







前言
由于纸质笔记又臭又长(SVM这篇长达六张纸),可能字太难看完全没欲望于是把一些笔记整理到网上(公式可能太多),方便翻阅。
主要有这么个部分:
1. 函数间距、几何间距、软间距定义与区别。
2. SVM推导、拉格朗日乘子法、KKT条件、对偶问题
3. 软间距问题
4. 转换对偶问题的原因
5. 非线性决策边界和核函数
6. SMO算法详解
7. 为什么对缺失值 敏感
8. 核函数优点缺点、区别与选择
9. SVM的缺点
超平面间隔选择
对于一组数据来说,我们希望所有的样本都距离决策边界很远。即我们只需保证距离边界的点的距离都很大。那么我们如何来刻画这个距离?
-
首先我们将分类标签记为(1,-1),而不是逻辑回归的(0,1),这里的原因会在后面的细节里提到。定义假设函数:h = g(wTx+b),其中g(z) =1 ,如果z>=0,否则g(z) = 0.
-
定义点x0到直线的距离:(|wTx0 + b|)/||w||
-
定义函数距离:对于一个训练样本(xi,yi),我们定义函数距离:
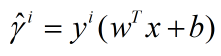
如果yi = 1,要使距离最大我们需要wTx+b越大;yi= -1时,同理。
对于给定的数据集(xi,yi,i=1,2,3,…,m)我们定义离决策边界最近的的距离为:
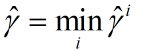
-
引入几何间距:
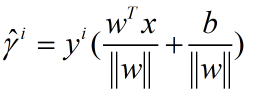
该章总结:
- 采用间隔最大化:使得两个分类的训练实例都尽量原理分界线,具有很强的鲁棒性,对未知实例的泛化能力最强。
- 几何间隔和函数间隔:对比上面两种距离的定义。假如我我们比例增大W与B,那么函数间隔可以任意大,于是引入几何间隔,实际上几何间距是点到超平面的距离。
- SVM 是一个二分类模型,他的基本模型是在特征空间中寻找间隔最大化的分离超平面线性分类器:
- 当训练线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机。
- 当训练样本近似线性可分,引入松弛变量,通过软间隔最大化,即线性支持向量机。(本文第三部分)
- 当训练样本线性不可分,通过核技巧及软间隔最大化,学习非线性支持向量机。(同第
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1805
1805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









