







数据结构第六章(四)
图的应用(一)
一、最小生成树
连通图的生成树是包含图中全部顶点的一个极小连通子图(边尽可能地少,但要保持连通)。
若图中顶点数为n,则它的生成树含有n-1条边(还记得我们之前说的吗?顶点为n的图要保持连通的最少边就是n-1条)。对生成树而言,若砍去它的一条边,则会变成非连通图,若加上一条边则会形成一个回路。
最小生成树是指在一个连通的加权图中,选取一些边,使得这些边连接所有的顶点,并且总权重最小,Prim算法和Kruskal算法就是用来解决这个问题的。
我们来看看官方定义:
对于一个带权连通无向图G=(V,E),生成树不同,每棵树的权(即树中所有边上的权值之和)也可能不同。设R为G的所有生成树的集合,若T为R中边的权值之和最小的生成树,则称T为G的最小生成树(Minimum-Spanning-Tree,MST)
其实就是上面说的。
而且要注意一下,最小生成树其实也是生成树,也就是说它也满足 边数=顶点数-1 ,砍掉一条则不连通,增加一条边则一定会出现回路。
还有就是:最小生成树可能有多个,但边的权值之和总是唯一且最小的。
如下所示:
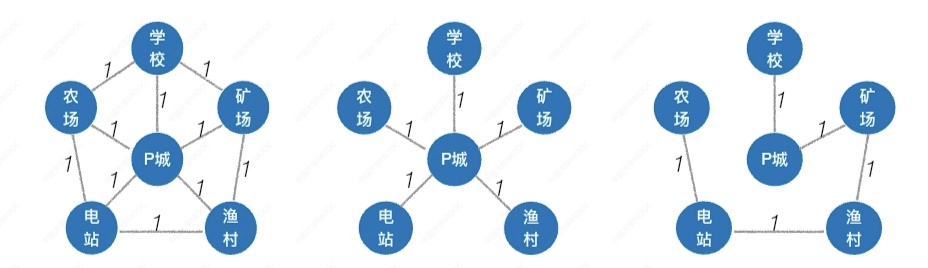
还有我们要知道,树是特殊的图,树没有环,而且树如果少了什么边,就不连通了是吧,所以:
- 如果一个连通图本身就是一棵树,则其最小生成树就是它本身
- 只有连通图才有生成树,非连通图只有生成森林
1.Prim算法
Prim算法说白了就是从一个顶点开始,逐步扩展,每次选择一条权值最小的边,连接一个未被访问过的顶点。
Prim算法:从某一个顶点开始构建生成树;每次将代价最小的新顶点纳入生成树,直到所有顶点都纳入为止。
比如下面这个图,用Prim算法构造一个最小生成树:
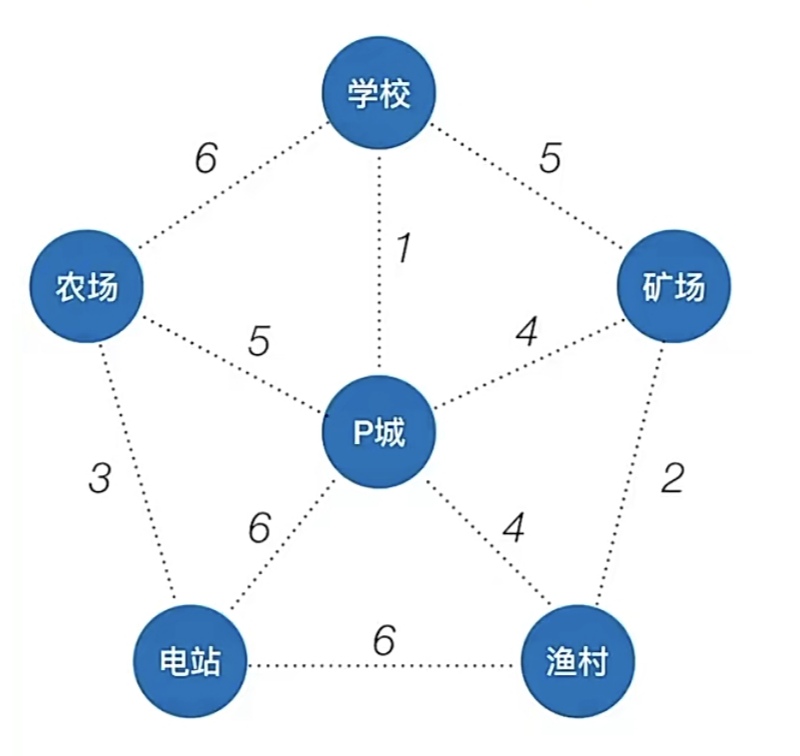
我们从顶点“P城”出发,首先P城加入我们构造的最小生成树(只有这一个顶点),然后我们找一个顶点加入这个最小生成树,使得代价最小,那么我们可以看到把“学校”这个顶点加入到最小生成树中的代价只有1,这个是最小的代价(此时我们的最小生成树变成了“P城-学校”),接着我们再看把哪个顶点加入到现在的最小生成树代价最小,环顾四周有个最小的代价是4(“矿场”“渔村”都可以),我们就把“矿场”加入到最小生成树里(此时我们的最小生成树变成了“P城-学校-矿场”),之后我们再再看把哪个顶点加入到现在的最小生成树代价最小,看到把“渔村”加入代价只有2,我们就把“渔村”加入到最小生成树里(此时我们的最小生成树变成了“P城-学校-矿场-渔村”),以此类推,把“农村”加进去,再以此类推,把“电站”加进去,遂完成。
我们通过Prim算法构造的最小生成树如下图所示:
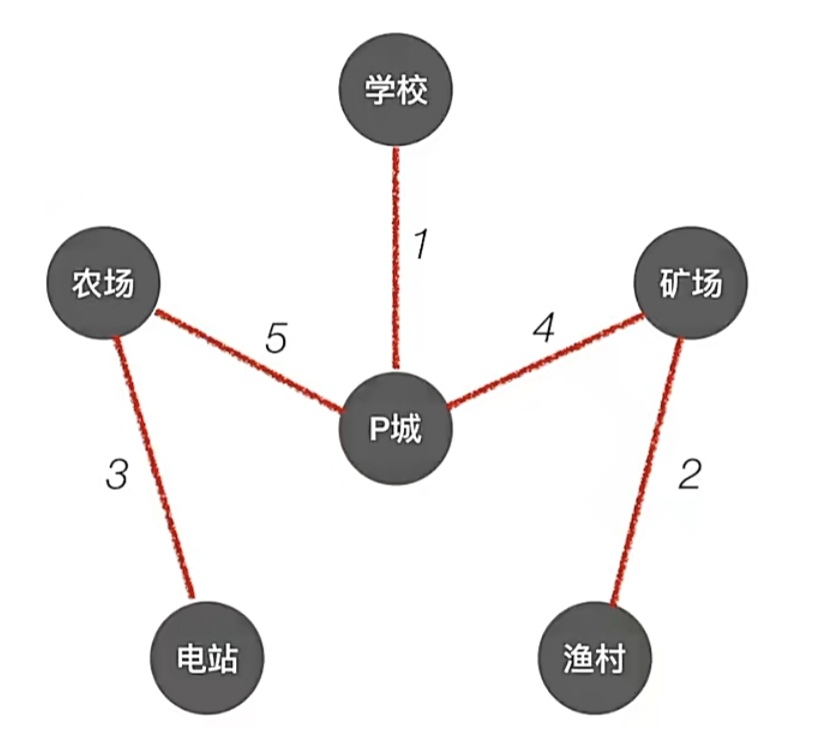
当然,也可以在当时不加入“矿场”,加入“渔村”(把他们加入的代价是相等的,都是4),构造的最小生成树就不一样了,但是代价是一样的,最小生成树可以有多个但是代价都是最小的。
如果我们要用算法实现该怎么实现呢?我们首先要看各个结点是不是在树里,还要知道哪个加入代价最小。所以我们设置两个数组,一个isJoin数组,标记各节点是否已加入树;一个lowCost数组,存放各节点加入树的最低代价,用下面这个图来说明:
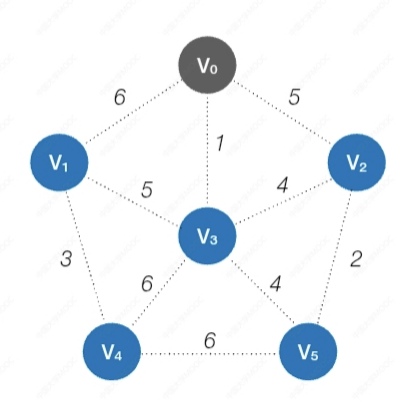
从V0开始,总共需要n-1轮处理
标记各节点是否已加入树(isJoin[6])
| v0 | v1 | v2 | v3 | v4 | v5 |
|---|---|---|---|---|---|
√ |
× | × | × | × | × |
各节点加入树的最低代价(lowCost[6])
| 0 | 6 | 5 | 1 | ∞ | ∞ |
|---|
每一轮处理:循环遍历所有个结点,找到lowCast最低的,且还没加入树的顶点
再次循环遍历,更新还没加入各个顶点的lowCast值
说是不考算法,我就说一句话,然后就不说了:就是比如第1轮,循环遍历所有个结点,找到lowCast最低的,且还没加入树的顶点,我们找到了“1”,然后标记把v3加入树,即:
isJoin[6]数组:
| v0 | v1 | v2 | v3 | v4 | v5 |
|---|---|---|---|---|---|
√ |
× | × | √ |
× | × |
然后我们循环遍历,更新还没加入各个顶点的lowCast值:首先看v1,它和v0距离为6,和v3距离为5,5比较小,所以它的lowCost值更新为5;再看v2,它和v0距离为5,和v3距离为4,4比较小,所以它的lowCost值更新为4;之后看v4,它和v0距离为∞,和v3距离为6,6比较小,所以它的lowCost值更新为6;最后看v5,它和v0距离为∞,和v3距离为4,4比较小,所以它的lowCost值更新为4;
故我们的lowCost[6]数组:
| 0 | 5 | 4 | 1 | 6 | 4 |
|---|
……
以此类推,直到遍历完所有顶点(所有的isJoin都为TRUE)
我们可以看到,每次都要循环遍历数组找到lowCost最低的,找完以后还要循环遍历更新各个顶点的lowCost值,所以我们的每一轮时间复杂制度都是O(2n)(即O(n)),从V0开始,总共需要n-1轮处理,所以总时间复杂度为O(n2).
时间复杂度是O( |V|^2^ ),适合用于边稠密图
2.Kruskal算法
Kruskal算法其实就是从最小的边开始,逐步加入到生成树中的,但要确保不会形成环。如果加入一条边后会形成环,就跳过这条边,继续处理下一条最小的边。
Kruskal算法:每次选择一条权值最小的边,使这两条边的两头连通(原本已经连通的就不选),直到所有的结点都连通。
再请出我们的老演员这个图:
我们用Kruskal算法构造一个最小生成树,首先把们的代价从小到大排列:1,2,3,4,4,5,5,6,6,6,现在我们开始选择一条最小的边“1”,选择后把边及对应的顶点加入最小生成树(P城-学校),再看“2”这个边,这个边不连通不在生成树内,所以把这条边及对应顶点加入最小生成树……(其实肉眼看特别明显,选边就行了)以此类推,我们得到Kruskal算法构造的最小生成树:
如果我们要用算法实现该怎么实现呢? 这个Kruskal算法显然需要先把各条边都按照权值进行排序,但是我们也不是看谁小就加谁,还要看这个边对应的顶点是不是已经在最小生成树里。
按权值排序:
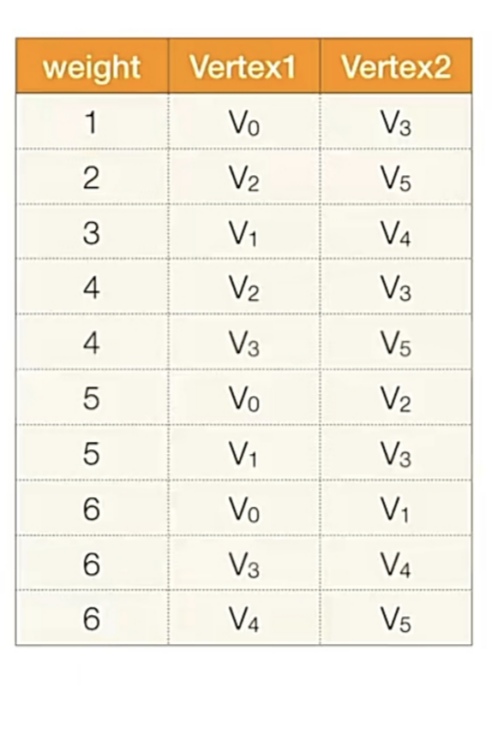
一样是不考算法,我只说一句:就是比如第1轮,我们检查第1条边的两个顶点是否连通(是否属于同一个集合<可以用并查集实现>),发现不连通就连起来,连通就接着找下一个边……以此类推。
总共执行e轮,每轮都判断两个顶点是否属于用一个集合(用并查集),时间复杂度为O(log2e),所以总时间复杂度为O(elog2e)。
时间复杂度:O( |E|log~2~|E| ),适合用于边稀疏图
再说一句题外话:
这两个算法的主要区别是什么呢?
首先就是选择边的方式不同。Prim算法是从顶点出发,每次选择连接到当前生成树的最小边;而Kruskal算法是从边出发,按边的权重从小到大排序,逐个检查是否能加入生成树。
其次是使用的数据结构不同。Prim算法通常使用优先队列(最小堆)来选择当前最小的边,而Kruskal算法则需要一个并查集数据结构来检测是否有环。
这两个算法都是贪心算法,都通过局部最优选择来达到全局最优。
二、最短路径问题
所谓单源最短路径就是找这个固定的顶点到其他顶点的最短距离,所谓各顶点间的最短路径就是找每个顶点互相之间怎么走的最短距离。
1.单源最短路径
1.1 BFS算法(无权图)
介缩写是广度优先算法。
我们广度优先遍历其实就是一层一层这样,那我们每一层都没有距离,就当做一层是1好了,于是我们在遍历到的时候走过的层数其实就是顶点到它的距离。
还记得我们广度优先算法怎么写的吗?
#define MaxVertexNum 8 //顶点数目的最大值
bool visited[MaxVertexNum]; //访问标记数组
//广度优先遍历
void BFS(Graphic G, int v){
//从顶点v出发,广度优先遍历图G
visit(v); //访问初始顶点v
visited[v] = TRUE; //对v做已访问标记
Enqueue(Q,v); //顶点v入队列Q
while(!isEmpty(Q)){
DeQueue(Q,v); //顶点v出队列
for(w = FirstNeighbor(G 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2830
2830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









