







梯度问题
- 当预测框和GT差别过大时,梯度值不至于过大
- 当预测框和GT差别很小的,梯度值足够小
下面(1)(2)(3)分别是L2,L1,Smooth L1的损失函数
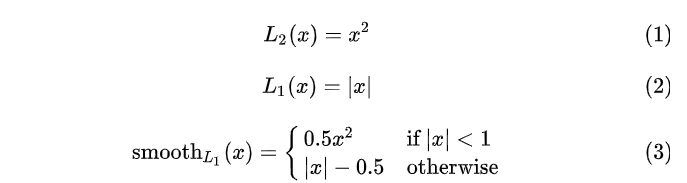
下面(1)(2)(3)分别是L2,L1,Smooth L1损失函数对X求导的结果表达式
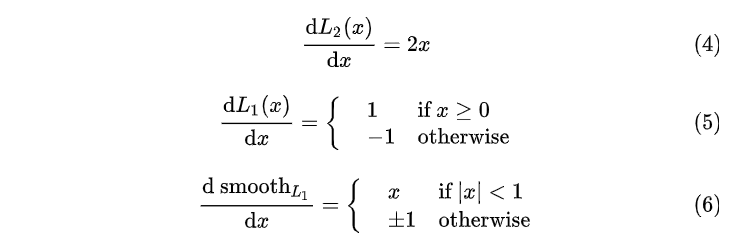
- 观察(4),当 X增大时 L2 损失对 X 的导数也增大。这就导致训练初期,预测值与groud truth差异过于大时,损失函数对预测值的梯度十分大,训练不稳定。
- 观察(5),L1对X的导数为常数,这就导致训练后期,预测值与GT差异很小的时候,仍会保持梯度绝对值为1,而learning rate保持不变的时候,损失函数将在最小值附近波动,难以收敛到最高的精度
- 观察(6),Smooth L1在X比较小的时候,梯度也会很小,而在X比较大的时候,对X的梯度绝对值达到上限1,也不会太大以至于破坏网络参数,Smooth L1完美避开了L1 和L2损失的缺陷。
总结:对于误差较大的异常样本,mse损失远大于mae,使用mse的话模型会给予异常值更大的权值,全力减少异常值造成的误差,导致模型整体表现下降。因此,训练数据追踪异常值较多时,mae较好。但mae在极值点梯度会发现跃迁,即使很小的损失也会造成较大的误差,为了解决这个问题,可以在极值附近动态减少学习率。
















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











