







机器学习概述
1:人工智能概述
1.1 人工智能应用场景

1.2 人工智能案例
⽹络安全、电⼦商务、计算模拟、社交⽹络 … …


1.3⼈⼯智能、机器学习和深度学习

机器学习是⼈⼯智能的⼀个实现途径
深度学习是机器学习的⼀个⽅法发展⽽来
2 机器学习开发流程
2.1 什么是机器学习
机器学习是从数据中⾃动分析获得模型,并利⽤模型对未知数据进⾏预测

2.2 机器学习流程

2.2.1 数据集介绍

*在数据集中⼀般:
⼀⾏数据我们称为⼀个样本
⼀列数据我们成为⼀个特征
有些数据有⽬标值(标签值),有些数据没有⽬标值(如上表中,电影类型就是这个数据集的
⽬标值)
*数据类型构成:
数据类型⼀:特征值+⽬标值(⽬标值是连续的和离散的)
数据类型⼆:只有特征值,没有⽬标值
*数据分割:
机器学习⼀般的数据集会划分为两个部分:
训练数据:⽤于训练,构建模型
测试数据:在模型检验时使⽤,⽤于评估模型是否有效
*划分⽐例:
训练集:70% 80% 75%
测试集:30% 20% 25%
2.2.2 数据基本处理
即对数据进⾏缺失值、去除异常值等处理
2.2.3 特征⼯程
2.2.3.1 什么是特征⼯程
特征⼯程是使⽤专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作⽤的过程。
2.2.3.2 为什么需要特征⼯程(Feature Engineering)
机器学习领域的⼤神Andrew Ng(吴恩达)⽼师说“Coming up with features is difficult, timeconsuming, requires expert knowledge. “Applied machine learning” is basically feature
engineering. ”
注:业界⼴泛流传:数据和特征决定了机器学习的上限,⽽模型和算法只是逼近这个上限⽽已。
2.2.3.3 特征⼯程包括
特征提取,特征预处理,特征降维
eg:
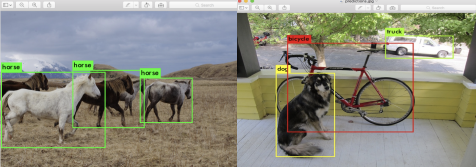
特征提取:
特征预处理
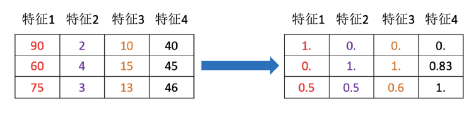
特征降维
指在某些限定条件下,降低随机变量(特征)个数,得到⼀组“不相关”主变量的过程
3:机器学习算法分类
根据数据集组成不同,可以把机器学习算法分为:
1.监督学习
2.⽆监督学习
3.半监督学习
4.强化学习
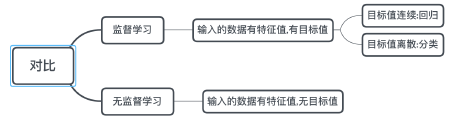
3.1监督学习
定义:
输⼊数据是由输⼊特征值和⽬标值所组成。
函数的输出可以是⼀个连续的值(称为回归),
或是输出是有限个离散值(称作分类)。
3.1.1回归问题(连续,eg:时间序列)
例如:预测房价,根据样本集拟合出⼀条连续曲线。

3.1.2分类问题(什么种类)

3.2无监督学习
定义:
输⼊数据是由输⼊特征值组成,没有⽬标值
输⼊数据没有被标记,也没有确定的结果。样本数据类别未知;
需要根据样本间的相似性对样本集进⾏类别划分。

3.3半监督学习
定义:
介于监督学习和⽆监督学习之间的⼀类算法
当⼤量数据没有标签,只有少部分数据有标签的情况下, ⽐较适合使⽤半监督学习

实际⼯作中,很多业务场景获得真实标签的代价⾼昂,⼤部分数据⽆标签少部分数据有标签的
情况经常发⽣,如⾦融反欺诈:
只有少量数据是有标签的——被证实了确实是欺诈,给公司带来了损失
⼤部分数据是没有标签的——不知道是不是欺诈
半监督学习使我们能够处理上述场景的数据集,⽽不必在监督学习或⽆监督学习之间纠结
半监督学习基本原理
半监督的机器学习算法使⽤⼀组有限的标记样本数据进⾏⾃我训练,从⽽形成“部分训练”的模
型
经过部分训练的模型会为⽆标签的数据打标签, 此标签结果被视为“伪标签”数据
标记和伪标记的数据集组合到⼀起进⼀步训练模型,得到最终的预测结果
强化学习:
强化学习算法的思路⾮常简单,以游戏为例,如果在游戏中采取某种策略可以取得较⾼的得
分,那么就进⼀步「强化」这种策略,以期继续取得较好的结果。这种策略与⽇常⽣活中的各
种「绩效奖励」⾮常类似。我们平时也常常⽤这样的策略来提⾼⾃⼰的游戏⽔平
在 Flappy bird 这个游戏中,我们需要简单的点击操作来控制⼩⻦,躲过各种⽔管,⻜的越远
越好,因为⻜的越远就能获得更⾼的积分奖励。
这就是⼀个典型的强化学习场景:
机器有⼀个明确的⼩⻦⻆⾊——代理
需要控制⼩⻦⻜的更远——⽬标
整个游戏过程中需要躲避各种⽔管——环境
躲避⽔管的⽅法是让⼩⻦⽤⼒⻜⼀下——⾏动
⻜的越远,就会获得越多的积分——奖励
强化学习和监督学习、⽆监督学习最⼤的不同就是不需要⼤量的“数据喂养”。⽽是通过⾃⼰不
停的尝试来学会某些技能
强化学习在游戏,机器⼈等领域应⽤⽐较⼴泛,最近在推荐系统,计算⼴告,对话系统等领域
中也有应⽤

4: 模型评估
4.1 分类模型评估
准确率
预测正确的数占样本总数的⽐例。
其他评价指标:精确率、召回率、F1-score、AUC指标等
4.2 回归模型评估
均⽅根误差(Root Mean Squared Error,RMSE)
RMSE是⼀个衡量回归模型误差率的常⽤公式。 不过,它仅能⽐较误差是相同单位的模型。
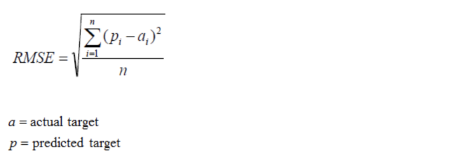
假设上⾯的房价预测,只有五个样本
对应的真实值为:100,120,125,230,400
预测值为:105,119,120,230,410
那么使⽤均⽅根误差求解得:
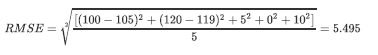
其他评价指标:
相对平⽅误差(Relative Squared Error,RSE)、
平均绝对误差(Mean Absolute Error,MAE)、
相对绝对误差(Relative Absolute Error,RAE)
4.3 拟合
模型评估⽤于评价训练好的的模型的表现效果,其表现效果⼤致可以分为两类:过拟合、⽋拟合。在训练过程中,你可能会遇到如下问题:
训练数据训练的很好啊,误差也不⼤,为什么在测试集上⾯有问题呢?
当算法在某个数据集当中出现这种情况,可能就出现了拟合问题。
4.3.1 ⽋拟合

因为机器学习到的天鹅特征太少了,导致区分标准太粗糙,不能准确识别出天鹅。
⽋拟合(under-fitting):模型学习的太过粗糙,连训练集中的样本数据特征关系都没有学出来。
4.3.2 过拟合

机器已经基本能区别天鹅和其他动物了。然后,很不巧已有的天鹅图⽚全是⽩天鹅的,于是机器经过学习后,会认为天鹅的⽻⽑都是⽩的,以后看到⽻⽑是⿊的天鹅就会认为那不是天鹅。
过拟合(over-fitting):所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在测试数据集中表现不佳。
4.4 ⼩结
分类模型评估:
准确率
回归模型评估:
RMSE – 均⽅根误差
拟合:
举例 – 判断是否是天鹅
⽋拟合:
学习到的东⻄太少,模型学习的太过粗糙
过拟合:
学习到的东⻄太多,学习到的特征多,不好泛化
5: 数据分析与机器学习

*Excel, SQL,Python, BI⼯具可以帮助我们完成描述性分析和诊断分析
*预测分析需要⽤到机器学习算法, 来进⾏预测性分析, 提⾼数据分析⼯作效率:
预测⽤户会不会违约
为海量⽤户分群, 进⾏个性化运营
判断哪些流量是异常流量(刷单,作弊)
为⽤户筛选更感兴趣的推送内容
*⽬前阶段我们的学习重点是机器学习算法的使⽤
利⽤已有机器学习算法解决业务问题, ⽽不是去创造新算法















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









