







mindspore-yolov5的训练、改进及MindConverter的使用
YOLO系列的目标检测算法发展迅速,yolov5在v4的基础上增加了一些训练的小tricks使得精度进一步提升,此次实验训练mindspore框架下的yolov5并进行简单的改进
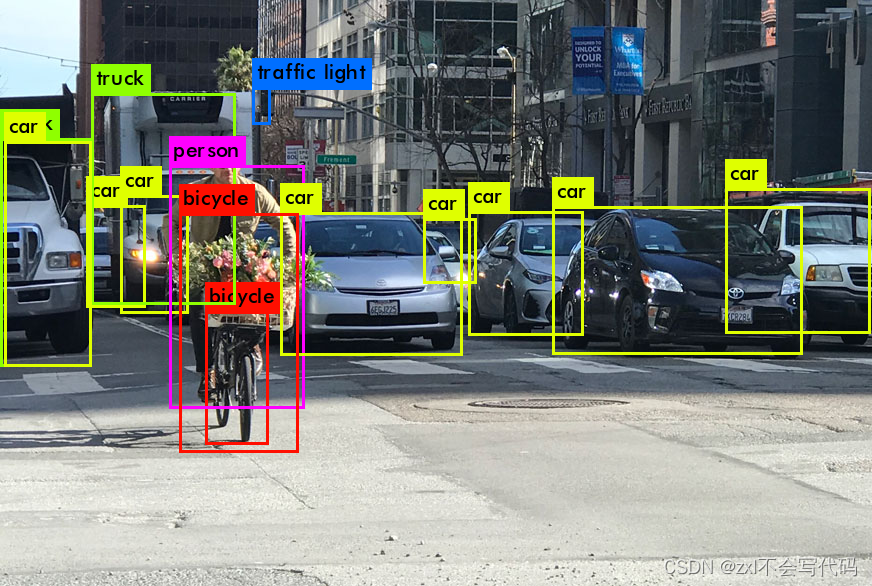
目标检测
目标检测主要解决两个问题:
1.判定图像上有哪些目标物体,解决目标物体存在性的问题;
2.判定图像中目标物体的具体位置,解决目标物体在哪里的问题。
训练环境
mindspore-gpu=1.5.0
liunx操作系统
准备
获取官方的yolov5代码 链接: https://gitee.com/mindspore/models/tree/master/official/cv/yolov5
各个领域经典算法官方都给出了复现的代码,直接通过华为modelzoo获取
数据集准备 ,数据集的格式如下:
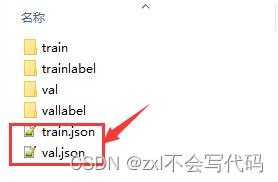
包含:训练图像数据,验证图像,以及两个json文件,至于如何制作这样的数据集,网上教程及代码很多可以参考
开始训练
在制作好数据集后,需要在default_config .yaml文件中修改数据集路径,预训练模型,yolov5的模式,类别数
修改好配置文件后执行下面命令
#run training example(1p) by python command
python train.py \
--data_dir=xxx/dataset \
--yolov5_version='yolov5s' \
--is_distributed=0 \
--lr=0.01 \
--T_max=320
--max_epoch=320 \
--warmup_epochs=4 \
--per_batch_size=32 \
--lr_scheduler=cosine_annealing > log.txt 2>&1 &
然后就成功训练起来了

mindspore-yolov5的小改动
看了几篇中文核心,大抵上都是加了注意力模块,修改了损失函数等(甚至有几篇加的注意力和修改的损失都一样,离谱),那就仿照着做吧
做了以下优化:
1.yolov5的主干网络加入了SE注意力(只是用来测试,所以选择了最简单的注意力,已发表的核心主要加的是CA,ECA注意力等)
2.将giou损失修改为GIOU损失,提高边界框定位精度
SEnet的torch代码实现如下:
import torch
import torch.nn as nn
import math
class se_block(nn.Module):
def __init__(self, channel, ratio=16):
super(se_block, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4478
4478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









