







 本文介绍了如何在Titanic数据集中处理缺失值,包括填充Fare和Embarked列,以及使用随机森林回归预测年龄。随后提取了特征如Title、FamilySize等,并将数据集划分为训练集和测试集,最后用随机森林分类器进行模型训练并生成预测结果。
本文介绍了如何在Titanic数据集中处理缺失值,包括填充Fare和Embarked列,以及使用随机森林回归预测年龄。随后提取了特征如Title、FamilySize等,并将数据集划分为训练集和测试集,最后用随机森林分类器进行模型训练并生成预测结果。
流程
- 导入所要使用的包
- 引入kaggle的数据集csv文件
- 查看数据集有无空值
- 填充这些空值
- 提取特征
- 分离训练集和测试集
- 调用模型
导入需要的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
引入kaggle的数据集csv文件
train=pd.read_csv('train.csv')
test=pd.read_csv('test.csv')
datas = pd.concat([train, test], ignore_index = True)
查看数据集有无空值
datas.info()
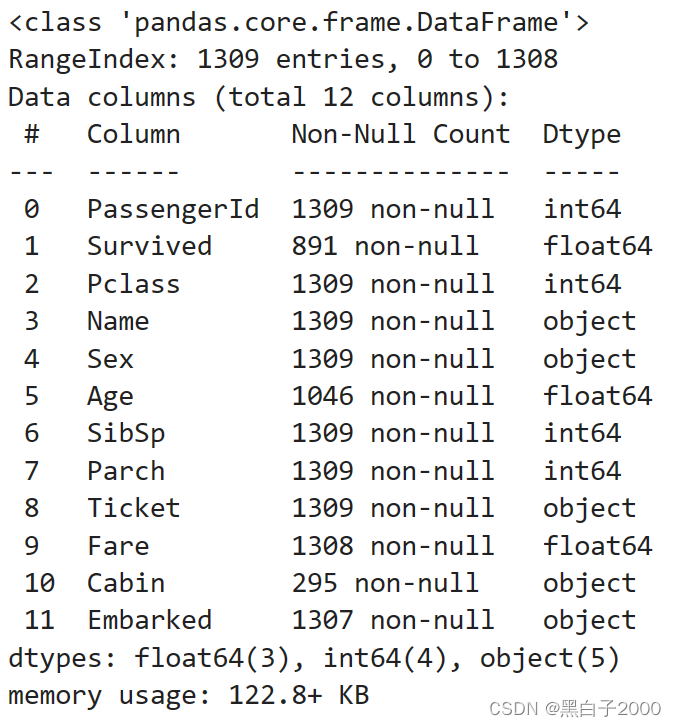
看到了有空值的属性列,Age,Fare,Cabin,Embarked
下面的操作就是给这些空值填充。
填充这些空值
首先填充少的Fare票价少了一行,先看一看这一行的信息
datas[datas['Fare'].isnull()]

已知信息,pclass等级是三类,说明比较贫穷
直接填一个较低的数字就行了
票价就给个差不多7.8好了,就一个数据缺失影响不大
datas['Fare']=datas['Fare'].fillna(7.8)
Embarked少了两行,先看一下这两行的信息
datas[datas['Embarked'].isnull()]

首先二人是女性,根据他们的女士优先的原则,存活概率比较高,pclass也是一级的,所以根据分配给他们三个港口存活率最高的C港口
datas['Embarked'] = datas['Embarked'].fillna('C')
还有Cabin船仓,缺失的很多,干脆把缺失的也归为一类,直接填充为U,然后每个取首字母,得到以字母为编号的船舱信息
空白填充为U
datas['Cabin']=datas['Cabin'] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7240
7240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









