







模型选择
之前介绍了三种模型,他们可以应对不同的问题,因此要用适当的模型解决问题,模型选择对于问题的解决至关重要。
模型的评价
我们在使用深度学习解决问题时会用到三种不同的数据:训练数据、验证数据、测试数据。
训练数据用来训练模型的,让我们的模型能够拟合住我们的训练数据,这个样本通常会大一些。
验证数据是用来验证一下模型的预测准确率的,就是用来检验的,通常不对验证数据训练。
测试数据是一般只用一次,要求测试数据完全没有出现在训练数据中过,而且也绝对不能对测试数据进行训练。
如果验证数据结果还不错,那么就可以使用测试数据来看一下这个模型的好坏了。
拟合
拟合就是说给一堆离散的点,要是能找到一个函数将他们都串联起来,那就是拟合了,相当于找到了这堆数的规律了。
这里引入三种拟合:期望拟合(我自己编的,就是理想下拟合出的结果),过拟合,欠拟合。
当数据不是很复杂的时候,比如具有线性特点的数据,却使用了非常复杂的模型,比如多层的神经网络,那么就会出现过拟合的情况,过拟合的情况会导致训练样本的误差可能会非常非常低,完全的学习到了训练样本的特征,但是一但去跑测试样本,当这个模型见到一个陌生的数据,那么他的误差可能就会很大。
反过来,当数据非常复杂,比如一些非线性的情况,却使用了非常简单的模型,比如最基本的线性回归,那么就会出现欠拟合的情况,就是基本没有学习到训练样本的特征,这样的模型可能误差会非常高。
那么我们所期望得到的模型应该是使用与数据复杂度相配的模型来解决问题。
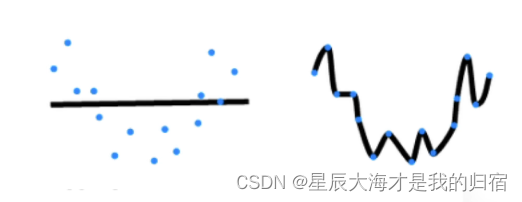
左边就是欠拟合,右边就是过拟合。
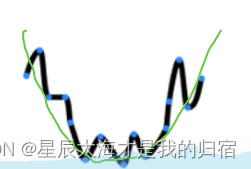
这里的绿线就是比较好的一种拟合了,我们期望得到的结果应该能使测试样本的准确率高,所以牺牲一点训练样本的准确率也是划得来的。















 2548
2548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









