







我们将网络流量分类的输入空间分为三类:分组分类(Packet Classification,PC)、流量内容分类(Flow Content Classification,FCC)和流量时间序列分类(Flow Time Series Classification,FTSC)。
按照流量内容进行分类,是将一个流的前n个数据包的字节序列提取出来。
网络流量由双向流和数据包组成,它们是网络流量分类的常用对象。每个数据包由多个报头文件和一个存在应用程序数据的有效负载组成。我们通过5元组信息来表示一个数据包的报头,这些信息来自于IP层和传输层(TL)报头的内容。五元组包括网络传输协议、源IP、目的IP、源端口、目的端口。网络协议号可以参考这个网址 协议号大全,其中最主要的有TCP为06,UDP为17,拿一条流量举例:
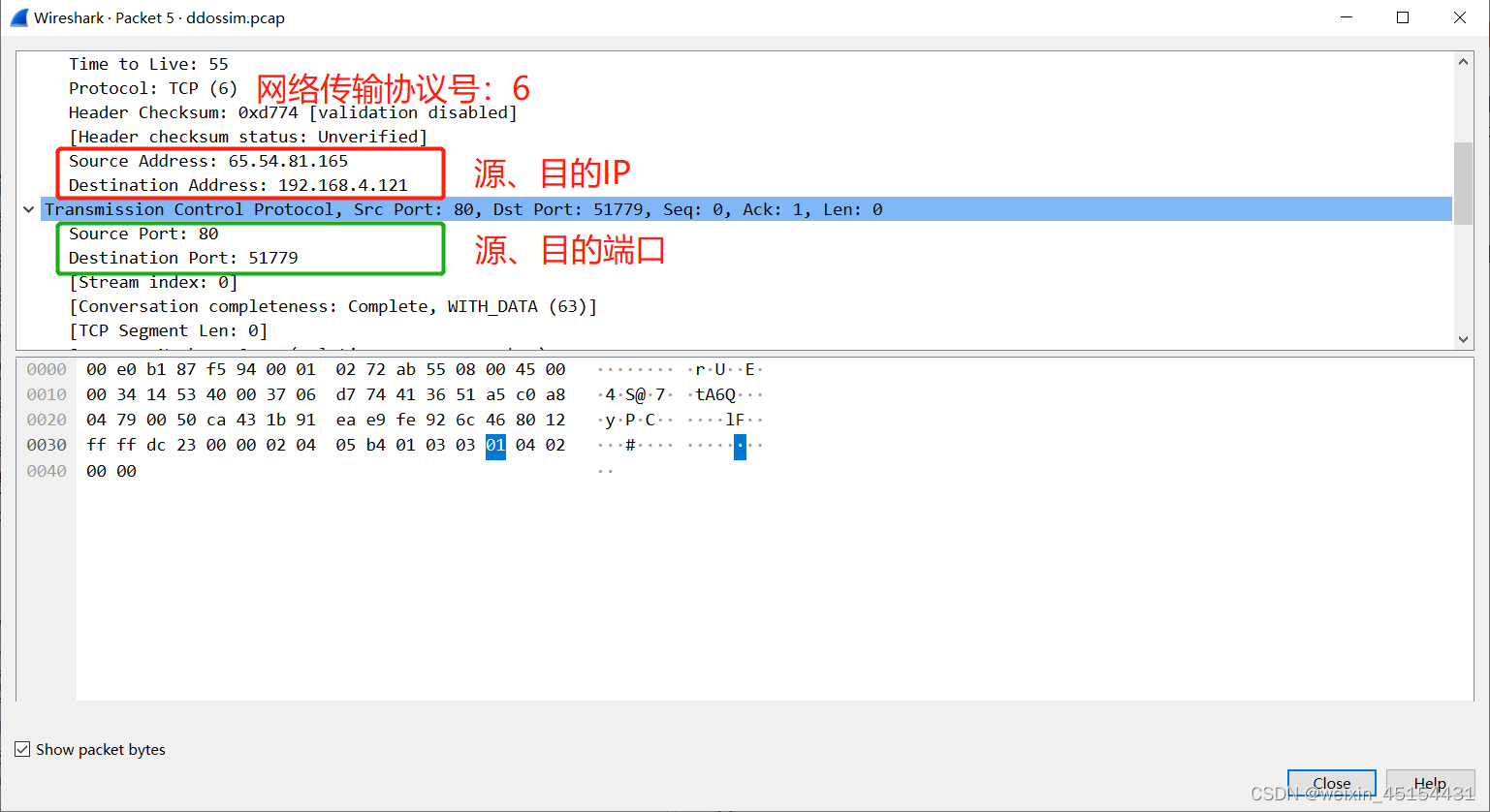
其中网络传输协议为TCP,协议号为6,源IP为65.54.81.165,目的IP为192.168.4.121,源端口为80,目的端口为51779。
因此具有相同五元组的所有流量均被提取(在此,采用双向流,即为源与目的交换后仍代表相同五元组,但在最终采用+1/-1来表示流向)。
代码如下:
import scapy
from scapy.all import *
from scapy.utils import PcapReader
import binascii
import struct
import numpy as np
fpcap = open("ddossim.pcap",'rb')
string_data = fpcap.read()
packets=rdpcap("ddossim.pcap")
np.set_printoptions(threshold=np.inf)
#pcap文件的数据包解析
step = 0
packet_num = 0
packet_data = []
pcap_packet_header = []
i =24
packet_num_w=0
packet_content=[]
five_tuples=[]
five_tuples_num=0
for data in packets:
packet_num_w+=1
if 'UDP' in data and data['UDP'].len!=97:
payload_len=data['UDP'].len-8
elif 'TCP' in data and data['IP'].len>40:
payload_len=data['IP'].len-40
else:
i = i+ struct.unpack('I',string_data[i+12:i+16])[0]+16
continue
packet_header=binascii.hexlify(string_data[i:i+16])
pcap_packet_header.append(packet_header)
#求出此包的包长len
pcap_packet_header_len = string_data[i+12:i+16]
packet_len = struct.unpack('I',pcap_packet_header_len)[0]
#写入此包数据
pcap_packet_payload=binascii.hexlify(string_data[i+16:i+16+packet_len])
protocol=[int(pcap_packet_payload[i*2:(i+1)*2],16) for i in range(23,24)][0]
src_ip=[int(pcap_packet_payload[i*2:(i+1)*2],16) for i in range(26,30)]
src_ip=str(src_ip[0])+'.'+str(src_ip[1])+'.'+str(src_ip[2])+'.'+str(src_ip[3])
dst_ip=[int(pcap_packet_payload[i*2:(i+1)*2],16) for i in range(30,34)]
dst_ip=str(dst_ip[0])+'.'+str(dst_ip[1])+'.'+str(dst_ip[2])+'.'+str(dst_ip[3])
src_port=[int(pcap_packet_payload[i*2:(i+2)*2],16) for i in range(34,35)][0]
dst_port=[int(pcap_packet_payload[i*2:(i+2)*2],16) for i in range(36,37)][0]
five_tuple=[protocol,src_ip,dst_ip,src_port,dst_port]
five_tuple_trans=[five_tuple[0],five_tuple[2],five_tuple[1],five_tuple[4],five_tuple[3]]
packet_data.append(pcap_packet_payload)
payload = str(pcap_packet_payload[-payload_len*2:])[2:-1]
header = str(pcap_packet_payload[:-payload_len*2])[2:-1]
header_256 = []
payload_256 = []
# import pdb;pdb.set_trace()
for header_len_each in range(packet_len-int(payload_len)):
header_256_each=int(header[header_len_each*2:header_len_each*2+2],16)
header_256.append(header_256_each)
for payload_len_each in range(int(payload_len)):
payload_256_each=int(payload[payload_len_each*2:payload_len_each*2+2],16)
payload_256.append(payload_256_each)
header_256 = np.array(header_256)
payload_256 = np.array(payload_256)
new_tuple=0
for tuple_num in range(0,len(packet_content)):
if packet_content[tuple_num][0]==five_tuple:
packet_content[tuple_num][1].append(1)
packet_content[tuple_num].append(header_256)
packet_content[tuple_num].append(payload_256)
new_tuple=1
elif packet_content[tuple_num][0]==five_tuple_trans:
packet_content[tuple_num][1].append(-1)
packet_content[tuple_num].append(header_256)
packet_content[tuple_num].append(payload_256)
new_tuple=1
if new_tuple==0:
five_tuples_num+=1
packet_content.append([five_tuple])
packet_content[-1].append([1])
packet_content[-1].append(header_256)
packet_content[-1].append(payload_256)
i = i+ packet_len+16
packet_num+=1
fpcap.close()
np.savetxt("temp0.csv", packet_content, delimiter="," , fmt = '%s')
其中 packet_content为存储最终结果的变量,five_tuple为五元组集合,five_tuple_trans为双向流另一种五元组集合(即为与第一个五元组方向不同的流的五元组),five_tuples_num为五元组组数,header_256与payload_256分别为各包包头及负载。
提取单个包的包头与负载代码入口在此:Pcap包包头、负载解析
提取五元组后的存储文件如下:
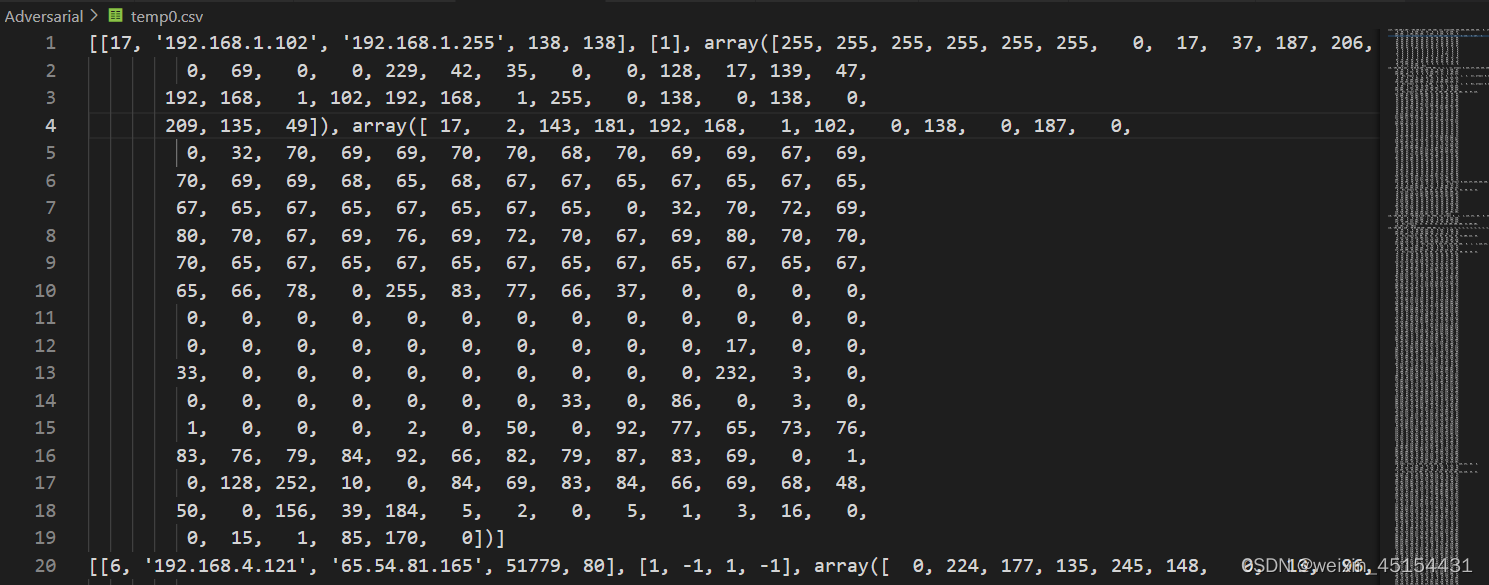
存储格式为: [五元组][每个流方向][每个流的包头及负载数据]
写入csv文件后,可采用一下代码进行读取:
ort numpy as np
import csv
# np.set_printoptions(threshold=np.inf)
with open('temp0.csv') as f:
f_csv=csv.reader(f)
t=""
for csv in f_csv:
for csv_each in csv:
t=t+str(csv_each)
t=t[1:-1]
m=t.split("][")
five_tuple_all=[]
flow_direction_all=[]
data=[]
for tuple_count in range(len(m)):
five_tuple=m[tuple_count].split("] [")[0].replace('[','').split(" ")
five_tuple_all.append(five_tuple)
flow_direction=m[tuple_count].split("] [")[1].split("] array")[0].split(" ")
flow_direction_all.append(flow_direction)
flow_data=m[tuple_count].split("] [")[1].split("] array")[1].replace('([','').replace('])','').split('array')
flow_num=len(flow_direction)
for i in range(flow_num*2):
each_pcap=[]
for bit_count in flow_data[i].split(' '):
try:
each_pcap.append(eval(bit_count))
except SyntaxError:
continue
each_pcap=np.array(each_pcap)
# import pdb;pdb.set_trace()
if i==0:
data.append([[each_pcap]])
elif i%2==0:
data[tuple_count].append([each_pcap])
else:
data[tuple_count][int((i-1)/2)].append(each_pcap)
data=np.array(data)














 1059
1059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









