






MOE(Mixture of Experts):
MOE是一种通过专家混合来实现深度学习模型的方法,主要有以下特点:
- MOE由多个专家(Excpert)组成,每个专家是一个独立的神经网络(可以是MLP、CNN、RNN等)
- 输入数据会被路由分配到不同的专家进行处理,目的是确定最适合处理输入的专家模型
- 各个专家独立处理得到的结果进行加权聚合后输入结果
- 各个专家独立计算,容易实现数据并行
- 通过组合不同专家的强项,总体能力优于单个专家
下面是Goole发布的MoE-Conformer关于流式语音识别的一篇文章介绍
https://arxiv.org/abs/2305.15663
MOE-Conformer:
Goole在2023年5月份提出了MOE-conformer流式多语种语音识别模型,MoE层通过将专家网络与Conformer模型结合,实现了对多语种语音的更准确识别。
这种方法提高了模型的容量和泛化能力,使其能够更好地适应不同语种的语音输入。实验相对于基准模型在12种语言实现了平均11.9%的相对词错误率(WER)改进,另外shallow fusion方法在相对词错误率上有约3%的提升。
MOE-Conformer 结构:
简单来说就是在conformer基础上把其中的FNN替换成了Moe层,Moe层由一个路由网络(routing network)和多个专家组成
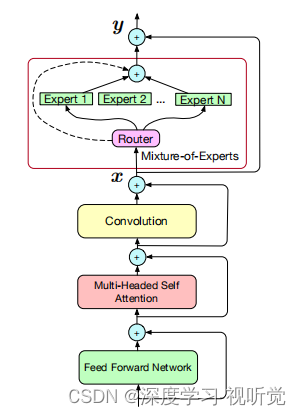
论文中使用RNN-T loss 训练Moe-Conformer,为了确保不同专家之间负载平衡,采用了GShard中相同的辅助损失,其中,mi是在i时刻所有帧中选择不同专家的平均次数,ci是经过top-2计算后得到的分数最高的2个专家,使用每个专家mi(ci/S)的平均作为(ci/S)**2 的近似值。
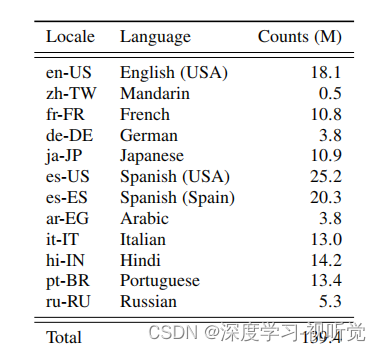
使用的训练数据语种及数量(M为百万)分别如下:















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









