








摘要
对 LLM 增强 RL 中现有文献进行了全面的回顾,并总结了其与传统 RL 方法相比的特征,旨在阐明未来研究的研究范围和方向。利用经典的代理-环境交互范式,我们提出了一种结构化分类法来系统地对RL中llm的功能进行分类,包括四个角色:信息处理器、奖励设计者、决策者和生成器。
INTRODUCTION
概念
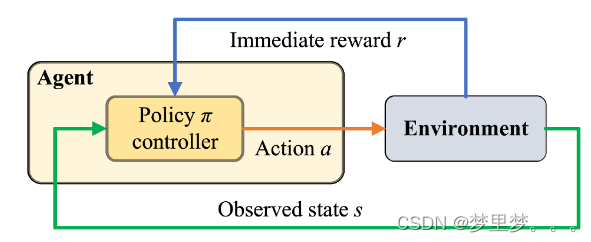
强化学习 (RL) 是一种强大的学习范式,专注于控制和决策,其中代理通过与环境的试错交互来学习优化指定的目标。但是当应用于涉及语言和视觉信息的实际应用中时,深度 RL 算法面临着重大挑战,因为代理必须联合学习特征和控制策略。
目前深度强化学习存在的一些挑战
1、采样效率低下
样本效率低下:深度 RL 代理需要与环境的广泛交互来学习有效的策略,但是对于昂贵或有风险的数据收集场景是不切实际的,实际机器人或无人驾驶收集一些特殊的数据需要付出一定代价(如碰撞的数据等),所以深度强化学习训练机器人一般都是sim2real,而且需要大量的时间来收集熟悉,还需要克服虚拟场景到实际场景的迁移差别性;
2、奖励函数设计
奖励函数设计: 策略学习的性能在很大程度上取决于奖励函数的设计(为什么这样说呢,DRL的本质是将环境状态映射为动作决策量,并使得累积回报值最大化,而累积汇报和每一次的状态-动作对都是相关的,即预先定义的奖励模型,智能体执行一次动作转移到下一个状态,并得到一个奖励值,通过回溯一个eposide的过程得到每一步的回报值)。
而奖励函数需要事先人为设计好,才能让智能体朝着期望的方向去更新深度强化学习的参数,不过这需要大量的人为测试,需要对任务进行深入的理解,进行手动试错(很自然的一个想法:是否需要一个奖励函数模型,让神经网络来拟合一个奖励函数,不断调整,而不是一个固定的分段函数);
第二章背景知识中提到的:在反馈有限的稀疏奖励设置中,奖励塑造对于引导代理走向有意义的行为至关重要;然而,这引入了无意中将代理偏向次优策略或过度拟合特定场景的风险。相反,对于复杂的任务,高性能奖励函数通常需要大量的手动试错,因为大多数设计的奖励是次优的或导致意外的行为。
3、泛化性
泛化性: 深度RL代理的泛化性仍然令人生畏,因为它们经常难以适应新的、看不见的环境,限制了代理在动态现实世界设置中的适用性。
第二章背景知识中提到的:核心问题在于 RL 算法能够将学习到的知识或行为转移到新的、以前未见过的环境中的能力。RL 模型通常在模拟或特定设置中进行训练,在这些场景中表现出色,但在面对新颖或动态条件时难以保持性能。这种限制阻碍
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









