







目录
前言:
使用线性模型进行分类任务,找到一个单调可微函数将分类任务的真实标记y与线性回归模型的预测值联系起来。
对数几率回归:
对数几率函数(logistic function):对数几率函数是sigmoid函数的一种

把线性模型代入对数几率函数得到下式:
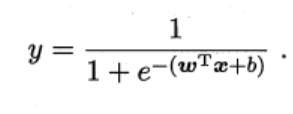 转换得
转换得 
通过极大似然估计法来估计参数w,b。损失函数如3.27所示。其中=(w,b),
==(x,1)。矩阵相乘正好为y的值。


编程:
用到的函数:
1.np.insert(arr, obj, values, axis=None)
2.reshape(-1, 1)
3.np.sum(a, axis=None, dtype=None, out=None, keepdims=np._NoValue, initial=np._NoValue)
# 精简版梯度下降算法:
#1.读取数据
#2.使用梯度下降得到beta
#3,是得到的beta参数,得到预测值,把预测的值和标签值进行比较
dataSet = np.array([
[0.697, 0.460, 1],
[0.774, 0.376, 1],
[0.634, 0.264, 1],
[0.608, 0.318, 1],
[0.556, 0.215, 1],
[0.403, 0.237, 1],
[0.481, 0.149, 1],
[0.437, 0.211, 1],
[0.666, 0.091, 0],
[0.243, 0.267, 0],
[0.245, 0.057, 0],
[0.343, 0.099, 0],
[0.639, 0.161, 0],
[0.657, 0.198, 0],
[0.360, 0.370, 0],
[0.593, 0.042, 0],
[0.719, 0.103, 0]
])
#在数据中插入1
dataSet = np.insert(dataSet, 0,
np.ones(dataSet.shape[0]),
axis=1)
#分离出前3列,即数据x的值
dataArr = dataSet[:, :-1]
#分离出最后1列,即标签的值
labelArr = dataSet[:, -1].reshape(-1,1)
#定义beta的形状:3行1列
beta = np.ones((3, 1))
#开始200次迭代
for a in range(200):
#y的值:(17,3)dot(3,1)———(17,1)
a=np.dot(dataArr, beta)
#把y的值送到sigmoid函数:(17,1)——(17,1)
b=1.0 / (1 + np.exp(-a))
#得到偏导数的值:(17,3)*(17,1)——(17,3)
dBetaMat = -dataArr * (labelArr - b)
#把每个x的值进行求和:(17,3)——(1,3)
#sum函数参数:axis=0表示行压缩,即保持列数不变,一个列行的所有行加起来。keepdim=true表示保持原来的维数不变。
dBeta = np.sum(dBetaMat, axis=0,keepdims=True)
#根据学习率进行相减
beta -= 0.005 * dBeta.T
#得到新的beta参数值,通过新的beta参数值预测y的值
preArr = sigmoid(np.dot(dataArr, beta))
preArr[preArr > 0.5] = 1
preArr[preArr <= 0.5] = 0
m = len(preArr)
cnt = 0.0
for i in range(m):
if preArr[i] != labelArr[i]:
cnt += 1.0
error=cnt / float(m)
error![]()















 1916
1916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









