







目录
1. 论文&代码源
《Gait Lateral Network: Learning Discriminative and Compact Representations for Gait Recognition》
论文地址:https://link.springer.com/chapter/10.1007/978-3-030-58545-7_22
代码下载地址: 作者未提供源代码?
2. 论文亮点
- 利用深度CNN中的特征金字塔来增强步态特征,由不同阶段作用的轮廓级和集合级特征以自上而下的方式与横向连接合并;
- 提出紧凑块(compact block),可以在不妨碍准确性的情况下大大减少步态表征维度;
- 可以同时学习鉴别性和紧凑性表征。
3. 框架解读
在Fig.1中可以看出,模型除了具有识别不同人的能力之外,对于每个人体剪影的学习应当紧凑,否则会产生大量的存储负担。
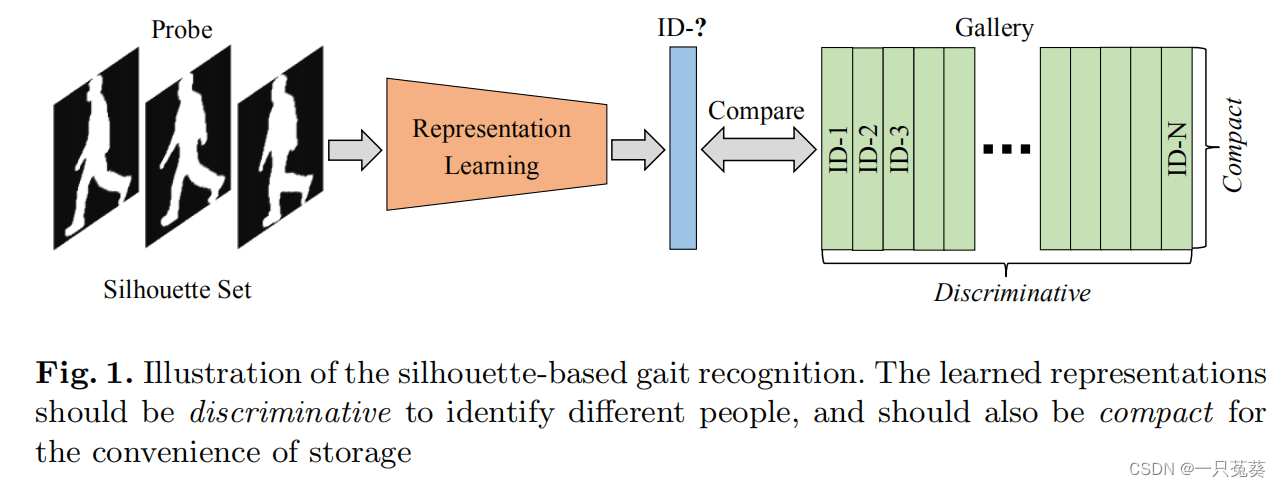
值得注意的是,GLN模型的表征维度被固定为256,与GaitSet相比减少了近两个数量级,对于所有行走条件下的数据处理性能得到了一定的提高。
GLN模型的backbone参考CaitSet,如下图所示:

S
t
a
g
e
0
Stage0
Stage0负责将剪影轮廓转换为内部特征,后续被分为
s
i
l
−
l
e
v
e
l
sil-level
sil−level和
s
e
t
−
l
e
v
e
l
set-level
set−level两个分支,
S
P
SP
SP负责将轮廓集合特征进行聚合。
注意:此处的
M
a
x
P
o
o
l
i
n
g
MaxPooling
MaxPooling与空间(高度和宽度)维度的不同,
M
a
x
P
o
o
l
i
n
g
f
o
r
S
e
t
P
o
o
l
i
n
g
MaxPooling \ for \ SetPooling
MaxPooling for SetPooling是在集合维度上进行的。
3.1 横向连接☆
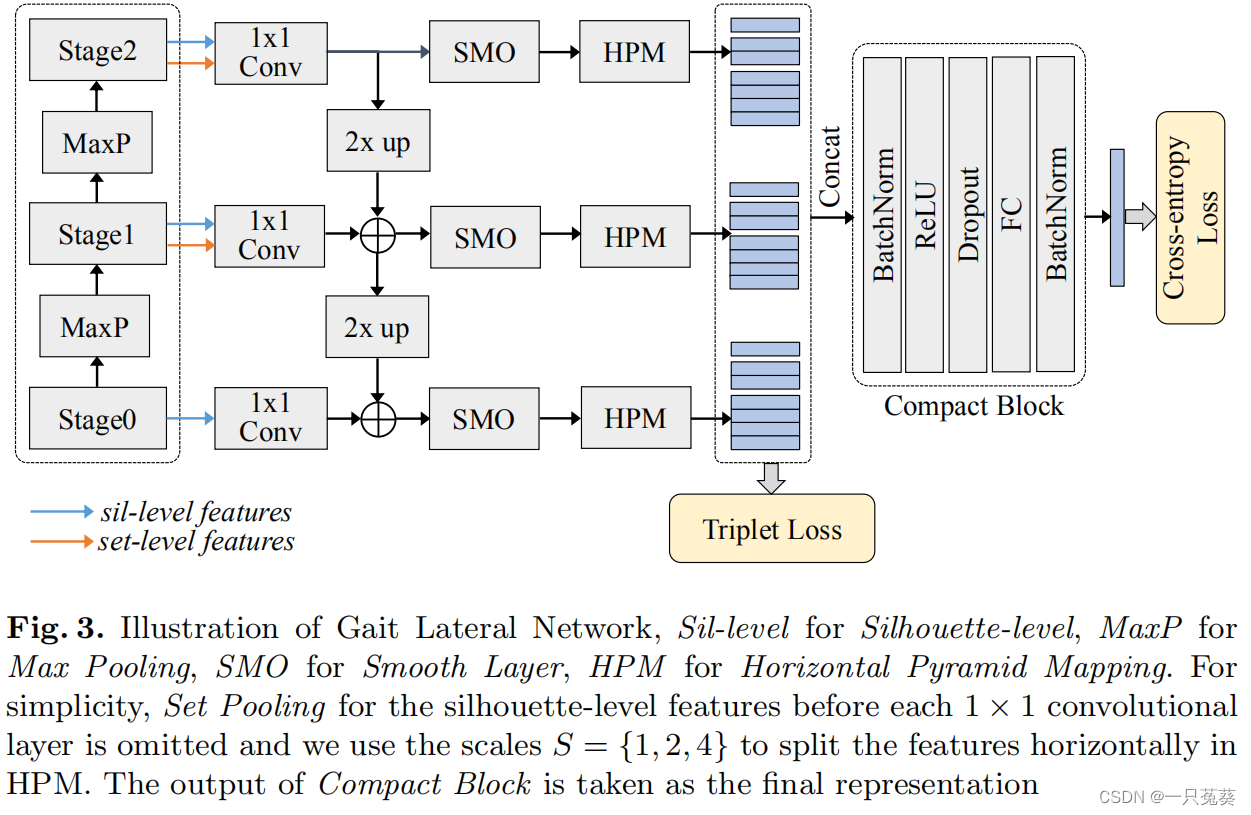
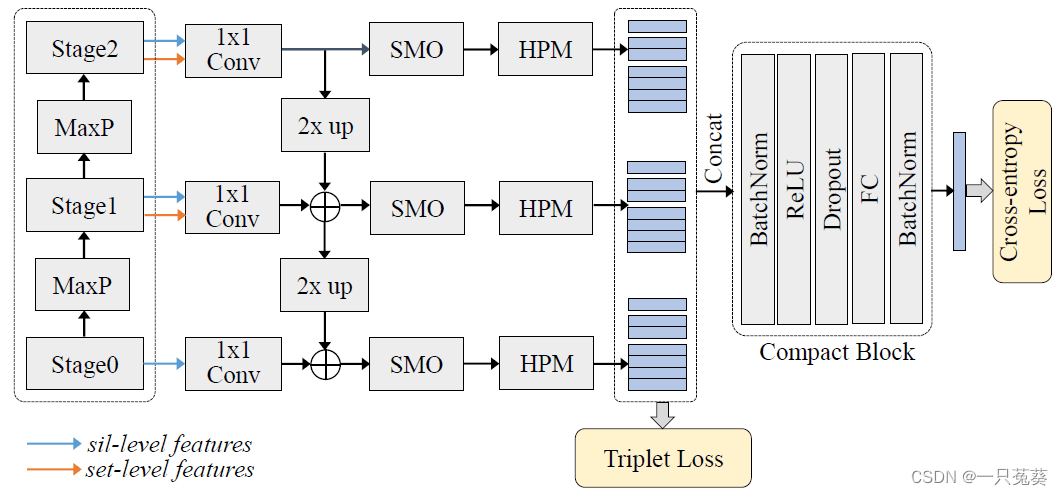
在 S a t g e 0 Satge0 Satge0中只有轮廓数据,因此只输出轮廓级特征,后面的 S t a g e 1 , S t a g e 2 Stage1, Stage2 Stage1,Stage2均输出轮廓级和集合级两种类型的特征,之后3个 S t a g e Stage Stage使用一个 1 × 1 1 \times 1 1×1卷积核来重新排列特征并调整通道维度。随后,从最后一个 S t a g e Stage Stage开始,在空间维度上(高度和宽度)进行2倍上采样(最邻近元法),并添加到上一阶段生成的特征中(因为经过 1 × 1 1 \times 1 1×1卷积核,所以通道维度是相等的,可以进行相加操作)。当自上而下操作完毕,在每阶段各加一个平滑层 S M O SMO SMO,用来减轻由上采样和不同阶段之间语义差异引起的混叠效应。
3.2 紧凑块
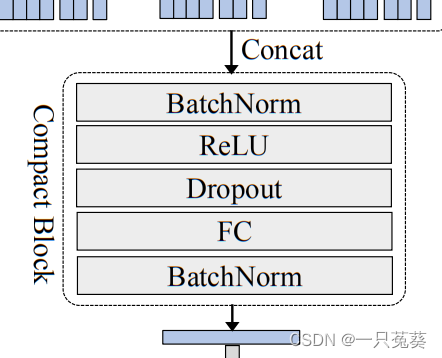
紧凑块提出的前提是,由于水平金字塔池化最终获得的维度非常高,并且作者在实验过程中发现,不同尺度的金字塔层级下的编码信息有重复,所以作者推测HPM得到的高维信息存在大量的冗余信息。
紧凑块的目的是,在不影响准确性的情况下,将高维表示的信息提炼成紧凑的形式。
C
o
m
p
a
c
t
B
l
o
c
k
Compact \ Block
Compact Block由
B
a
t
c
h
N
o
r
m
BatchNorm
BatchNorm、
R
e
L
u
ReLu
ReLu、
D
r
o
p
o
u
t
Dropout
Dropout、
F
C
FC
FC和另一个
B
a
t
c
h
N
o
r
m
BatchNorm
BatchNorm组成,各个部分的作用如下:
B
a
t
c
h
N
o
r
m
BatchNorm
BatchNorm-
1
1
1:对
H
P
M
HPM
HPM得到的特征进行归一化,有助于稳定训练;
R
e
L
u
ReLu
ReLu:增加紧凑块非线性;
D
r
o
p
o
u
t
Dropout
Dropout:这是紧凑块的关键!它能够从每个高位特征集合中选择一个小的子集(低维);
F
C
FC
FC:将
D
r
o
p
o
u
t
Dropout
Dropout中的小子集映射到更具有辨别力的空间中,
F
C
FC
FC的输出决定了最终表示的维度,此实验设置为256;
B
a
t
c
h
N
o
r
m
BatchNorm
BatchNorm-
2
2
2:方便优化交叉熵损失。
3.3 训练策略
GLN的训练过程包括横向预训练和全局训练两个部分。从下图不难看出,训练过程涉及两种损失:三元组损失和交叉熵损失,三元组损失在横向连接的HPM之后接入,起到中间监督的作用;交叉熵损失则在横向连接和紧凑块都训练完成之后接入,起到全局表征的作用。
3.3.1 三元组损失
首先,为了合理地初始化一个横向连接网络,作者提出了一个仅由三元组损失监督的横向预训练。这部分就是将所有阶段batch all的三元组损失添加到HPM在所有阶段获得的每个部分的特征中,对应的公式为:
L
t
p
=
1
N
t
p
+
∑
s
∈
S
∑
t
=
1
s
⏞
b
i
n
s
∑
i
=
1
P
∑
j
=
1
K
⏞
a
n
c
h
o
r
s
∑
a
=
1
,
a
≠
j
;
K
⏞
p
o
s
i
t
i
v
e
∑
b
=
1
,
b
≠
i
;
P
∑
c
=
1
K
⏞
n
e
g
a
t
i
v
e
[
m
+
d
s
,
t
,
i
,
j
,
i
,
a
s
,
t
,
i
,
j
,
b
,
c
]
+
(
1
)
L_{tp} = \frac 1{N_{tp+}} \overbrace {\sum _{s \in S} \sum _{t=1}^s}^{bins} \overbrace {\sum _{i=1}^P \sum _{j=1}^K}^{anchors} \overbrace {\sum _{a=1,a \neq j; }^K}^{positive} \overbrace {\sum _{b=1,b \neq i;}^P \sum_{c=1}^K}^{negative}[m+d_{s,t,i,j,i,a}^{s,t,i,j,b,c}]_+\qquad(1)
Ltp=Ntp+1s∈S∑t=1∑s
binsi=1∑Pj=1∑K
anchorsa=1,a=j;∑K
positiveb=1,b=i;∑Pc=1∑K
negative[m+ds,t,i,j,i,as,t,i,j,b,c]+(1)
其中,
N
t
p
+
N_{tp+}
Ntp+是在mini-batch中非零损失项的三元组数值;
S
S
S是HPM中的多个尺度;
P
P
P是mini-batch中的ID数量;
K
K
K是该ID的序列数量;
m
m
m是阈值(margin threshold)。
d
s
,
t
,
i
,
j
,
i
,
a
s
,
t
,
i
,
j
,
b
,
c
=
d
i
s
t
(
f
(
s
i
l
i
,
j
s
,
t
)
,
f
(
s
i
l
i
,
a
s
,
t
)
)
−
d
i
s
t
(
f
(
s
i
l
i
,
j
s
,
t
)
,
f
(
s
i
l
b
,
c
s
,
t
)
)
(
2
)
d_{s,t,i,j,i,a}^{s,t,i,j,b,c} = dist(f(sil_{i,j}^{s,t}),f(sil_{i,a}^{s,t}))-dist(f(sil_{i,j}^{s,t}),f(sil_{b,c}^{s,t}))\qquad(2)
ds,t,i,j,i,as,t,i,j,b,c=dist(f(sili,js,t),f(sili,as,t))−dist(f(sili,js,t),f(silb,cs,t))(2)
其中,
f
f
f表示特征提取过程;
s
i
l
sil
sil是步态剪影集(数据集);
d
i
s
t
dist
dist用于衡量两个特征间的相似度(如欧氏距离)。
在横向预训练过程中,为了防止过拟合,作者没有降低模型的学习率。
3.3.2 交叉熵损失
训练集中的每个ID都被视为一个单独的类,并采用标签平滑技术,对应的公式为:
L
c
e
=
−
1
P
×
K
∑
i
=
1
P
∑
j
=
1
K
∑
n
=
1
N
q
n
i
j
log
p
n
i
j
(
3
)
L_{ce}=- \frac 1{P \times K} \sum _{i=1}^P \sum _{j=1}^K \sum _{n=1}^N q_n^{ij} \log p_n^{ij}\qquad(3)
Lce=−P×K1i=1∑Pj=1∑Kn=1∑Nqnijlogpnij(3)
其中,
N
N
N是训练集中ID的数量;
p
p
p是属于每个ID的概率值;
q
q
q用于编码身份信息,其计算方法如下(以第
y
y
y个ID为例):
q
n
i
j
=
{
1
−
N
−
1
N
ϵ
,
n
=
y
ϵ
N
,
others
(
4
)
q_n^{ij}= \begin {cases} 1-\frac{N-1}{N}\epsilon ,&& n=y\\ \frac {\epsilon}{N} ,&& \text{others} \end{cases}\qquad(4)
qnij={1−NN−1ϵ,Nϵ,n=yothers(4)
其中,
ϵ
\epsilon
ϵ是一个数值很小的常数,使模型对于训练集不会过于敏感,作者在试验中将
ϵ
=
0.1
\epsilon =0.1
ϵ=0.1。
3.3.3 总损失函数
L
=
L
t
p
+
L
c
e
(
5
)
L=L_{tp}+L_{ce}\qquad(5)
L=Ltp+Lce(5)

值得注意的是,在训练阶段,在Compact Block之后引入了另一个全连接层,以计算每个ID的概率值,但是在测试阶段取消了这个全连接层。Compact Block的输出作为每个步态剪影集的最终表示形式,用来匹配probe和gallery。
4. 实验结果
4.1 数据集预处理
- 实验中的所有模型都是基于PyTorch实现的,CASIA-B和OU-MVLP两个数据集均使用基于输入/输出架构的卷积神经网络(Input/Output Architectures Convolutional Neural Network, I /O-ACNN) 方法进行预处理。
- CASIA-B数据集的(每个batch)受试者数量为 8 8 8、受试者序列为 16 16 16、序列的剪影图像输入大小为 128 × 88 128 \times 88 128×88、卷积通道数设置为 ( 32 , 64 , 128 ) (32, 64,128) (32,64,128);OU-MVLP数据集的(每个batch)受试者数量为 32 32 32、受试者序列为 16 16 16、序列的剪影图像输入大小为 64 × 44 64 \times 44 64×44、卷积通道数设置为 ( 64 , 128 , 256 ) (64,128,256) (64,128,256)。CSAIA-B的迭代次数为 10000 10000 10000次,OU-MVLP的迭代次数为 50000 50000 50000。
- 横向连接中 1 × 1 1 \times 1 1×1卷积层和平滑层的输出尺寸均为 256 256 256,水平分割的尺度 S = [ 1 , 2 , 4 , 8 , 16 ] S=[1,2,4,8,16] S=[1,2,4,8,16],通过HPM得到的每一部分的特征维度为 256 256 256。
- Compact Block中的Dropout设置为 0.9 0.9 0.9,维度同样是 256 256 256。
- 采用随机梯度下降法(Stochastic Gradient Descent, SGD) 【An overview of gradient descent optimization algorithms】进行优化,初始学习率设置为 0.1 0.1 0.1,并且在横向预训练中没有减小,在全局训练中,学习率进行了3次 1 10 \frac 1{10} 101的减小,直至训练结果收敛。动量(momentum)设为 0.9 0.9 0.9,权重衰减系数为 5 e − 4 5e-4 5e−4。公式 ( 1 ) (1) (1)中的阈值 m = 0.2 m=0.2 m=0.2。
- 此外,作者还使用了论文【Bag of tricks and a strong baseline for deep person re-identification】 中提到的预热学习策略(Warmup strategy) 在训练开始时进行“预热”。
4.2 数据对比
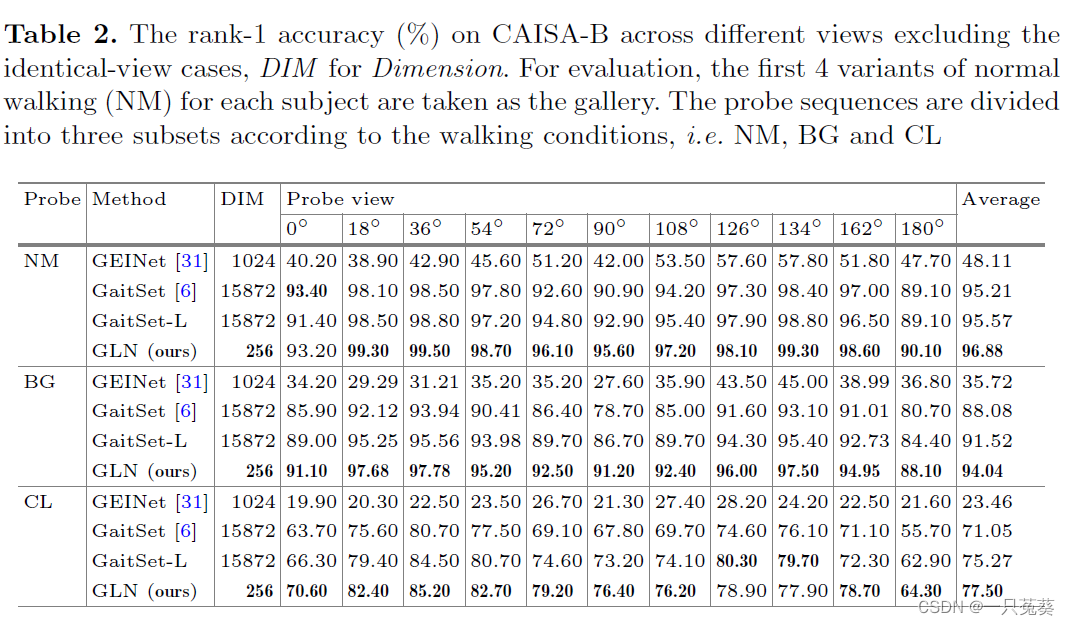
4.2.1 CASIA-B数据集
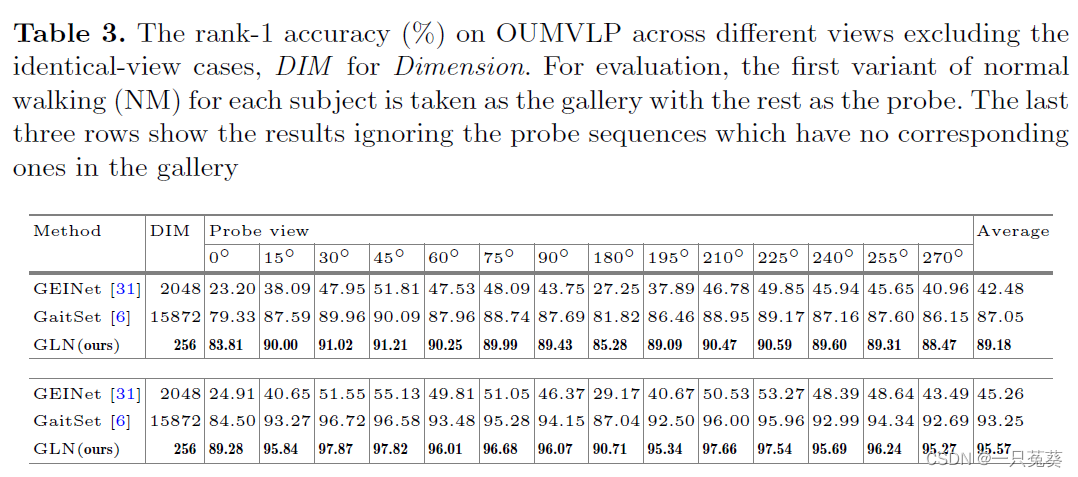
4.2.2 OU-MVLP数据集
4.3 消融实验
略
5. 总结
本文中,作者提出了一个名为 “步态横向网络”(GLN)的新网络,它可以从剪影中学习辨别性的和紧凑的特征,用于步态识别。具体来说,深度卷积网络中固有的特征金字塔被用来学习鉴别性的步态表示。骨干网络中不同阶段提取的剪影级和集合级特征,以自上而下的方式与横向连接合并,通过聚合更多的视觉细节来增强步态特征。作者还提出了一个紧凑块来学习紧凑的步态表征,这可以大大减少步态表征的维度且不影响其准确性。在CASIA-B和OU-MVLP数据集上进行的大量实验,最终实验结果表明:在所有的行走条件下使用256维的特征,GLN都达到了最先进的性能。
0. 知识补充
0.1 上采样
0.1.1 反卷积(转置卷积)
反卷积常用于细化粗的特征图(上采样的用途都有这个吧?),
o
u
t
=
(
i
n
−
1
)
∗
s
t
r
i
d
e
+
k
e
r
n
e
l
−
2
∗
p
a
d
d
i
n
g
out = (in -1)*stride + kernel -2*padding
out=(in−1)∗stride+kernel−2∗padding
0.1.2 插值法
最邻近元法: 不需要进行计算,可能会造成灰度不连续,灰度变化呈锯齿状。
双线性插值法:
三次内插法: 利用三次多项式
S
(
x
)
S(x)
S(x)求逼近理论上最佳的插值函数
s
i
n
x
x
\frac {sinx}{x}
xsinx
S
(
x
)
=
{
1
−
2
∣
x
∣
2
+
∣
x
∣
3
,
0
≤
∣
x
∣
<
1
4
−
8
∣
x
∣
+
5
∣
x
∣
2
−
∣
x
∣
3
,
1
≤
∣
x
∣
<
2
0
,
∣
x
∣
≥
2
S(x)= \begin{cases} 1-2|x|^2 +|x|^3, &0 \le |x| \lt 1\\ 4-8|x|+5|x|^2-|x|^3, &1 \le |x| \lt 2\\ 0, & |x| \ge 2 \end{cases}
S(x)=⎩⎪⎨⎪⎧1−2∣x∣2+∣x∣3,4−8∣x∣+5∣x∣2−∣x∣3,0,0≤∣x∣<11≤∣x∣<2∣x∣≥2
0.1.3 反池化
反平均池化: 还原成原始大小,并将平均池化的值填入
反最大池化: 记住最大值的索引值,放入原始大小原位置,其余位置的值设为0
0.2 水平金字塔池化(HPM)
HPM模型可以充分利用行人不同局部空间信息,使得及时存在重要部分缺失,仍能正确识别。

0.3 特征金字塔网络(FPN)
0.3.1 经典方法
特征金字塔(feature pyramids)是多尺度目标检测中一个基础组成部分,现阶段主要有四种特征金字塔的变种形式。
多尺度目标检测:多尺度是目标检测与图像分类两个任务的一大区别。分类问题通常针对同一种尺度,如ImageNet中的224大小;而目标检测中,模型需要对不同尺度的物体都能检测出来,这要求模型对于尺度要具有鲁棒性。
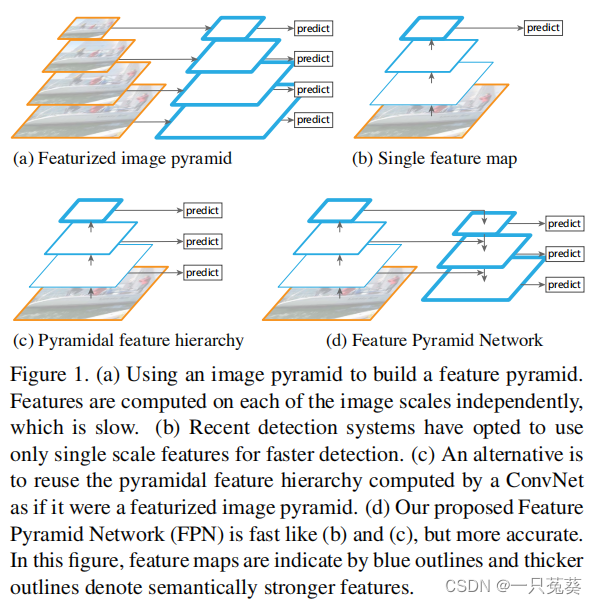
(a) Feature image pyramid
利用图像金字塔去构建特征金字塔,通过尺度不变特征变换(Scale-invariant feature transform,SIFT)、方向梯度直方图(Histogram of Oriented Gradient, HOG)等传统特征提取算法对不同尺度的图像提取特征。此方法被广泛应用了一段时间,如经典的DPM算法(Deformable Part Model)。
(b) Single feature map
基于CNN框架,相对于(a)方法,此方法能够通过卷积更好地学习到图像的深层特征,且具有鲁棒性好等优点。但遇到多尺度目标检测时,需要使用图像金字塔结构。
(c) Pyramidal feature hierarchy
是SSD的框架,SSD网络框架是目标检测领域一个经典的模型,不同于主流的目标检测模型,SSD使用CNN金字塔的层级特征。因为CNN是自底向上的对图像做卷积和池化计算,一般情况下,图像的feature map越来越小(产生了多尺度的特征图),利用image pyramid思想,SSD重新利用CNN前向过程中计算出多层的多尺度的feature map在模型内部构成feature pyramids,很好的解决了多尺度图像检测问题,并且这种形式是不消耗额外的资源的。但SSD放弃使用low-level的feature map,而是从conv4_3开始建立金字塔,并加入了一些新的层。这就决定了模型对小目标的检测效果不好。
(d) Feature Pyramid Network
是FPN的结构,在SSD结构的基础上,加入top-down结构和横向连接,可以很好的结合具有高分辨率的low-level和具有丰富语义的深层网络。在快速构建出在所有尺度上都具有语义信息的特征金字塔。
0.3.2 框架构成
- Bottom-up 自下而上
即网络的前向传播过程,一般情况下,特征图会随着卷积池化层越来越小,也存在输入输出大小不变的情况,将大小不变的feature map层成为stage,每次抽取的特征都是stage最后一层的输出(因为最后一层具有最强的语义特征,这是为啥??),构成特征金字塔。 - Top-down 自上而下
通过上采样进行,横向连接是将上采样结果与自下而上的相同大小的feature map相融合,融合后为消除上采样的混叠效应(aliasing effect),采用 3 × 3 3\times 3 3×3的卷积核对每个融合结果进行卷积。
混叠效应:在统计、信号处理和相关领域中,混叠是指取样信号被还原成连续信号时产生彼此交叠而失真的现象。当混叠发生时,原始信号无法从取样信号还原。而混叠可能发生在时域上,称做时间混叠,或是发生在频域上,被称作空间混叠。在视觉影像的模拟数字转换或音乐信号领域,混叠都是相当重要的议题。因为在做模拟-数字转换时若取样频率选取不当将造成高频信号和低频信号混叠在一起,因此无法完美地重建出原始的信号。为了避免此情形发生,取样前必须先做滤波的操作。
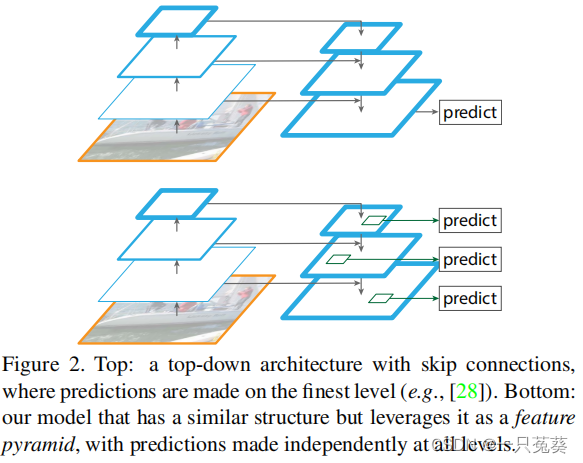
整体结构
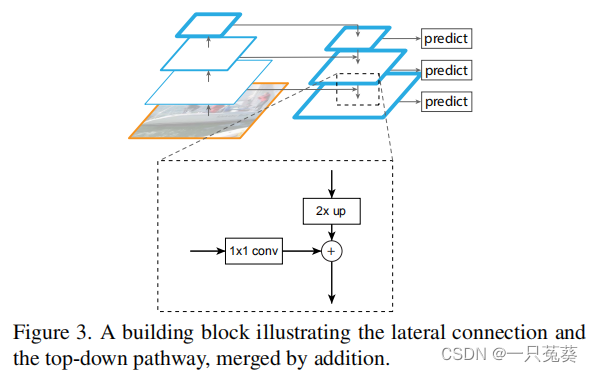
一共包含三个部分:左侧是由原始图像到特征图前向传播的自下而上的过程、右侧是通过上采样对特征图的自上而下的过程、下方是对前两者进行横向连接的过程。
横向连接图中,
1
×
1
1\times 1
1×1的卷积核用于减少通道数,即减少卷积核个数,从而降低运算量。
1 × 1 1 \times 1 1×1卷积核的作用:
0.卷积前后不会改变feature map的大小。
1.降维/升维(跨通道信息交互):通过控制卷积核的数量实现降维/升维,也是通道间信息的线性组合变换。
2.增加网络深度(增加非线性):每使用一次 1 × 1 1 \times 1 1×1卷积核,即增加一层卷积层,所以网络的深度得以增加,卷积过程包含的激活函数则可以增加非线性。
0.4 预热学习策略(Warmup strategy)
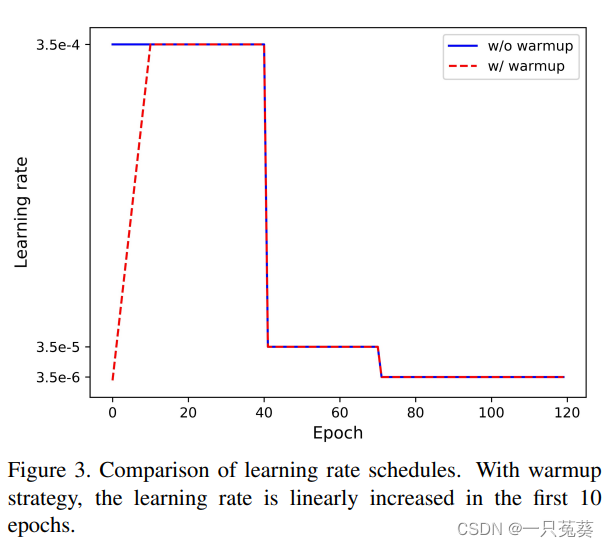
《Bag of tricks and a strong baseline for deep person re-identification》这篇文章给出的一个学习率例子:
学习率对ReID模型的性能有很大的影响,标准Baseline最初以较大且恒定的学习率进行训练,但这样的缺点就是:由于开始时模型对所有数据都很陌生,容易提前过多接触某些数据而陷入“过拟合”,并且在模型训练的后期,如果学习率仍然比较大,会导致模型不稳定。
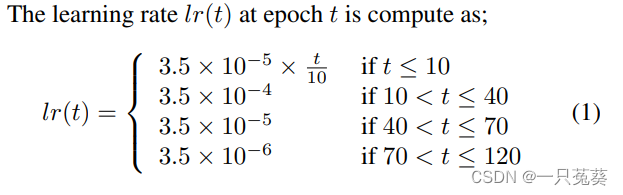
参考博客:
Feature Pyramid Networks for Object Detection

















 466
466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











