







论文简介:SecureBoost:A Lossless Federated Learning Framework——安全联邦提升树(将XGBoost应用于纵向联邦学习的模型方法)
论文地址:SecureBoost: A Lossless Federated Learning Framework | IEEE Journals & Magazine | IEEE Xplore
目录
一、摘要
用户隐私保护是机器学习中的一个重要问题,2018 年 5 月欧盟 (EU) 推出的通用数据保护条例 (GDPR) 就是一打证据。GDPR 旨在让用户更好地控制个人数据,这促使我们探索隐私保护的数据共享机器学习框架。为了实现这一目标,本文在联邦学习的环境中提出了一种称为 SecureBoost 的新型无损隐私保护的提升树系统。SecureBoost 首先在隐私保护协议下进行实体对齐,然后通过加密策略跨多方构建提升树。这种联合学习系统允许学习过程在多方共同进行,具有共同的用户样本但不同的特征集(纵向联邦学习)。 SecureBoost 的一个优点是它提供了与非隐私保护方法相同的准确性,同时不透露每个私人数据提供者的信息。本文表明,SecureBoost 框架与其他需要集中数据的非联合梯度树增强算法一样准确,因此对于信用风险分析等应用具有高度可扩展性和实用性。同时,本文讨论了协议执行期间的信息泄漏,并提出了可证明减少它的方法。
二、介绍
现代社会越来越关注个人数据的非法使用和利用。 在个人层面,不当使用个人数据可能会对用户隐私造成潜在风险。 在企业层面,数据泄露可能对商业利益造成严重后果。 当前也采取了一些行动, 例如,欧盟颁布了一项称为通用数据保护条例 (GDPR) 的法律,旨在让用户更好地控制他们的个人数据。 在此背景下,许多严重依赖机器学习的企业将不得不进行彻底的改变。
尽管用户隐私保护的目标很难实现,不同组织在构建机器学习模型的同时进行协作的需求仍然很强烈。 实际上,许多数据所有者没有足够的数据量来构建高质量的模型。 例如,零售公司拥有用户的购买和交易数据,如果将其提供给银行进行信用评级应用,这些数据将非常有用。 同样,手机公司也有用户使用数据,但每家公司可能只有少量用户,不足以训练出高质量的用户偏好模型。 这些公司有强烈的动机联合开发出联合数据价值。
到目前为止,让不同的数据所有者协同构建高质量的机器学习模型,同时保护用户数据隐私和机密性仍然是一个挑战。当前已经进行了一些尝试来解决机器学习中的用户隐私问题。例如,Apple 提出使用差分隐私(DP 来解决隐私保护问题。 DP 的基本思想是在数据被第三方交换和分析时,向数据中添加经过适当校准的噪声,以尝试消除个人的可识别性。但是,DP只能在一定程度上防止用户数据泄露,并不能完全排除个人身份。此外,DP 下的数据交换仍然需要数据在组织之间转手,这可能是 GDPR 等严格法律所不允许的。此外,DP 方法在机器学习中是有损的,因为在注入噪声后建立的模型可能在预测精度上表现不令人满意。
最近,谷歌引入了联邦学习 (FL) 框架并将其部署在 Android 云上。 基本思想是允许单个客户端仅将模型更新到聚合模型的中央服务器,而不是将原始数据上传。 谷歌进一步引入了安全聚合协议,以确保模型参数不会将用户信息泄漏到服务器。 该框架也称为横向联邦=或数据分区联邦,其中每个分区对应于从一个或多个用户收集的数据样本的子集。
本文考虑了另一种情况,即多方协作构建他们的机器学习模型,同时保护用户和数据隐私。 我们的设置如图 2 所示,因为数据是按不同方之间的特征划分的,此场景通常被称为纵向联邦。 此设置具有广泛的实际应用。 例如,金融机构可以利用第三方的替代数据来提高用户和中小企业的信用评级。 来自多家医院的专利记录可以一起用于诊断。 我们可以将位于不同方的数据看作是对不同方的所有数据进行并集得到的虚拟大数据表的一个子集。
不同参与方的数据拥有以下性质:
- 大数据表是垂直分割的,或者说按特征分割的;
- 只有 data provider 有 label 信息;
- 有一些用户是被所有参与方所共同拥有的。
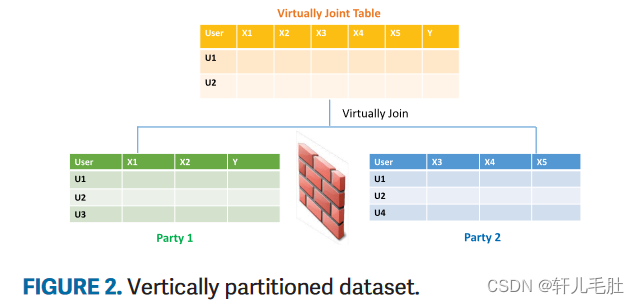
我们的目标是让各方共同构建预测模型,同时保护各方不将数据信息泄露给其他方。 与大多数现有的隐私保护数据挖掘和机器学习工作相比,我们设置的复杂性显着增加。 与横向联邦不同,纵向联邦设置需要更复杂的机制来分解每一方的损失函数。 此外,由于只有一个数据提供者拥有标签信息,我们需要提出一种安全协议来指导学习过程,而不是在各方之间明确共享标签信息。 最后,数据机密性和隐私问题防止各方暴露自己的用户。 因此,实体对齐也应该以足够安全的方式进行。
提升树(Boosting Tree)是一种高效且应用广泛的机器学习方法,由于其高效性和可解释性强,在许多机器学习任务中表现出色。例如,XGBoost 已广泛用于各种应用,包括信用风险分析和用户行为研究。在本文中,我们提出了一种新颖的端到端隐私保护提升树算法框架,称为 SecureBoost,以在联邦环境中实现机器学习。Secureboost 已在开源项目 FATE 中实施,以支持工业应用。我们的联邦学习框架分两步运行。首先,我们在隐私保护约束下找到各方之间的共同用户。然后,我们协作学习共享分类或回归模型,而不会相互泄露任何用户信息。本文的主要贡献总结如下:
- 我们正式定义了在联邦学习设置中对垂直分区数据进行隐私保护机器学习的新问题(纵向联邦)。
- 我们提出了一种协同训练高质量提升树模型的方法,同时将训练数据保持在多方的本地。我们的协议不需要受信任的第三方的参与。
- 我们证明了我们的方法是无损的,因为它与任何将所有数据集中到一个中心位置的集中式非隐私保护方法一样准确。
- 此外,除了安全证明之外,我们还讨论了使协议完全安全所需的条件。
三、背景知识&相关工作
为了保护模型训练中数据的隐私,论文[18]提出利用差分隐私 (DP) 来学习深度学习模型。 最近,谷歌引入了一个联邦学习框架,通过在
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1235
1235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











