







本文将就Multi-Scale Boosted Dehazing Network with Dense Feature Fusion网络架构进行分析,并给出对应代码的注释
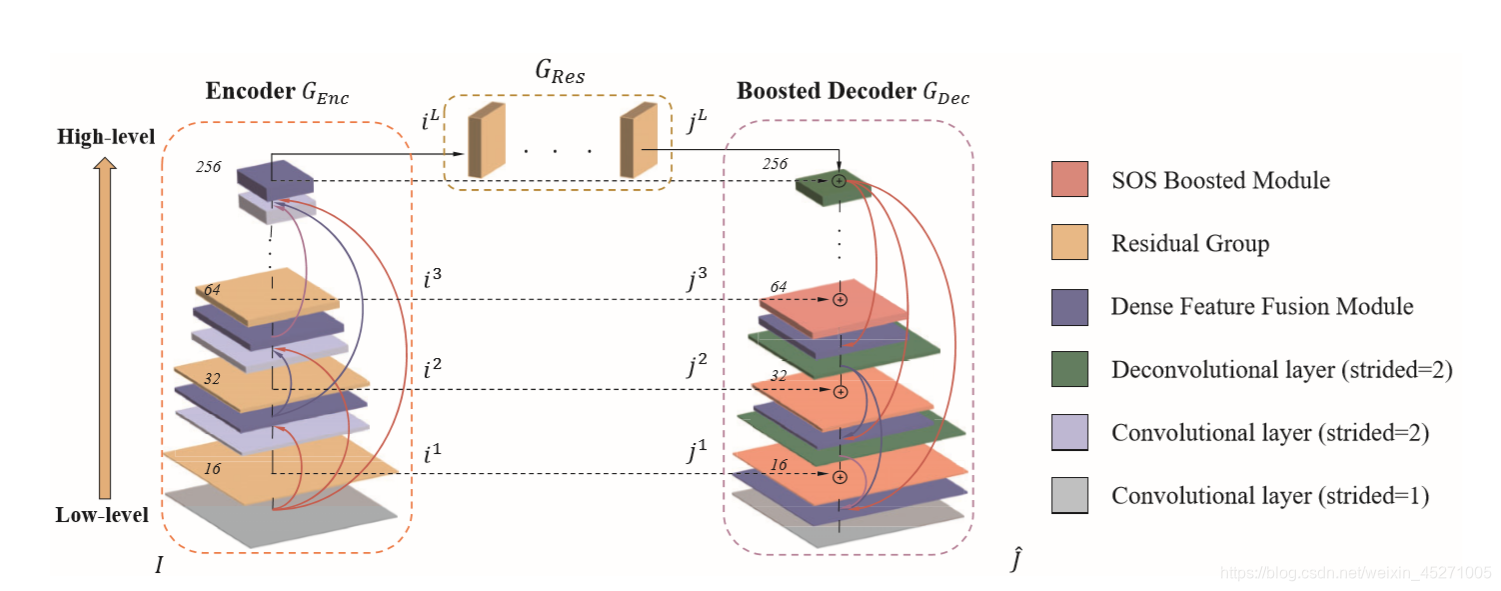
待处理的雾图从左下角输入,经过Genc,Gres,Gdec三个部分之后得到处理好的去雾图片。
在Genc部分,
雾图首先被传入到一个步长为1的卷积层中提取浅层信息,输出层数为16,并把输出保存到特征数组里;
然后传入到ResidualGroup中,在这个group中有三个相同的ResidualBlock,每个block的结构为一层卷积+一层relu+一层卷积+一个全局残差,最后ResidualGroup的输出与其输入相加;
然后传入到一个步长为2的卷积层,输出层数为32;再将输出和特征数组一并传入到Dense Feature Fusion Module中,并将输出保存到特征数组里;然后传入到ResidualGroup中,输出的结果和输入的矩阵相加;
然后传入到一个步长为2的卷积层,输出层数为64;再将输出和特征数组一并传入到Dense Feature Fusion Module中,并将输出保存到特征数组里;然后传入到ResidualGroup中,输出的结果和输入的矩阵相加;
然后传入到一个步长为2的卷积层,输出层数为128;再将输出和特征数组一并传入到Dense Feature Fusion Module中,并将输出保存到特征数组里;然后传入到ResidualGroup中,输出的结果和输入的矩阵相加;
然后传入到一个步长为2的卷积层,输出层数为256;再将输出和特征数组一并传入到Dense Feature Fusion Module中得到Genc部分的最终输出。
将Genc部分的输出传入到Gres模块,
在feature restoration module中,输入乘以二后传入到由18层ResidualBlock和一个全局残差结构组成的结构中,得到的结果再减去输入就是最终的Gres模块输出了。
然后将Gres的输出传入到Gdec模块,
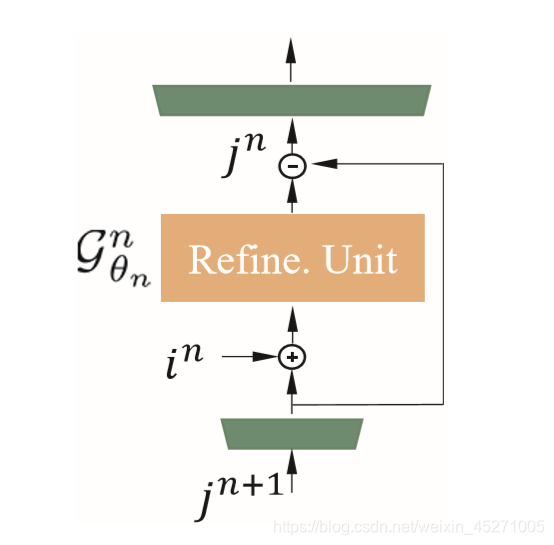
先把Gres的输出保存到Gdec模块的特征数组里,然后传入到一层步长为2反卷积网络中,输出128;然后将输出传入到SOS boosting module,这个模块如下所示:
公式如下所示:
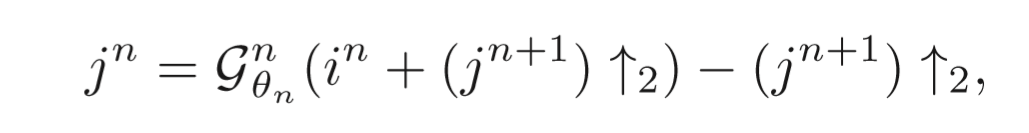
即对上一层输入进行上采样,使其大小与对应encode层的ResidualGroup输出相同,采样参数为‘bilinear’,然后再将上采样结果与对应encode层的ResidualGroup输出相加,传入到G()函数中,再减去上采样的结果就得到最后输出;其中G()函数的网络架构是ResidualGroup+一个全局残差;再将输出和特征数组一并传入到Dense Feature Fusion Module中,并将输出保存到特征数组里;
然后传入到一层步长为2的反卷积中,输出层数为64;再传入到SOS boosting module;再将输出和特征数组一并传入到Dense Feature Fusion Module中,并将输出保存到特征数组里;
然后传入到一层步长为2的反卷积中,输出层数为32;再传入到SOS boosting module;再将输出和特征数组一并传入到Dense Feature Fusion Module中,并将输出保存到特征数组里;
然后传入到一层步长为2的反卷积中,输出层数为16;再传入到SOS boosting module;再将输出和特征数组一并传入到Dense Feature Fusion Module中,并将输出保存到特征数组里;
最后再传入到一层步长为1的反卷积中,输出层数为3,即为处理好的图片。
接下来是对应网络的代码,附带有注释。
import torch
import torch.nn as nn
import torch.nn.functional as F
from networks.base_networks import Encoder_MDCBlock1, Decoder_MDCBlock1
def make_model(args, parent=False): # not in use
return Net()
class make_dense(nn.Module): # not in use
def __init__(self, nChannels, growthRate, kernel_size=3):
super(make_dense, self).__init__()
self.conv = nn.Conv2d(nChannels, growthRate, kernel_size=kernel_size, padding=(kernel_size - 1) // 2,
bias=False)
def forward(self, x):
out = F.relu(self.conv(x))
out = torch.cat((x, out), 1)
return out
class ConvLayer(nn.Module): # 一层卷积,16个滤波器
def __init__(self, in_channels, out_channels, kernel_size, stride):
super(ConvLayer, self).__init__()
reflection_padding = kernel_size // 2
self.reflection_pad = nn.ReflectionPad2d(reflection_padding) # 填充,长宽增长一个kernel_size
self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride)
def forward(self, x): # 填充之后卷积
out = self.reflection_pad(x)
out = self.conv2d(out)
return out
class UpsampleConvLayer(torch.nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride):
super(UpsampleConvLayer, self).__init__()
self.conv2d = nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=stride)
def forward(self, x):
out = self.conv2d(x)
return out
class ResidualBlock(torch.nn.Module): # 卷积+relu+卷积+残差
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.conv1 = ConvLayer(channels, channels, kernel_size=3, stride=1)
self.conv2 = ConvLayer(channels, channels, kernel_size=3, stride=1)
self.relu = nn.PReLU() # 非正数不是0,而是一个很小的负数
def forward(self, x):
residual = x
out = self.relu(self.conv1(x))
out = self.conv2(out) * 0.1
out = torch.add(out, residual) # 对应元素相加
return out
class Net(nn.Module):
def __init__(self, res_blocks=18):
super(Net, self).__init__()
self.conv_input = ConvLayer(3, 16, kernel_size=11, stride=1)
self.dense0 = nn.Sequential(
ResidualBlock(16),
ResidualBlock(16),
ResidualBlock(16)
)
self.conv2x = ConvLayer(16, 32, kernel_size=3, stride=2)
self.fusion1 = Encoder_MDCBlock1(32, 2, mode='iter2')
self.dense1 = nn.Sequential(
ResidualBlock(32),
ResidualBlock(32),
ResidualBlock(32)
)
self.conv4x = ConvLayer(32, 64, kernel_size=3, stride=2)
self.fusion2 = Encoder_MDCBlock1(64, 3, mode='iter2')
self.dense2 = nn.Sequential(
ResidualBlock(64),
ResidualBlock(64),
ResidualBlock(64)
)
self.conv8x = ConvLayer(64, 128, kernel_size=3, stride=2)
self.fusion3 = Encoder_MDCBlock1(128, 4, mode='iter2')
self.dense3 = nn.Sequential(
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128)
)
self.conv16x = ConvLayer(128, 256, kernel_size=3, stride=2)
self.fusion4 = Encoder_MDCBlock1(256, 5, mode='iter2')
# self.dense4 = Dense_Block(256, 256)
self.dehaze = nn.Sequential() # 18个残差块
for i in range(0, res_blocks):
self.dehaze.add_module('res%d' % i, ResidualBlock(256))
self.convd16x = UpsampleConvLayer(256, 128, kernel_size=3, stride=2)
self.dense_4 = nn.Sequential(
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128)
)
self.fusion_4 = Decoder_MDCBlock1(128, 2, mode='iter2')
self.convd8x = UpsampleConvLayer(128, 64, kernel_size=3, stride=2)
self.dense_3 = nn.Sequential(
ResidualBlock(64),
ResidualBlock(64),
ResidualBlock(64)
)
self.fusion_3 = Decoder_MDCBlock1(64, 3, mode='iter2')
self.convd4x = UpsampleConvLayer(64, 32, kernel_size=3, stride=2)
self.dense_2 = nn.Sequential(
ResidualBlock(32),
ResidualBlock(32),
ResidualBlock(32)
)
self.fusion_2 = Decoder_MDCBlock1(32, 4, mode='iter2')
self.convd2x = UpsampleConvLayer(32, 16, kernel_size=3, stride=2)
self.dense_1 = nn.Sequential(
ResidualBlock(16),
ResidualBlock(16),
ResidualBlock(16)
)
self.fusion_1 = Decoder_MDCBlock1(16, 5, mode='iter2')
self.conv_output = ConvLayer(16, 3, kernel_size=3, stride=1)
def forward(self, x):
res1x = self.conv_input(x) # Convolutional layer (strided=1)
feature_mem = [res1x]
x = self.dense0(res1x) + res1x # Residual Group
res2x = self.conv2x(x) # Convolutional layer (strided=2)
res2x = self.fusion1(res2x, feature_mem) # Dense Feature Fusion Module of encoding
feature_mem.append(res2x) # feature accumulation
res2x = self.dense1(res2x) + res2x # Residual Group
res4x = self.conv4x(res2x)
res4x = self.fusion2(res4x, feature_mem)
feature_mem.append(res4x)
res4x = self.dense2(res4x) + res4x
res8x = self.conv8x(res4x)
res8x = self.fusion3(res8x, feature_mem)
feature_mem.append(res8x)
res8x = self.dense3(res8x) + res8x
res16x = self.conv16x(res8x)
res16x = self.fusion4(res16x, feature_mem)
# res16x = self.dense4(res16x)
res_dehaze = res16x
in_ft = res16x * 2
res16x = self.dehaze(in_ft) + in_ft - res_dehaze # 乘2,18个残差块,再做残差
feature_mem_up = [res16x]
res16x = self.convd16x(res16x) # Deconvolutional layer (strided=2)
res16x = F.upsample(res16x, res8x.size()[2:], mode='bilinear') # 上采样,算法'bilinear'
res8x = torch.add(res16x, res8x)
res8x = self.dense_4(res8x) + res8x - res16x # SOS boosting module
res8x = self.fusion_4(res8x, feature_mem_up) # Dense Feature Fusion Module of decoding
feature_mem_up.append(res8x)
res8x = self.convd8x(res8x)
res8x = F.upsample(res8x, res4x.size()[2:], mode='bilinear')
res4x = torch.add(res8x, res4x)
res4x = self.dense_3(res4x) + res4x - res8x
res4x = self.fusion_3(res4x, feature_mem_up)
feature_mem_up.append(res4x)
res4x = self.convd4x(res4x)
res4x = F.upsample(res4x, res2x.size()[2:], mode='bilinear')
res2x = torch.add(res4x, res2x)
res2x = self.dense_2(res2x) + res2x - res4x
res2x = self.fusion_2(res2x, feature_mem_up)
feature_mem_up.append(res2x)
res2x = self.convd2x(res2x)
res2x = F.upsample(res2x, x.size()[2:], mode='bilinear')
x = torch.add(res2x, x)
x = self.dense_1(x) + x - res2x
x = self.fusion_1(x, feature_mem_up)
x = self.conv_output(x) # Convolutional layer (strided=1)
return x














 3236
3236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









