







前言
树模型实在是个庞大的家族,里面有许多细节值得注意,怕自己遗忘,写一期总结方便以后查询。先介绍三种划分方式:
信息增益:
- 计算数据集D中的经验熵H(D):
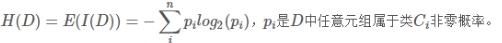
- 计算特征A对数据集D的经验条件H(D/A):
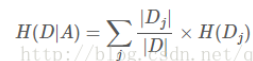
- 计算休息增益差:

其中D为样本容量,pi代表当前节点D中i类样本比例。设有K个类(1,2,…,K),Ck为属于为K类样本的样本数。设特征A有j个不同的取值(a1,…,aj),根据A的取值将D划分为D1,…,Dj(代表样本数)。
信息增益率:
- 分裂信息计算公式:
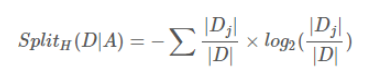
- 信息增益率定义为:
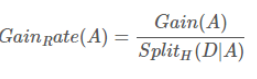
- 选择最大增益率作为分裂特征
Gini系数:
在CART树中使用,这里CART先不展开后文会写。
- 从根节点开始,对节点计算现有特征的基尼指数。
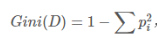
- 对每一个特征,例如A,再对其每个可能的取值如a,根据样本点对A=a的结果划分为两个部分(这里假设A只有两个值,因为CART是二叉树):
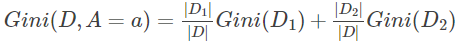
- 上面的式子表示的是不确定性的大小,越小表示数据纯度越高。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1269
1269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









