








- 【参考文献】Meng R, Mirchev M, Böhme M, et al. Large language model guided protocol fuzzing[C]//Proceedings of the 31st Annual Network and Distributed System Security Symposium (NDSS). 2024.(CCF A类会议)
- 【注】本文仅为作者个人学习笔记,如有冒犯,请联系作者删除。
目录
3、Case Study: Testing the Capabilities of LLMs for Protocol Fuzzing
3.1、Lifting Message Grammars: Quality and Diversity
3.2、Enriching the Seed Corpus: Diversity and Validity
3.3、Inducing Interesting State Transitions
4.1.2、Mutation based on Grammar
4.3、Surpassing Coverage Plateau
5.4、Experimental Infrastructure
摘要
- 如果没有机器可读的协议规范,如何发现协议实现中的安全漏洞?在一组记录的消息序列上使用变异模糊测试作为种子输入,可以缓解这一挑战。然后,可用种子集合非常有限,并且难以覆盖协议多样性的状态和输入结构。
- 在本文中,我们探讨了系统性地与预训练的大型语言模型 (LLM)进行交互的机会,这些模型已经摄取了数百万页的人类可读协议规范,以提取可用于协议模糊测试的机器可读信息。我们利用LLM对知名协议的消息类型的知识。我们还检查了LLM通过生成消息序列和预测响应码来检测有状态协议实现中‘状态’的能力。
- 基于这些观察,我们开发了一种LLM引导的协议实现模糊测试引擎。我们的协议模糊测试器CHATAFL为协议中的每种消息类型构建语法,然后通过与LLM的交互变异消息或预测消息序列中的下一个消息。
- 对Profuzzbench中的各种实际协议进行的实验显示,在状态和代码覆盖方面显著有效。我们的LLM引导的有状态fuzzers与最先进的模糊测试器AFLNET和NSFUZZ进行了比较。CHATAFL分别覆盖了47.60%和42.69%更多的状态转换,29.55%和25.75%更多的状态,以及5.81%和6.74%更多的代码。除了增强的覆盖率外,CHATAFL在广泛使用和广泛测试的协议实现中发现了九个不同且之前未知的漏洞,而AFLNET和NSFUZZ分别只发现了三个和四个。
1、Introduction
- 查找特定协议状态中的漏洞需要以正确的顺序发送正确的输入。例如,某些协议在交换其他类型的消息之前需要初始化或握手消息。为了让接收方正确解析该消息并进入下一个状态,消息必须遵循特定的格式。然而,默认情况下,我们既不知道这些消息的正确结构,也不知道它们的正确顺序。
- 基于变异的协议fuzzers减少了对所需消息结构或规范的依赖。简单的突变通常会保留所需的协议,但仍然会损坏消息序列,从而暴露错误。然而,基于突变的协议fuzzers的有效性受到记录的种子消息序列的质量和多样性的限制,并且可用的简单突变无助于有效覆盖原本丰富的输入或状态空间。
- 在本文中,我们探讨了利用LLM来指导协议模糊测试过程的实用性。LLM通过互联网网站和文档中的许多TB数据进行训练,最近被证明能够准确回答关于任何主题的特定问题。LLM的近期巨大成功为我们提供了开发一个系统的机会,该系统将协议fuzzers与LLM进行系统交互,其中fuzzers可以向LLM发布非常具体的任务。
- 我们称这种方法为LLM引导的协议模糊测试,并提出了三个具体组件。
- 首先,模糊测试器使用LLM提取协议的机器可读语法,以用于结构感知的变异。
- 其次,模糊测试器使用LLM增加记录消息序列中的消息多样性,这些消息序列用作初始种子。
- 最后,模糊测试器使用LLM打破覆盖率的瓶颈,通过提示LLM生成消息以到达新状态。
- 在我们的消融研究中,从基线开始,我们发现依次启用语法提取 (the grammar extraction)、种子丰富 (the seed enrichment)和饱和处理器 (the saturation handler),使得CHATAFL分别比基线在24小时内实现相同代码覆盖的速度快2.0、4.6和6.1倍。CHATAFL在发现协议实现中的关键安全问题方面非常有效。在我们的实验中,CHATAFL在广泛使用和广泛测试的协议实现中发现了九个不同且之前未知的漏洞。
- 本文贡献如下:
- 我们构建了一个LLM引导的协议实现模糊测试引擎,以克服现有协议模糊测试器的挑战。为了更深入地覆盖这些协议的行为,需要进行即时状态推断——这通过询问LLM(如ChatGPT)关于给定协议的状态机和输入结构来实现。
- 我们提出了将LLM集成到基于变异的协议fuzzers中的三种策略,每种策略都明确解决了协议模糊测试的一个已识别挑战。我们开发了一种扩展的灰盒模糊测试算法,并将其作为原型CHATAFL实现。该工具公开可用,网址为:GitHub - ChatAFLndss/ChatAFL: Large Language Model guided Protocol Fuzzing (NDSS'24)
- 我们进行了实验,结果表明,我们的LLM引导的有状态模糊测试原型CHATAFL在协议状态空间和协议实现代码的覆盖方面,明显优于最先进的AFLNET和NSFUZZ。除了增强的覆盖范围外,CHATAFL在广泛使用的协议实现中发现了九个之前未知的漏洞,其中大部分是AFLNET和NSFUZZ无法找到的。
2、Background and Motivation
2.1、Protocol Fuzzing
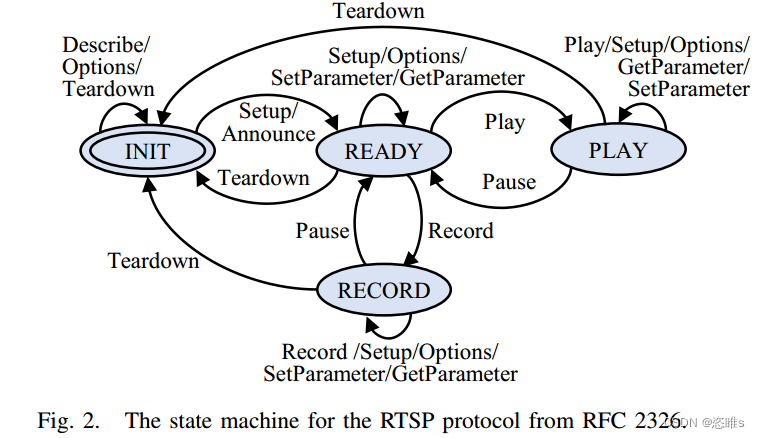
- 协议指定了要交换的消息的一般结构和顺序。图1显示了RTSP消息结构的示例:除了指定消息类型(PLAY)、地址和协议版本的头部外,消息还包括由回车和换行字符(CRLF;\r\n)分隔的键值对(key: value)。
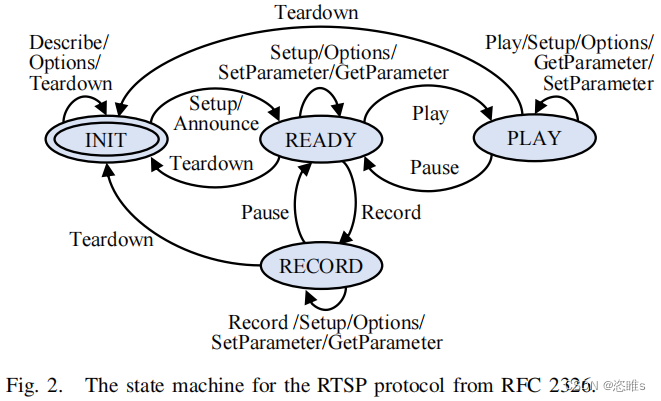
- RTSP消息的顺序要求如图2所示:从INIT状态开始,只有SETUP或ANNOUNCE类型的消息会导致进入新状态(READY)。要从INIT状态到达PLAY状态,至少需要两条特定类型和结构的消息。
- 作为一种最先进的(SOTA)方法,基于突变的协议模糊仍然面临着几个挑战:
- 依赖初始种子:基于突变的协议模糊器的有效性受到所提供的初始种子输入的严重限制。预先记录的消息序列很难涵盖协议规范中讨论的协议状态和输入结构的多样性。
- 未知消息结构:如果没有关于消息结构的机器可读信息,fuzzers就不能对种子消息进行结构上有趣的更改。例如,构造不可见类型的消息,或者删除、替换或添加整个连贯的数据结构到种子消息。
- 未知状态空间:如果没有关于状态空间的机器可读信息,模糊器就不能识别当前状态,也不能被引导去探索以前看不见的状态。

2.2、Large Language Models
- 由于LLM预训练于数十亿的互联网样本,它们应该也能理解不同协议的规范。此外,LLM已经展示了强大的文本生成能力。考虑到消息是在服务器和客户端之间传输的文本格式,为LLM生成消息应该是直截了当的。LLM的这些能力有可能解决基于变异的协议模糊测试的开放挑战。此外,LLM固有的自动化和易用性与模糊测试的设计理念完美契合。
2.3、Motivation
- 在本文中,我们提出使用LLMs来引导协议模糊测试。为缓解对初始种子的依赖(C1),我们建议让LLM向给定的种子消息序列添加随机消息。但这是否真的增加了消息的多样性和有效性?
- 为应对消息结构未知的问题(C2),我们建议让LLM提供每种消息类型的机器可读信息(即语法)。但这些语法与真实情况相比有多好?覆盖了哪些消息类型?
- 为探索未知的状态空间(C3),我们建议让LLM在给定模糊测试器和协议实现之间最近的消息交换的情况下,返回一条可以引导到新状态的消息。但这是否真的有助于我们过渡到新状态?
3、Case Study: Testing the Capabilities of LLMs for Protocol Fuzzing
- 本研究选择了RTSP,以及它在Profuzzbench中的实现live555,并且使用了最新的ChatGPT模型。
3.1、Lifting Message Grammars: Quality and Diversity
- 我们要求LLM提供关于消息结构的机器可读信息(即语法),并评估生成语法的质量以及消息类型覆盖的多样性相对于真实情况的表现。
- 为了建立真实语法,两位作者共花费8小时阅读RFC 2326,并手动和单独提取相应的语法,达成完全一致。最终,我们提取了10种特定于RTSP协议的客户端请求的真实语法,每种请求包含大约2到5个头字段。图3显示了PLAY消息的语法,对应于图1中所示的PLAY客户端请求的语法。PLAY语法包括4个基本头字段:CSeq、User-Agent、Session和Range。
- 此外,某些请求类型具有特定的头字段。例如,Transport字段特定于SETUP请求,Session字段适用于除SETUP和OPTIONS之外的所有类型,而Range字段特定于PLAY、PAUSE和RECORD请求。
- 为了获取LLM的语法进行分析,我们随机抽取了LLM关于RTSP协议的50个回答,并将它们整合成一个答案集。如图4所示,LLM生成了我们预期的所有十种消息类型的语法,这些消息类型出现在超过40个LLM回答中。此外,LLM偶尔生成了2种随机的客户端请求类型,如‘SET DESCRIPTION’,但每种随机类型在我们的答案集中只出现了一次。
- 此外,我们还检查了LLM生成的语法的质量。对于10种消息类型中的9种,LLM生成的语法在所有回答中都与从RFC中提取的真实语法完全相同。唯一的例外是PLAY客户端请求,其中LLM在一些回答中忽略了(可选的)‘Range’字段。进一步检查整个答案集中PLAY语法后,我们发现LLM在35个回答中准确生成了包括‘Range’字段的PLAY语法,但在15个回答中省略了它。这些发现表明,LLM具有生成高度准确的消息语法的能力,这激励我们利用语法来指导变异。
- LLM生成的所有类型RTSP客户端请求的结构信息均为机器可读,并与真实情况相匹配,尽管存在一些随机性。



3.2、Enriching the Seed Corpus: Diversity and Validity
- 我们要求LLM向给定的种子消息序列添加一个随机消息,并评估消息序列的多样性和有效性。
- 在PROFUZZBENCH中,LIVE555的初始种子语料库仅包含10种真实消息类型中的4种客户端请求:DESCRIBE、SETUP、PLAY和TEARDOWN。缺少其余6种客户端请求类型,导致RTSP状态机的很大一部分未被探索,如图2所示。尽管fuzzers有可能生成缺失的6种客户端请求类型,但概率相对较低。为了验证这一观察结果,我们检查了AFLNet和NSfuzz生成的种子,没有生成这些缺失的消息类型。因此,增强初始种子是至关重要的。我们能否利用LLM生成客户端请求并增强初始种子语料库?
- 如果LLM不仅能够生成准确的消息内容,还能将消息插入到客户端请求序列的适当位置,这将是最优的。众所周知,网络协议的服务器通常是有状态的反应系统。此特性决定了客户端请求要被服务器接受,必须满足两个强制条件:(1)它出现在适当的状态中,(2)消息内容是准确的。
- 为了调查LLM的这一能力,我们要求它生成10种类型客户端请求中的每一种类型的10条消息,总共100条客户端请求。随后,我们验证这些客户端请求是否被放置在给定客户端请求序列中的适当位置。为此,我们将它们与图2所示的RTSP状态机进行了比较,因为消息序列应该根据状态机进行转换。一旦我们确保客户端请求的序列在状态机上是准确的,我们将其发送到LIVE555服务器。通过检查服务器返回的响应代码,我们可以确定消息内容是否准确,从而双重检查消息的顺序。
- 为了提升LLM在生成包含正确会话ID的消息时的能力,我们开发了两种方法。当提供额外的上下文信息时,这些方法表现出了显著效果。
- 首先,我们在提示中包含了服务器的响应,然后请求LLM生成相同类型的消息。这时,生成的客户端请求被服务器直接接受。
- 此外,我们尝试将会话ID包括到给定的客户端请求序列中,LLM也准确地将相同的值插入到这些消息中,并生成了正确的结果。
- 由此可见,LLM能够生成准确的消息,并且具备丰富初始种子的能力。
3.3、Inducing Interesting State Transitions
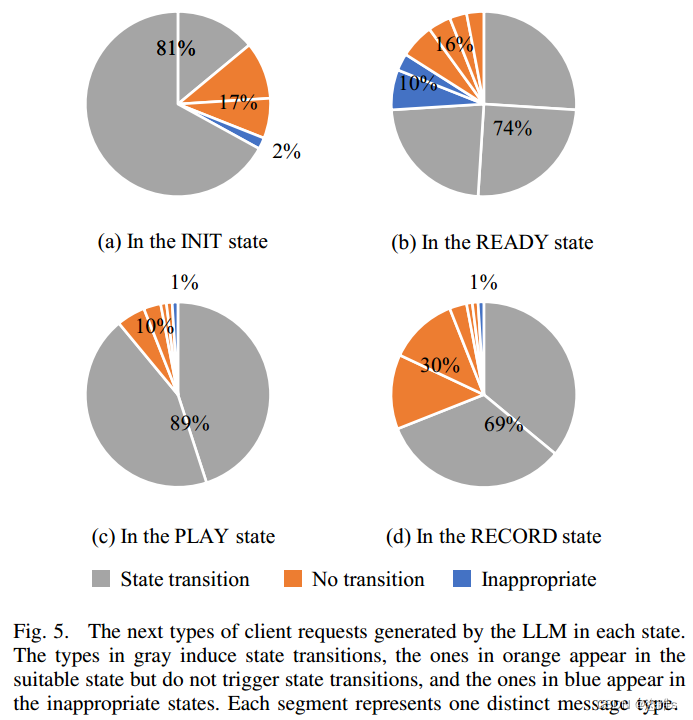
- 我们将fuzzers与协议实现之间的消息交换提供给LLM,并请求它返回一条能够导致新状态的消息。然后评估该消息诱发状态转换的可能性。具体来说,我们向LLM提供现有的通信历史记录,使服务器分别达到每个状态(即INIT、READY、PLAY和RECORD)。然后,我们查询LLM以确定可能影响服务器状态的下一个客户端请求。为了减轻LLM随机行为的影响,我们对每个状态提示LLM100次。
- 图5展示了不同状态的结果。每个饼状图的每个部分表示不同的客户端请求类型。灰色的表示可以导致状态改变的客户端请求类型的百分比。橙色的表示在适当状态中出现但不会触发任何状态转换的消息类型(因此不会发生状态变化)。蓝色的表示在不适当状态中出现并会被服务器直接拒绝的消息类型。
- 这些结果表明LLM具有推断协议状态的能力,尽管偶尔会出现错误。
4、LLM-Guided Protocol Fuzzing
- 基于上述证明的LLM的能力,本文提出LLM-guided protocol fuzzing (LLMPF)来解决现有的基于变异的协议模糊测试 (EMPF)的挑战。
- 算法1,描述传统EMPF方法的一般过程(非灰色区域)。
- 输入为测试P0下的协议服务器,对应的协议p,初始种子池C和总模糊测试时间T。输出包括最终的种子池C和触发服务器崩溃的种子Cx。
- 每次迭代过程中(7~34行),EMPF会选择一个前进的状态s(7行)和执行到s的序列M(8行)来引导fuzzer探索更大的空间。为了确保选择的状态s被执行,M被划分为了3部分(9行):
- M1:到达s的序列。
- M2:选择进行变异的部分。
- M3:剩余的子序列。
- 随后,EMPF为M(10行)分配能量来确定突变时间,将M变异为M’。M‘随后将发送到服务器(23行)。如果M’导致了崩溃(24~25行)或增加了代码或状态覆盖(27~28行),EMPF将保留该序列。如果是后者,它还会更新状态机(29行)。这个过程会一直重复,直到分配的时间结束,之后将选择下一个状态。

- 对于LLMPF,我们通过合并灰色的组件来增强EMPF的基线逻辑。
- 通过提示LLM提取语法(2行),并使用语法来引导变异(12~14行)。
- 请求LLM丰富初始种子(3行)。
- 利用LLM的能力突破覆盖限制(4,19~21,26,30,32行)。
4.1、Grammar-guided Mutation
- 本节介绍从LLM中提取语法,并使用语法来引导结构感知变异。
4.1.1、Grammar-guided Mutation
- 在从LLM中提取语法之前,我们遇到一个紧迫的挑战:如何为fuzzer获得机器可读的语法?
- fuzzer在一台机器上运行,仅限于解析预定的格式。但LLM生成的响应通常是一种相当灵活的自然语言结构。如果fuzzer要理解LLM的响应,那么LLM应该始终以预定的格式回答来自fuzzer的问题。另一种选择包括手动将LLM的响应转换为所需的格式。然而,这种方法会损害fuzzer高度自动化的性质,不太可取。因为,现在的问题是如何使LLM以所需的格式回答问题。
- 常见的方法是对模型进行微调,以实现对特定任务的熟练度。相似地,对于LLM就需要对提示进行微调。这是因为LLM可以通过简单提供自然语言提示来执行特定的任务,而不需要指令。因此,fuzzer提示LLM生成被测协议的消息语法。然而,提示微调的范围是广泛的。
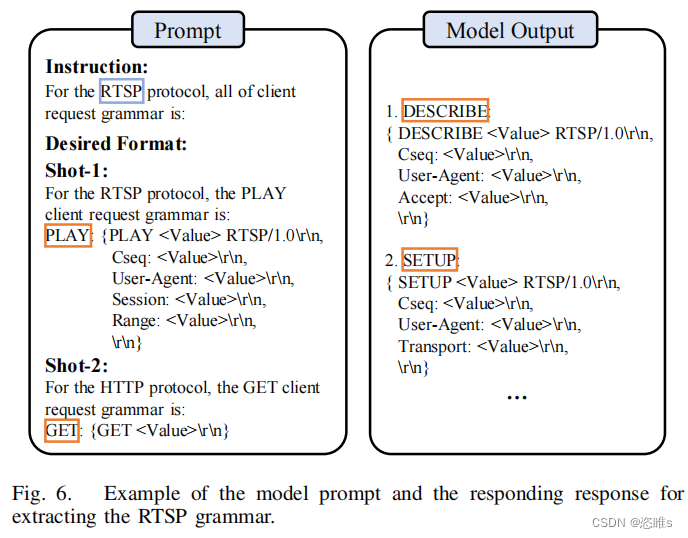
- 为了使LLM生成一个机器可读的语法,我们最终在提示工程领域中使用了in-context few-shot learning。in-context few-shot learning是一种微调模型的有效方法。Few-shot learning被用来增强上下文,通过少量的期望输入和输出的例子。这使得LLM能够识别输入提示的语法和输出模式。通过in-context few-shot learning,我们用几个示例提示LLM以所需的格式提取协议语法。
- 图6展示了提取RTSP语法的模型提示。在该提示中,模糊器以所需格式提供了两种不同协议的两种语法示例。在这种格式中,我们在语法中保留消息关键字,认为它是不可变的,并用“Value”替换可变异区域。请注意,为了指导大型语言模型(LLM)正确生成语法,我们使用了两个示例,而不是仅仅依赖一个示例。这有助于防止LLM严格遵守给定的语法,并可能忽略重要的事实。
- 此外,我们的案例研究揭示了另一个问题:LLM可能偶尔会产生随机答案,如“SET_DESCRIPTION。但这些情况很少见。为了解决这种随机性,我们与LLM进行了多次对话,并将大多数一致的答案作为最终语法。
- 图6中所示的Model Output展示了从LLM中派生出来的部分RTSP语法。在实践中,LLM偶尔对这个提示中的单词“all”不敏感,这导致它们只生成部分语法类型。为了解决这个问题,我们只需再次提示llm询问剩余的语法。
- 在开始fuzzing之前,LLMPF与LLM进行对话,以获得语法。随后,该语法被保存到语法种子池G中,用于结构感知突变。该设计旨在最小化与LLM交互的开销,同时确保最佳的模糊测试性能。
4.1.2、Mutation based on Grammar
- LLMPF利用从LLM中提取的语法种子池,对种子消息序列进行结构化感知变异。在之前的工作中,研究人员通过利用LLM的理解输入语法能力来生成给定输入的变体。但这种方法被与LLM频繁互动的开销所限制。LLMPF利用提取的语法来指导突变。fuzzer只提取一次语法,并在整个模糊测试活动中使用。
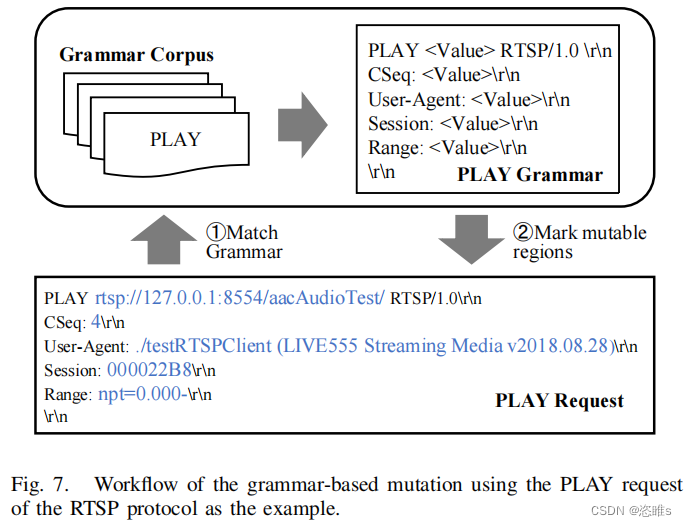
- 在算法1的第9行中,模糊器选择消息部分M2进行突变。假设M2包含多个客户端请求,其中一个是RTSP协议的PLAY客户端请求。由语法指导的突变方法如图7所示,展示了修改一个RTSP PALY客户端请求的工作流程。具体来说,当出现PLAY客户端请求时,LLMPF首先将其与相应的语法进行匹配。为了加快匹配过程,我们将语法语料库保持为映射格式: G = {type → grammar}。使用消息类型,LLMPF将检索相应的语法。随后,我们使用正则表达式将消息中的每个标题字段与语法匹配,标记为“Value”可变区域。图7中标记为蓝色。在突变期间,LLMPF只选择这些区域,以确保消息保留有效的格式。然而,如果没有找到语法匹配,我们认为所有区域都是可变的。
4.2、Enriching Initial Seeds
- 由于LLM能够生成新的消息并将它们插入到所提供的消息序列中的适当位置,我们建议丰富初始种子语料库(算法1的第3行)。然而,我们的方法必须首先解决几个挑战:
- 如何生成携带正确上下文信息的新消息(例如,RTSP协议中正确的会话ID)?
- 如何最大化生成的序列的多样性?
- 如何提示LLM从给定的种子消息序列生成全部修改后的消息序列?
- 对于挑战1,我们发现,LLM可以自动从所提供的消息序列中学习所需的上下文信息。例如,在我们的实验中,ProFuzzBench已经拥有了一些消息序列作为初始种子(尽管它们缺乏多样性)。这些初始种子由被测服务器和客户端之间的网络流量组成。因此,这些初始种子包含了来自服务器的正确和充分的上下文信息。所以,在提示LLM时,我们包含了来自ProFuzzBench的初始种子,以方便获取必要的上下文信息。
- 对于挑战2,fuzzer决定了在初始种子中缺少哪些类型的客户端请求,即LLM应该生成哪些类型的消息来丰富初始种子。回到图6中所示的语法提示符。提示包括消息类型的名称(即,PLAY和GET),相应地,消息名称也包含在模型输出中(例如,DESCRIBE和SETUP)。我们利用这些信息来维护一组消息类型:Alltypes={messageType},以及从语法到对应类型的一个映射:G2T={grammar→type}。在发现缺失的消息类型时,我们首先利用获得的语法语料库G和语法到类型的映射G2T来获取现有的消息类型,并将它们维护到一个集合中(即存在的类型)。然后,我们指示LLM生成缺失的消息类型,并将它们插入到初始种子中;为了避免初始种子过长,我们均匀地向给定的消息序列中添加两种缺失的类型。
- 对于挑战3,为了确保生成的消息序列的有效性,我们将提示设计为延续格式(即“修改后的客户端请求序列为:”)。在实际操作中,获得的响应可以直接用作种子,除了去掉开头的换行符 (\n) 或添加缺失的分隔符 (\r\n) 之外。图 8 提供了一个说明性示例。在该示例中,我们指示大型语言模型(LLM)在给定序列中插入两种类型的消息,“SET PARAMETER”和“TEARDOWN”。修改后的序列显示在右侧。
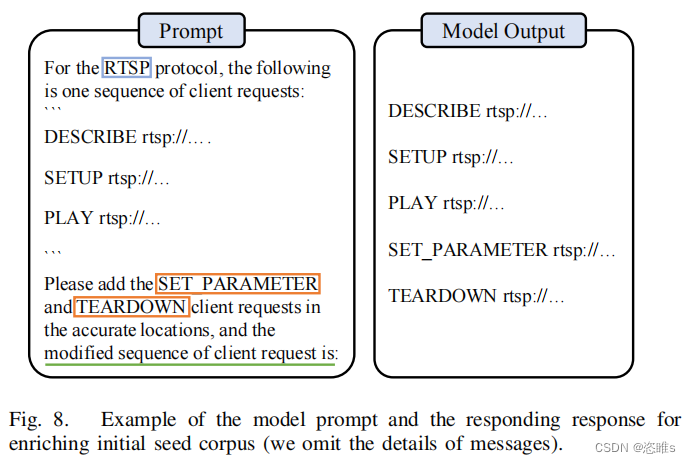
4.3、Surpassing Coverage Plateau
- 对于有状态协议,探索未知的状态是一种挑战。回顾图2所示的RTSP状态机。
- 假设,服务器接收一客户端请求序列后处于状态READY。如果服务器想要转变到不同的状态(例如,PLAY或者RECORD),客户端必须发送对应的PALY或RECORD请求。在模糊测试过程中,fuzzer扮演客户端的角色。虽然模糊器具有生成诱导状态转换的消息的能力,但它需要探索相当数量的种子。fuzzer很有可能无法生成合适的消息顺序来覆盖所需的状态转换。因此,代码空间的相当一部分仍未被探索。所以,为了彻底测试有状态的服务器,探索其他状态是很重要的。不幸的是,完成这个任务对于现有的有状态模糊器来说确实具有挑战性。
- 在本文中,当fuzzer无法探索新的覆盖范围时,我们将此场景称为fuzzer进入覆盖瓶颈 (coverage plateau)。当fuzzer在给定时间内不能生成有趣的种子时,我们使用LLM帮助fuzzer突破覆盖瓶颈。我们根据fuzzer连续生成的无趣种子的数量来量化这个持续时间。具体来说,我们使用一个全局变量PlateauLen来跟踪至今为止生成的无趣种子的数量。在模糊测试开始前,PlateauLen被初始化为0(算法1,4行)。在每次迭代过程中,如果遇到导致崩溃或者覆盖率增加的种子,PlateauLen会重置为0。否则,每遇到一个无趣种子,PlateauLen加1。
- 如果PlateauLen没有超过预先设定的阈值MaxPlateau,LLMPF就使用之前提到的变异策略。用户可以自定义阈值。如果超过了MaxPlateau,LLMPF就会使用LLM来克服覆盖瓶颈(19~21行)。为了实现这一点,我们使用LLM来生成下一个可能导致状态向其他状态转换的合适的客户端请求。提示如图9所示。我们向LLM提供服务器和客户机之间的通信记录,即客户端请求和相应的服务器响应。为了确保LLM生成的是真实的消息,而不是消息类型或描述,我们通过从初始种子语料库中任意提取消息来演示所需的格式。随后,LLM推断当前状态,并生成下一个客户端请求M2‘。这个请求作为原始M2的突变,并被插入到消息序列M‘中,然后将其发送到服务器。
- 重新看向RTSP的例子。最初,服务器处于INIT状态。在接收到消息序列M1 = {SETUP}时,它用R1 = {200-OK}响应,过渡到就绪状态。随后,模糊器遇到了一个覆盖瓶颈,在那里它不能产生有趣的种子。在注意到这一点后,我们通过呈现通信历史H = {SETUP,200-OK}来激活LLM。作为回应,LLM很有可能回复PLKAY或RECORD。这些消息导致服务器转换到一个不同的状态,克服了覆盖瓶颈。

4.4、Implementation
- 本文在AFLNET的基础上实现了LLM引导的协议模糊测试,称为CHATAFL,来测试C/C++编写的协议。AFLNET维护一个推断的状态机,并使用状态和代码反馈来指导模糊测试。当前状态的标识涉及到从服务器的响应消息中解析响应代码。如果种子增加了状态或代码覆盖,它被认为是有趣的。CHATAFL继续利用这种方法,同时将上述三种策略集成到AFLNET框架中。
5、Experimental Design
- 对于LLM解决基于突变的fuzzers对有状态协议进行测试的挑战,为了评估其效用,我们试图回答以下问题:
- State coverage:与baseline相比,CHATAFL实现了多少状态覆盖率?
- Code coverage:与baseline相比,CHATAFL实现了多少代码覆盖率?
- Ablation:每个组件对CHATAFL的性能有什么影响?
- New bugs:CHATAFL对于在广泛使用和广泛测试的协议实现中发现以前未知的错误是否有用?
5.1、Configuration Parameters
- MaxPlateau设置为512。在初步实验中,我们发现512是MaxPlateau的一个合理设置,在大约10分钟内实现。将值设置得太小会导致CHATAFL过度查询LLM,而将其设置得过大将导致CHATAFL停留太久,对我们的优势不利。为了限制LLM提示的成本,我们将MaxPlateau的四分之一设置为无效提示的最大数量。
- 我们使用的LLM为gpt-3.5- turbo,并且temperature设置为0.5来提取语法和丰富初始种子。为了生成新的信息,J. Qiang等人的发现,对于灰盒模糊,1.5的temperature是最佳的。因此,我们将temperature设置为1.5来突破覆盖瓶颈。在提取语法时,对于self-consistency check,我们使用了5次重复,这足以过滤掉错误的情况。
- 【注】temperature参数决定了模型生成文本时的多样性和创造性。
5.2、Benchmark and baselines
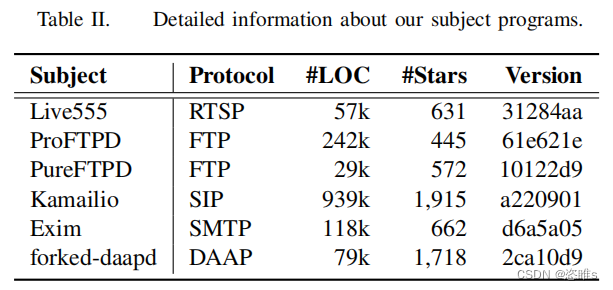
- 表2列出了在我们的评估中使用的目标程序,包括5个广泛使用的网络协议(即RTSP、FTP、SIP、SMTP和DAAP)。这些目标程序集成在ProFuzzBench中。这些协议涵盖了广泛的应用程序,包括流媒体、消息传递和文件传输。这些实现已经成熟,并在企业和个人用户中广泛使用。对于每个协议,我们都选择了流行的、适合在现实应用程序中使用的实现。这些项目中的安全缺陷可能会产生广泛的影响。
- 我们选择了AFLNet工具和NSFuzz-v作为基线工具。由于ChatAFL是基于AFLNET实现的,观察ChatAFL和AFLNet之间的差异,可以归因于我们为实现LLM指导所做的改变。NSFUZZ-v扩展了AFLNET,以更好地处理协议状态空间。它通过静态分析来识别状态变量,并使用状态变量值作为模糊反馈,以最大化状态空间的覆盖范围。
5.3、Variables and Measures
- 为了评估CHATAFL比对基线fuzzers的效率,我们测量了协议模糊器覆盖协议的状态空间和协议实现的代码的程度。然而,覆盖只是模糊的错误发现能力的代理度量。因此,我们用错误发现结果来补充覆盖结果。
- Coverage
- 我们报告了代码和状态空间的覆盖范围。
- 为了评估代码覆盖率,我们使用基准平台PeoFuzzBench提供的自动化工具来实现的分支覆盖率。
- 为了评估状态空间的覆盖范围,我们测量了:
- 不同状态的数量(状态覆盖)和这些状态之间的转换数量(转换覆盖)。
- 为了减轻随机性的影响,我们报告了在24小时内重复10次时所达到的平均覆盖率。
- 我们报告了代码和状态空间的覆盖范围。
- Bugs
- 为了识别bug,我们在Address Sanitizer(ASAN)下执行被测试的程序。ChatAFL存储崩溃的消息序列,然后我们使用AFLNET提供的AFLNet-replay来重现崩溃并调试潜在的原因。我们通过分析ASAN报告的堆栈跟踪来区分不同的bug。最后,我们将这些错误报告给他们各自的开发人员,以供确认。
5.4、Experimental Infrastructure
- XXX
6、Experimental Results
6.1、State coverage
- Transition
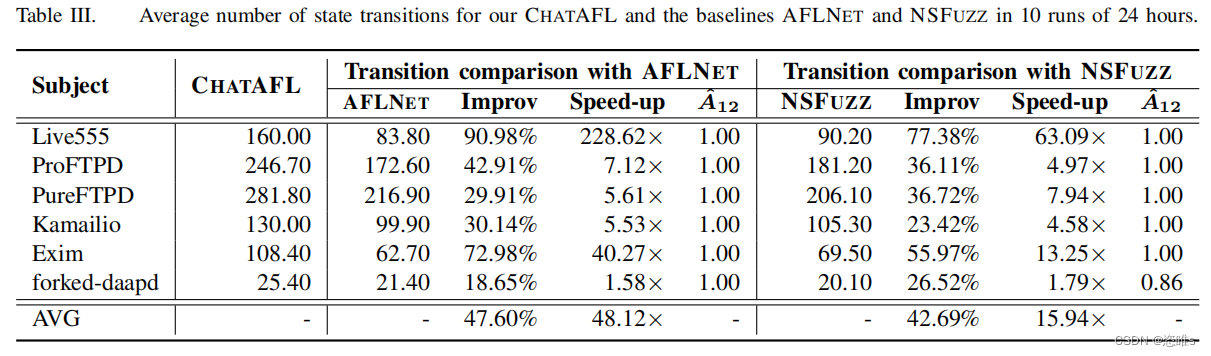
- 表3显示了状态转换的平均数量。A12(Vargha-Delaney)测量效应量是一种用于比较两组独立样本的非参数效应量指标。它主要用于评估两个独立组之间的差异大小,特别是在应用于非正态分布数据或有秩次数据的情况下。
- States
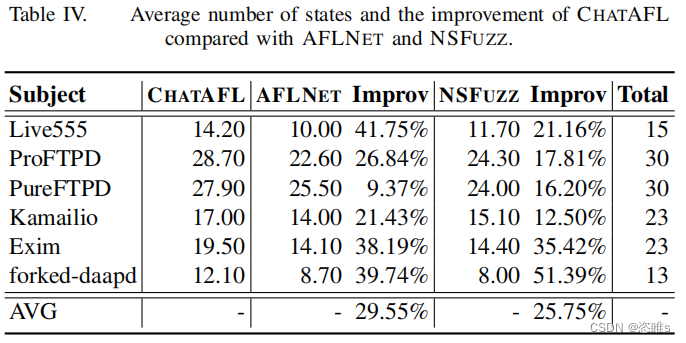
- 表4显示了所覆盖的平均状态。
- 在状态覆盖范围方面,ChatAFL提供的状态转换平均覆盖率分别比AFLNET和NSFUZZ多48%和43%。与baseline相比,CHATAFL覆盖的相同数量的状态转换分别快48倍和16倍。此外,ChatAFL还探索了比AFLNET和NSFUZZ更大的可达状态空间的比例。
6.2、Code coverage
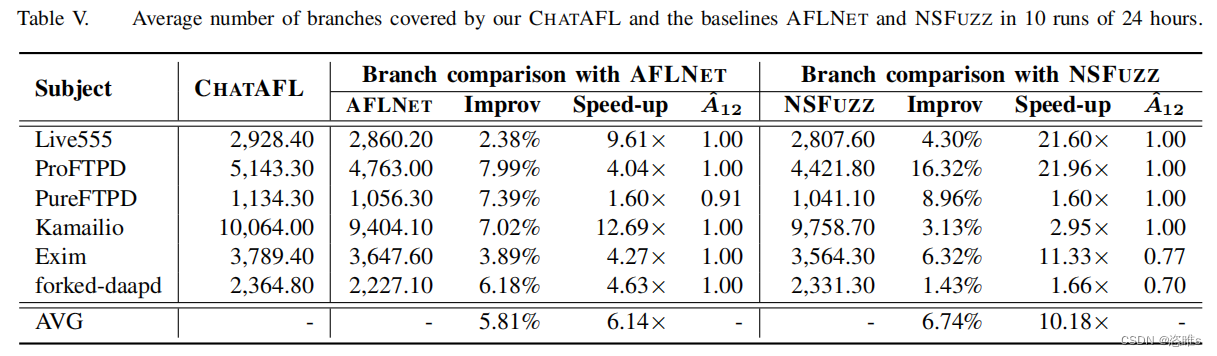
- 表5显示了达到的平均分支数。
- 在代码覆盖率方面,ChatAFL的平均分支覆盖率分别比AFLNET和NSFUZZ多5.8%和6.7%。此外,CHATAFL实现的分支数量分别比AFLNET和NSFUZZ快6倍和10倍。
6.3、Ablation Studies
- CHATAFL实现了三种策略来与LLM交互,以克服协议模糊的挑战:
- 语法引导的突变
- 丰富的初始种子
- 突破覆盖瓶颈
- 为了评估每种策略对增加覆盖率的贡献,我们进行了一项消融研究。为此目的,我们开发了四种工具:
- AFLNET,即所有策略都被禁用。
- AFLNET + 语法引导突变(SA)。
- AFLNET+语法引导突变(SA)和丰富初始种子(SB)。
- AFLNET+所有策略(SA + SB + SC),即ChatAFL。
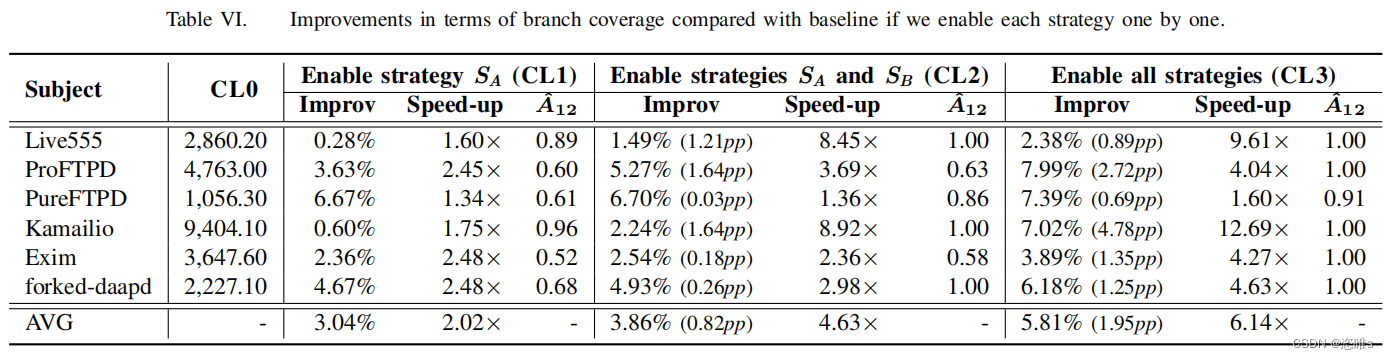
- 表6展示了它们的分支覆盖率结果。
- 总的来说,每一种策略都有助于不同程度的提高分支覆盖率。逐个启用策略SA、SB和SC使我们能够实现相同的分支覆盖率,分别达到快2.0倍、快2.6倍、快4.6倍和6.1倍的速度。
6.4、Discovering New bugs
- 在这个实验中,我们通过检查CHATAFL是否能够在我们的目标程序中发现zero-day错误来评估它的效用。结果如表7所示。

- CHATAFL发现了9个不同的、以前未知的bugs,而AFLNET和NSFUZZ分别只发现了其中的3个和4个。AFLNET和NSFUZZ也没有发现任何额外的错误。9个bug中有7个(7/9)可能是潜在的安全问题。
7、Related Work
- Grammar-based fuzzing
- 基于生成的fuzzers基于手动构建的规范从头开始生成消息。这些规范通常包括数据模型和状态模型。数据模型描述了消息的语法,而状态模型指定了服务器和客户端之间的消息顺序。然而,构建这些规范可能是一项费力的任务,并且需要大量的人力努力。相比之下,大型语言模型是在数十亿个文档上预先训练的,并且拥有关于协议规范的广泛知识。在CHATAFL中,我们直接利用llm来获取规范信息,从而无需进行额外的手工工作。
- Dynamic Message Inference
- 为了减少模糊测试前对先验知识和手动工作的依赖,几个现有工作提出了动态推断消息结构,包括黑盒和灰盒fuzzers。黑盒fuzzers如TreeFuzz,在种子池上使用机器学习技术来构建概率模型,随后用于生成输入。白盒fuzzers如Polyglot,通过对被测系统的动态分析技术来提取消息结构,例如符号执行和污点跟踪。但是,这些方法只能根据观察到的消息来推断消息结构。因此,所推断出的结构可能会明显偏离实际的消息结构。
- Dynamic State Inference
- 基于变异的fuzzers是模糊测试协议实现的最主要方法之一。基于突变的模糊器通过随机突变从种子池中选择的现有种子,生成新的输入,并利用覆盖信息系统地进化该种子池。在分支覆盖反馈的指导下,它们已经被证明模糊测试无状态程序的有效性。
- 然而,当模糊有状态的程序时,分支覆盖本身是一个有用但不足的指标来指导模糊运动,正如在现有工作中阐明的。因此,采用状态覆盖反馈与分支机覆盖一起指导模糊测试工作。然而,分辨状态是一个重要的挑战。一系列工作提出了各种状态表示方案。AFLNET [36]将响应代码作为状态,在模糊活动中构建一个状态机,并将其作为状态覆盖指导。StateAFL、SGFUZZ和NSFUZZ提出了基于程序变量的不同的状态表示方案。在本文中,我们并不试图回答状态是什么。相反,我们将此任务委托给LLM,并允许它推断状态。这种方法已被证明是有效的。
- Fuzzing based on Large Language Models
- 随着预先训练好的大型语言模型在各种自然语言处理任务中取得的显著成功,研究人员一直在探索它们在不同领域的潜力,包括模糊测试。例如,CodaMosa是第一个将llm应用于模糊测试的(即自动生成Python模块的测试用例)。之后,TitanFuzz和FuzzGPT使用LLM自动生成深度学习软件库的测试用例。然而这些工作都是采用了生成的方法来进行模糊测试,ChatFuzz是通过要求LLM修改人类编写的测试用例来进行变异。Ackerman等人利用模糊的格式规范,并使用LLM递归检查自然语言格式规范,生成实例作为基于变异的fuzzers的强种子示例。与这些技术相比,CHATAFL将信息提取与模糊测试技术分离。CHATAFL首先以机器可读的格式(即通过语法和状态机)从LLM中提取关于输入的结构和顺序的信息,然后运行一个包含这些信息的高效fuzzer。为了提高效率,CHATAFL只在模糊过程中覆盖范围饱和时才使用LLM进行突变(类似于ChatFuzz)。
8、Conclusion
- 协议模糊测试是一个固有的难题。与文件处理应用程序相比,它的模糊输入是文件,协议通常是响应系统,涉及系统和环境之间的持续交互。这就提出了两个独立但相关的挑战:
- 为了探索导致崩溃的不常见的深层行为,我们可能需要生成复杂的有效事件序列。
- 由于协议是有状态的,这也隐式地涉及到模糊测试期间的动态状态推断(因为并不是所有的操作都可以在一个状态中启用)。此外,模糊测试的效率很大程度也取决于初始种子的质量,这是模糊测试的基础。
- 在这项工作中,我们已经证明,对于具有公开获得的RFCs的协议,LLMs被证明在丰富初始种子、实现结构感知突变和帮助状态推断方面是有效的。我们在ProFuzzBench提供的广泛协议中评估了CHATAFL。结果表明:与基线工具(baseline tools)相比,CHATAFL覆盖了更多的代码,并在明显更少的时间内探索了更大的状态空间。此外,CHATAFL发现了9个零日(zero-day)漏洞,而基线工具只发现了其中的3到4个。


















 106
106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











