







损失函数
一句话:损失函数就是计算预测值和真实值之间的误差。
损失函数可以分为以下三类:
- 回归损失函数:应用于预测连续的值,如房价,年龄等
- 分类损失函数:用于离散的值,图像分类,图像分割等
- 排序损失函数:用于预测输入数据之间的相对距离
下面逐一介绍损失函数
- L1 loss
L1 loss 也称为平均绝对误差(Mean Absolute Error),简称MAE,计算真实值和预测值之间绝对差之和的平均值。
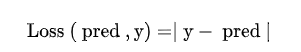
应用场合:回归预测
# L1 loss
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
mae_loss = torch.nn.L1Loss()
output = mae_loss(input, target)
- L2 loss
称为均方误差,对于大部分回归问题,pytorch默认使用L2 loss
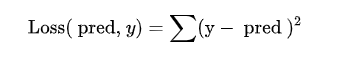
使用平方意味着当预测值离目标值更远时在平方后具有更大的惩罚,预测值离目标值更近时在平方后惩罚更小,因此,当异常值与样本平均值相差格外大时,模型会因为惩罚更大而开始偏离,相比之下,L1对异常值的鲁棒性更好。
# L2 loss
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
mse_loss = torch.nn.MSELoss()
output = mse_loss(input, target)
推荐一下:更详细看L1 L2的差别看博主另外一篇博客L1和L2区别与改进
- Cross-Entropy loss
此损失函数计算提供的一组出现次数或随机变量的两个概率分布之间的差异。它用于计算预测值与实际值之间的平均差异的分数。

应用场景:二分类及多分类
特点:正确分类和不正确分类都会给惩罚,这样会让正负样本之间变得更可分。
# Cross-Entropy loss
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
cross_entropy_loss = torch.nn.CrossEntropyLoss()
output = cross_entropy_loss(input, target)
- Hinge Embedding loss
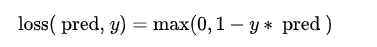
其中y为1或-1。
应用场景:分类问题,特别是确定两个输入是否不同或相似时。用于非线性嵌入或半监督学习任务。
#Hinge Embedding loss
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
hinge_loss = torch.nn.HingeEmbeddingLoss()
output = hinge_loss(input, target)
- Triplet Margin Loss
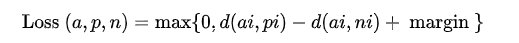
三元组有a(anchor),p(正样本),n(负样本)组成。
应用场景:确定样本之间的相对相似性,用于基于内容检索问题。
# Triplet Margin Loss
anchor = torch.randn(100, 128, requires_grad=True)
positive = torch.randn(100, 128, requires_grad=True)
negative = torch.randn(100, 128, requires_grad=True)
triplet_margin_loss = torch.nn.TripletMarginLoss(margin=1.0, p=2)
output = triplet_margin_loss(anchor, positive, negative)
- KL Divergence Loss
计算两个概率分布之间的差异
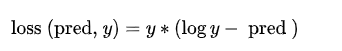
输出表示两个概率分布的接近程度。如果预测的概率分布与真实的概率分布相差很远,就会导致很大的损失。如果 KL Divergence 的值为零,则表示概率分布相同。
KL Divergence 与交叉熵损失的关键区别在于它们如何处理预测概率和实际概率。交叉熵根据预测的置信度惩罚模型,而 KL Divergence 则没有。KL Divergence 仅评估概率分布预测与ground truth分布的不同之处。
应用场景:逼近复杂函数多类分类任务确保预测的分布与训练数据的分布相似
# KL Divergence Loss
input = torch.randn(2, 3, requires_grad=True)
target = torch.randn(2, 3)
kl_loss = torch.nn.KLDivLoss(reduction = 'batchmean')
output = kl_loss(input, target)















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











