096 4月 10 17:36 6381
准备工作做完以后,我们开始启动6379服务,此时控制台阻塞运行
[root@djh redis]# redis-server ~/test/6379.conf
另起一个窗口,开启一个客户端连接6379实例,并查看所有key
[root@djh ~]# redis-cli -p 6379
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379>
同样的启动6380和6381服务并查看key,此时是都为空的…
我们希望6379为主(master),另外两个为从(slave),也就是6380和6381追随6379,可以使用如下命令
#redis5之前用SLAVEOF命令,之后用REPLICAOF
127.0.0.1:6380> help SLAVEOF
SLAVEOF host port
summary: Make the server a replica of another instance, or promote it as master. Deprecated starting with Redis 5. Use REPLICAOF instead.
since: 1.0.0
group: server
127.0.0.1:6380> REPLICAOF 127.0.0.1 6379
OK
ok以后我们去看6379日志输出
22469:M 10 Apr 2022 17:59:19.340 * Ready to accept connections
22469:M 10 Apr 2022 18:13:03.284 * Replica 127.0.0.1:6380 asks for synchronization
22469:M 10 Apr 2022 18:13:03.284 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for '48e935e9e1e02d26d73e4e895c34eb67eba4b180', my replication IDs are '0d0768b5c7bc3141bc76a988a9549f7bd4a988cc' and '0000000000000000000000000000000000000000')
22469:M 10 Apr 2022 18:13:03.284 * Replication backlog created, my new replication IDs are 'dc6e64e07d490cece7449f1d35984f1dc6b9cf11' and '0000000000000000000000000000000000000000'
22469:M 10 Apr 2022 18:13:03.284 * Starting BGSAVE for SYNC with target: disk #在磁盘当中落一个rdb文件
22469:M 10 Apr 2022 18:13:03.284 * Background saving started by pid 20538
20538:C 10 Apr 2022 18:13:03.287 * DB saved on disk
20538:C 10 Apr 2022 18:13:03.288 * RDB: 0 MB of memory used by copy-on-write
22469:M 10 Apr 2022 18:13:03.322 * Background saving terminated with success
22469:M 10 Apr 2022 18:13:03.322 * Synchronization with replica 127.0.0.1:6380 succeeded #和备机6380同步成功
再看6380日志输出
18701:M 10 Apr 2022 18:07:34.221 * Ready to accept connections
18701:S 10 Apr 2022 18:13:03.051 * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
18701:S 10 Apr 2022 18:13:03.051 * REPLICAOF 127.0.0.1:6379 enabled (user request from 'id=5 addr=127.0.0.1:33744 fd=8 name= age=294 idle=1 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=44 qbuf-free=32724 obl=0 oll=0 omem=0 events=r cmd=replicaof user=default')
18701:S 10 Apr 2022 18:13:03.283 * Connecting to MASTER 127.0.0.1:6379 #连接上主数据库6379
18701:S 10 Apr 2022 18:13:03.284 * MASTER <-> REPLICA sync started
18701:S 10 Apr 2022 18:13:03.284 * Non blocking connect for SYNC fired the event.
18701:S 10 Apr 2022 18:13:03.284 * Master replied to PING, replication can continue...
18701:S 10 Apr 2022 18:13:03.284 * Trying a partial resynchronization (request 48e935e9e1e02d26d73e4e895c34eb67eba4b180:1).
18701:S 10 Apr 2022 18:13:03.285 * Full resync from master: dc6e64e07d490cece7449f1d35984f1dc6b9cf11:0
18701:S 10 Apr 2022 18:13:03.285 * Discarding previously cached master state.
18701:S 10 Apr 2022 18:13:03.322 * MASTER <-> REPLICA sync: receiving 175 bytes from master to disk
18701:S 10 Apr 2022 18:13:03.322 * MASTER <-> REPLICA sync: Flushing old data #删除掉旧的数据
18701:S 10 Apr 2022 18:13:03.322 * MASTER <-> REPLICA sync: Loading DB in memory #读取db到内存当中
18701:S 10 Apr 2022 18:13:03.322 * Loading RDB produced by version 6.0.6
18701:S 10 Apr 2022 18:13:03.322 * RDB age 0 seconds
18701:S 10 Apr 2022 18:13:03.322 * RDB memory usage when created 1.84 Mb
18701:S 10 Apr 2022 18:13:03.322 * MASTER <-> REPLICA sync: Finished with success
这个时候我们在6379中新增key
127.0.0.1:6379> set k1 hello
OK
可以在6380中看到了,说明集群已经开始同步数据(默认情况下slave是禁止写入的,但是可以通过配置文件修改)
127.0.0.1:6380> get k1
"hello"
如果slave挂掉,master也可以在日志看到(6380已丢失)
22469:M 10 Apr 2022 18:47:40.085 # Connection with replica 127.0.0.1:6380 lost.
那么当6380服务重新启动并追随6379以后,6379在这期间新增的数据呢是否会同步到6380中呢
我们在6379中新增一些数据
127.0.0.1:6379> set k2 world
OK
127.0.0.1:6379> set k3 zhangsan
OK
127.0.0.1:6379> set k4 lisi
OK
然后重启6380服务,并在启动时直接追随6379
[root@djh test]# redis-server 6380.conf --replicaof 127.0.0.1 6379
#成功后看输出的日志,发现没有刷新库的过程并且落rdb文件的事情
25870:S 10 Apr 2022 18:51:23.248 * Loading RDB produced by version 6.0.6
25870:S 10 Apr 2022 18:51:23.248 * RDB age 223 seconds
25870:S 10 Apr 2022 18:51:23.248 * RDB memory usage when created 1.81 Mb
25870:S 10 Apr 2022 18:51:23.248 * DB loaded from disk: 0.000 seconds
25870:S 10 Apr 2022 18:51:23.248 * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
25870:S 10 Apr 2022 18:51:23.248 * Ready to accept connections
25870:S 10 Apr 2022 18:51:23.248 * Connecting to MASTER 127.0.0.1:6379
25870:S 10 Apr 2022 18:51:23.248 * MASTER <-> REPLICA sync started
25870:S 10 Apr 2022 18:51:23.248 * Non blocking connect for SYNC fired the event.
25870:S 10 Apr 2022 18:51:23.248 * Master replied to PING, replication can continue...
25870:S 10 Apr 2022 18:51:23.248 * Trying a partial resynchronization (request dc6e64e07d490cece7449f1d35984f1dc6b9cf11:2954).
25870:S 10 Apr 2022 18:51:23.249 * Successful partial resynchronization with master.
25870:S 10 Apr 2022 18:51:23.249 * MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.
在6380中查看key,发现是有在服务停掉期间的增量数据的
127.0.0.1:6380> keys *
1) "k4"
2) "k3"
3) "k2"
4) "k1"
那么这是怎么做到的呢,我们进去6380的持久化目录查看rdb文件
[root@djh 6380]# cd /var/lib/redis/6380/
[root@djh 6380]# vi dump.rdb

我们可以看到,在rdb文件中有一个replication ID,这里记录着之前它追随的master,当自己挂掉并重新启动以后,会将它追随的master在这期间的增量数据同步到自己的内存当中。
但是,当我们开启aof以后呢? 再试验一下,我们停掉6380服务,并在6379中再次新增一些数据
127.0.0.1:6379> set k5 wangwu
OK
127.0.0.1:6379> set k6 zhaoliu
OK
重启6380服务,并开启aof
[root@djh test]# redis-server 6380.conf --replicaof 127.0.0.1 6379 --appendonly yes
日志打印信息
10508:S 10 Apr 2022 19:07:58.540 * MASTER <-> REPLICA sync: Flushing old data
10508:S 10 Apr 2022 19:07:58.540 * MASTER <-> REPLICA sync: Loading DB in memory
10508:S 10 Apr 2022 19:07:58.540 * Loading RDB produced by version 6.0.6
10508:S 10 Apr 2022 19:07:58.541 * RDB age 0 seconds
10508:S 10 Apr 2022 19:07:58.541 * RDB memory usage when created 1.85 Mb
10508:S 10 Apr 2022 19:07:58.541 * MASTER <-> REPLICA sync: Finished with success
10508:S 10 Apr 2022 19:07:58.541 * Background append only file rewriting started by pid 10515
10508:S 10 Apr 2022 19:07:58.566 * AOF rewrite child asks to stop sending diffs.
查看也是有停掉期间的新增数据,但是上述日志中发现又有了刷新库并且落rdb的事情,这是为什么呢
127.0.0.1:6380> keys *
1) "k5"
2) "k1"
3) "k6"
4) "k3"
5) "k4"
6) "k2"
我们查看6380的持久化目录的aof文件,发现没有replication ID字符串

当redis开启了aof以后是不碰rdb的,只会从aof中读取不碰rdb,rdb中可以记录之前追随的是谁,但是aof文件不会。
以上是slave挂掉,那么master挂掉呢?
首先我们知道,在slave连接到master的时候,master是可以知道谁追随自己的,知道自己身上有几个slave。
此时,ctrl+c停掉6379 master,6380、6381发现master停机。
10508:S 10 Apr 2022 19:26:44.120 # Error condition on socket for SYNC: Operation now in progress
10508:S 10 Apr 2022 19:26:45.122 * Connecting to MASTER 127.0.0.1:6379
10508:S 10 Apr 2022 19:26:45.123 * MASTER <-> REPLICA sync started
10508:S 10 Apr 2022 19:26:45.123 # Error condition on socket for SYNC: Operation now in pro
那么,如果6380想把自己恢复成master怎么做呢,用以下命令
127.0.0.1:6380> REPLICAOF no one
OK
查看6380日志,可以看到自己已变成master,然后再将6381通过REPLICAOF追随自己。
10508:M 10 Apr 2022 19:28:14.065 # Setting secondary replication ID to dc6e64e07d490cece7449f1d35984f1dc6b9cf11, valid up to offset: 5816. New replication ID is b504e6a5f4b47de8827ee3509dfe14000c0a9e6d
10508:M 10 Apr 2022 19:28:14.065 * MASTER MODE enabled (user request from 'id=5 addr=127.0.0.1:34478 fd=8 name= age=942 idle=1 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=36 qbuf-free=32732 obl=0 oll=0 omem=0 events=r cmd=replicaof user=default')
以上是人工的方式处理故障切换,但是显然人工方式效率低下,不能实时的发现redis master宕机并且及时切换master,所以要用到redis的哨兵(Sentinel )。
这里插入一下关于redis主从复制相关的一些配置,打开6379.conf文件
#生产环境中master可能会有很多数据,slave连接master以后,master在给slave准备数据时会有一个时间窗,此时slave还未完成同步,要不要对外提供查询旧的数据,如果设置为no,则要等到同步结束后才可查询
replica-serve-stale-data yes
#slave是否开启只读模式,如果为no,则可写入
replica-read-only yes
#是否直接通过网络给slave同步数据(不往磁盘落rdb文件)
repl-diskless-sync no
#redis有一个小的消息队列,在slave同步新的数据时,master部分数据可能会发生变化,放到这个队列中,这个选项根据生产环境设置大小
# repl-backlog-size 1mb
#最少写几个写成功
# min-replicas-to-write 3
# min-replicas-max-lag 1
Sentinel
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
Redis Sentinel 是一个分布式系统, 你可以在一个架构中运行多个 Sentinel 进程, 这些进程使用流言协议来接收关于主服务器是否下线的信息, 并使用投票协议来决定是否执行自动故障迁移, 以及选择哪个从服务器作为新的主服务器。
操作一下:
停掉之前所有的redsi服务,然后创建Sentinel的配置文件
[root@djh test]# vi 26379.conf
写一下26379.conf的基本配置信息
port 26379 #端口号为26379
sentinel monitor mymaster 127.0.0.1 6379 2 #监控的集群名称mymaster(自己随便起个名),ip,端口,权重值(投票数)
~
~
同样再创建26380.conf、26381.conf,配置信息分别修改下端口号为26380和26381
开始启动三个redis服务
[root@djh test]# redis-server ./6379.conf
#追随6379
[root@djh test]# redis-server ./6380.conf --replicaof 127.0.0.1 6379
#追随6379
[root@djh test]# redis-server ./6381.conf --replicaof 127.0.0.1 6379
准备启动sentinel,启动一个运行在 Sentinel 模式下的 Redis 服务器:
[root@djh test]# redis-server ./26379.conf --sentinel
启动以后可以在日志中看到其他的两个slave
2479:X 11 Apr 2022 01:09:34.965 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
2479:X 11 Apr 2022 01:09:34.968 # Sentinel ID is 005d79774ac1e26634e6a84daf9562df763ab220
2479:X 11 Apr 2022 01:09:34.968 # +monitor master mymaster 127.0.0.1 6379 quorum 2
2479:X 11 Apr 2022 01:09:34.970 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
2479:X 11 Apr 2022 01:09:34.982 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
我们将其他两个sentinel也启动
[root@djh test]# redis-server ./26380.conf --sentinel
[root@djh test]# redis-server ./26381.conf --sentinel
在日志中可以看到,不仅有两个slave的信息,还有两个哨兵的信息(如何做到发现它们的?是基于redis的发布订阅)
10771:X 11 Apr 2022 01:15:29.655 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
10771:X 11 Apr 2022 01:15:29.657 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
10771:X 11 Apr 2022 01:15:29.854 * +sentinel sentinel 87753ba37003860cdbd20ca25a32db8e6c2de420 127.0.0.1 26380 @ mymaster 127.0.0.1 6379
10771:X 11 Apr 2022 01:15:31.380 * +sentinel sentinel 005d79774ac1e26634e6a84daf9562df763ab220 127.0.0.1 26379 @ mymaster 127.0.0.1 6379
现在我们开始测试sentinel的自动故障转移,ctrl+c停掉redis6379服务
首先我们可以在其他两个slave中看到这样的日志信息:无法连接到6379
3976:S 11 Apr 2022 01:21:03.894 # Error condition on socket for SYNC: Operation now in progress
3976:S 11 Apr 2022 01:21:04.903 * Connecting to MASTER 127.0.0.1:6379
3976:S 11 Apr 2022 01:21:04.903 * MASTER <-> REPLICA sync started
3976:S 11 Apr 2022 01:21:04.903 # Error condition on socket for SYNC: Operation now in progress
在短暂延迟之后,它们开始投票选出新的master,此时他们将6381选为新的master,6380将追随6381
6380日志:
3976:S 11 Apr 2022 01:21:12.836 * REPLICAOF 127.0.0.1:6381 enabled (user request from 'id=7 addr=127.0.0.1:38790 fd=11 name=sentinel-87753ba3-cmd age=371 idle=0 flags=x db=0 sub=0 psub=0 multi=4 qbuf=329 qbuf-free=32439 obl=45 oll=0 omem=0 events=r cmd=exec user=default')
3976:S 11 Apr 2022 01:21:12.838 # CONFIG REWRITE executed with success.
3976:S 11 Apr 2022 01:21:12.931 * Connecting to MASTER 127.0.0.1:6381
3976:S 11 Apr 2022 01:21:12.931 * MASTER <-> REPLICA sync started
3976:S 11 Apr 2022 01:21:12.931 * Non blocking connect for SYNC fired the event.
3976:S 11 Apr 2022 01:21:12.931 * Master replied to PING, replication can continue...
3976:S 11 Apr 2022 01:21:12.931 * Trying a partial resynchronization (request ee4cbab8c3060756d50b93492a925bdb23a2a09a:87769).
3976:S 11 Apr 2022 01:21:12.932 * Successful partial resynchronization with master.
3976:S 11 Apr 2022 01:21:12.932 # Master replication ID changed to c3634d1b11408898440ea07e9fcfc5473e7ed74b
3976:S 11 Apr 2022 01:21:12.932 * MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.
26380日志:
7548:X 11 Apr 2022 01:21:12.257 # +new-epoch 1
7548:X 11 Apr 2022 01:21:12.257 # +try-failover master mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:12.259 # +vote-for-leader 87753ba37003860cdbd20ca25a32db8e6c2de420 1
7548:X 11 Apr 2022 01:21:12.263 # 005d79774ac1e26634e6a84daf9562df763ab220 voted for 87753ba37003860cdbd20ca25a32db8e6c2de420 1
7548:X 11 Apr 2022 01:21:12.263 # b878aa8130cf8cba63931ca7545c1779d88d023e voted for 87753ba37003860cdbd20ca25a32db8e6c2de420 1
7548:X 11 Apr 2022 01:21:12.321 # +elected-leader master mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:12.321 # +failover-state-select-slave master mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:12.387 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:12.387 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:12.487 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:12.747 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:12.748 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:12.836 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:13.429 # -odown master mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:13.741 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:13.741 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:13.815 # +failover-end master mymaster 127.0.0.1 6379
7548:X 11 Apr 2022 01:21:13.815 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381
7548:X 11 Apr 2022 01:21:13.815 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
7548:X 11 Apr 2022 01:21:13.815 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
7548:X 11 Apr 2022 01:21:43.835 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
sentinel也会对自己的配置文件进行修改,我们可以看一下26380.conf
port 26380
sentinel myid 87753ba37003860cdbd20ca25a32db8e6c2de420
# Generated by CONFIG REWRITE
protected-mode no
user default on nopass ~* +@all
dir "/root/test"
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 127.0.0.1 6381 2 #之前追随的6379,现在已自动变为6381
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
sentinel known-replica mymaster 127.0.0.1 6379
sentinel known-replica mymaster 127.0.0.1 6380
sentinel known-sentinel mymaster 127.0.0.1 26381 b878aa8130cf8cba63931ca7545c1779d88d023e
sentinel known-sentinel mymaster 127.0.0.1 26379 005d79774ac1e26634e6a84daf9562df763ab220
sentinel current-epoch 1
"26380.conf" 15L, 606C
总结:
redis单机模式存在三个问题:
- 单点故障
- 容量有限
- 压力过大
要解决这三个问题,需要将redis做集群(redis的主从复制)。
- redis默认以异步的方式将主(master)的数据同步给从(slave)
- redis的主可以进行读写,从一般只用来查询,实现读写分离,提高负载能力
- redis只有一个主,也存在单点问题,如何解决?使用哨兵(sentinel)
- 多个sentinel对主机进行监控,以及主机发生故障后,自动地进行故障转移。
以上就是redis集群之哨兵模式,但似乎只能解决redis的单点故障和压力问题,redis容量有限的问题并没有解决,如何解决redis的容量有限问题,请看下一篇















 3358
3358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











