一、概念了解
1. 性能测试的维度和类型
| 编号 | 类型 | 概念 | 标准 | 举例 |
|---|
| 1 | 基准测试 | 给系统施加较低压力,查看系统运行状况并记录相关数据作为基础参考 | 10%~20% | 软件最多只给100个人使用,先用10~20人测试一下 |
| 2 | 负载测试 | 不断增加压力或增加一定压力下的持续时间,直到找到达成多项性能指标的安全临界值 | 找到最佳性能点 | 某种资源已经达到饱和状态 |
| 3 | 压力测试 | 测试系统超载时的运行情况,关注系统在峰值或超载时的处理能力 | 150% | 允许20000人排队,测试第20001个人请求时的处理(应该将请求拦截下来,避免系统崩溃) |
| 4 | 稳定性测试 | 给系统中上游压力时,让系统持续运行一段时间,模拟绝大多数常态的使用 | 40%~60% | - |
| 5 | 并发测试 | 多个用户同时访问同一个应用/模块 | 视实际情况而定 | 12306抢票,9点放票,同时抢票 |
2. 性能测试常用指标
| 编号 | 指标 | 定义 | 说明 |
|---|
| 1 | 响应时间 | 响应时间=呈现时间+网络传输时间+服务器端响应时间+应用延时时间 | 用户负载不断增加,响应时间突然增加的点就是性能最佳点 |
| 2 | 吞吐量 | 吞吐量=请求总数/花费的总时间 | 用户负载不断增加,吞吐量会突然下降 |
| 3 | 并发数 | 分为并发用户数、在线用户数、系统用户数 | 系统用户数≥在线用户数≥并发用户数,等于的情况很难实现 |
| 4 | 资源利用率 | 不同系统资源的使用程度 | 需关注CPU、内存、磁盘IO、网络带宽 |
| 5 | 页面访问量(PV) | 访问一个url,产生1个PV,累加制 | 1个用户访问10次,算10个访问量 |
| 6 | 用户访问量(UV) | 一个独立用户,访问站点所有页面都算作1个UV,按用户计算 | 商家投放广告关注UV,关注的是稳定用户使用量 |
3. 资源利用率关注点
| 关注点 | 上限 |
|---|
| CPU | 不要超过80%~90% |
| 内存 | 不要超过80%~90% |
二、jmeter性能测试
Jmeter的主要思想:先构造用户,再让用户去请求对应的接口。
1. jmeter性能测试步骤
| 编号 | 步骤 | 实现方法 | 作用 | 备注 |
|---|
| 1 | 添加线程组 | 测试计划->添加->Threads(users)->线程组 | 配置线程数、循环次数等 | 一个线程组相当于一个用户 |
| 2 | 添加HTTP请求 | 线程组->添加->sampler->HTTP请求 | 接口参数配置 | Sampler:取样器,用来模拟请求 |
| 3 | 配置HTTP接口 | 将接口完整的url地址复制到路径栏,并填入请求信息 | - | 请求信息是json形式时选择body data |
| 4 | 添加HTTP信息头管理器 | HTTP接口->添加->配置元件->HTTP信息头管理器 | 设置接口的content-type | Jmeter默认传输请求信息的方式是表单类型,即Content-Type: application/x-www-form-urlencoded |
| 5 | 添加cookie管理器 | 线程组->添加->HTTP Cookie管理器 | 获取发起登录请求时的cookie信息,当同一个人再次发起请求时,cookie信息就会被传入。 | 添加后不用做任何配置;登录和其他请求需要在同一个线程组内;还可在HTTP信息头管理器中添加cookie,但使用不灵活 |
| 6 | 配置线程组 | 设置线程数、循环次数等 | 实现多个人同时请求 | 线程数默认是1,一般单个人请求成功后再进行这一步 |
| 7 | 添加断言结果 | HTTP接口->添加->断言->响应断言 | 断言结果是否符合预期设置结果 | 常用包含、匹配,有多个断言条件时,需同时满足才通过 |
| 8 | 添加查看结果树 | 线程组->添加->监听器->察看结果树 | 查看请求结果 | 按绿色按钮,运行请求 |
| 9 | 运行请求 | 在查看结果树页面点击绿色运行按钮 | 运行接口请求 | 看请求信息是否与填写的一致,看响应数据是否正常 |
| 10 | 添加聚合报告 | 线程组->添加->监听器->聚合报告 | 接口测试结果性能展示 | 聚合报告可导出 |
| 11 | 添加物理资源监控插件 | 线程组->添加->监听器->jp@gc – PerMon Metrics Collector | 监控服务器和本地电脑的物理资源变化 | 一般监控CPU、内存、磁盘、网络四个选项 ,还应监控自己电脑的资源,实现双向监控 |
2. 参数化方法
参数化:将写死的东西变成变量
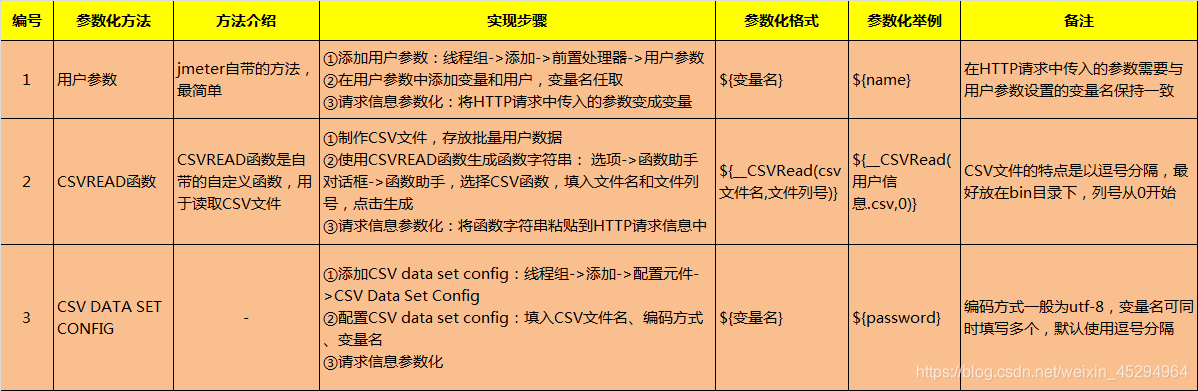
3. CSV Data Set Config参数设置
| 编号 | 参数 | 含义 | 填写说明 |
|---|
| 1 | filename | 文件名 | 支持绝对路径和相对路径 |
| 2 | file encoding | 编码方式 | 一般使用utf-8 |
| 3 | variable names | 变量名 | 默认以逗号分隔 |
| 4 | delimiter | 分隔方式 | 默认为逗号 |
| 5 | allow quoted data | 是否考虑引号 | 默认不考虑(false),如果考虑引号,引号中的逗号不会被分隔 |
| 6 | recycle on EOF | 文件读取结束后是否要循环 | 默认循环(true),比如只有100个用户信息,但需要200个人登录,会循环取数据 |
| 7 | stop thread on EOF | 文件读取结束后是否要停止 | 当取不到数据时是否停止,true代表停止,false代表不停止,但取不到数据,会导致这几个请求实际没有传参。 |
| 8 | sharing mode | 分享模式 | all threads——给所有线程使用,current thread group——给当前线程组使用,current thread——给当前线程使用。 |
4. 线程组的线程属性
| 编号 | 属性 | 含义 | 理解 | 备注 |
|---|
| 1 | 线程数 | 一个线程数就是一个用户 | - | - |
| 2 | Ramp-up period | 决定多长时间启动所有线程 | 如果有5个线程,ramp-up period是10秒,则每隔2(10/5)秒启动一个线程。如果ramp-up period是0秒,则jmeter会立即建立所有线程 | 构造用户的间隔时间(秒)=Ramp-up period/线程数,用户构造完成后会立马发起请求 |
| 3 | 循环次数 | 默认循环1次,可修改次数 | 循环2次时,同一个人会请求2次,不受其他用户的影响 | 永远循环:需要谨慎操作,很可能会让电脑卡死 |
| 4 | 调度器 | 优先级:启动时间/结束时间的优先级比持续时间/启动延迟低 | 如果4个选项均填写了内容,则默认持续时间/启动延迟选项设置生效,启动时间/结束时间设置不生效 | 调度器一般在循环次数为永远时生效 |
| 5 | 启动/结束时间 | 设置固定的时间启动和结束 | 比如:设置启动时间为2021/02/03 21:00:00 | - |
| 6 | 启动延迟/持续时间 | 设置启动延迟5秒,持续时间10秒 | 5秒后启动,持续10秒 | - |
5. 并发测试
真正的并发需要使用同步定时器,
- 添加同步定时器:线程组->添加->定时器->synchronizing Timer(同步定时器)
- 设置并发人数(number of simulated users to group by)
| 编号 | 步骤 | 实现方式 | 说明 |
|---|
| 1 | 添加同步定时器 | 线程组->添加->定时器->synchronizing Timer(同步定时器) | 同步定时器是最接近真实情况的并发 |
| 2 | 设置并发人数 | number of simulated users to group by一栏设置人数 | 只有用户数构造完后才会一起去请求这个接口 |
| 3 | 设置超时时间 | timeout in millisecond一栏设置超时时间,单位毫秒 | 如果超时时间过了,用户还没构造完成,则已经构造好的用户会同时发起请求。设置为0,表示永不超时 |
6. 有关联性的接口处理方法
有关联的接口举例:考试系统中要删除一个用户,需要先获取查询到的用户id,再根据用户id进行删除操作
| 编号 | 方法 | 添加方式 | 配置参数 | 表达式获取方法 | 表达式替代变量的格式 |
|---|
| 1 | 正则表达式提取器 | HTTP接口->添加->后置处理器->正则表达式提取器 | 配置引用名称、正则表达式、模板、匹配数字、缺省值 | 正则表达式获取:察看结果树->RegExp Tester,在Regular expression中填写正则表达式 | ${变量名} |
| 2 | json表达式提取 | HTTP接口->添加->后置处理器->JSON Extractor | 配置变量名、json表达式、匹配数字、默认值 | json表达式获取:察看结果树->JSON Path Tester,在JSON Path Expression中填写json表达式 | ${变量名} |
| 编号 | 表达式 | 语法 | 举例 | 含义 |
|---|
| 1 | 正则表达式 | .+?表示匹配任意符合的字符串,将变量修改为.+? | “id”.+?“userUuid” | 匹配到前面是"id"后面是"userUuid"的表达式 |
| 2 | json表达式 | 整个json体是一个大字典,以{}表示, | $.response.list[0].id | 获取字典里的id,id在list列表的第一个元素,list列表在response字典中,访问列表元素使用下标,从0开始 |
7. 聚合报告字段解析
| 编号 | 字段 | 解析 |
|---|
| 1 | samples | 线程数 |
| 2 | average | 平均响应时间,单位毫秒 |
| 3 | median | 中间响应时间,反应中等水平 |
| 4 | 90% line | 响应时间从低到高排序,排在90%的响应时间 |
| 5 | 95% line | 排在95%的响应时间 |
| 6 | 99% line | 排在99%的响应时间 |
| 7 | Min | 最小响应时间 |
| 8 | Max | 最大响应时间 |
| 9 | Error % | 错误率 |
| 10 | Throughput | 吞吐量,每秒处理了多少请求,单位是秒,计算方式:请求数/花费的总时间 |
| 11 | Received KB/S | 接收的网络带宽速度,计算方式:传输的文件大小(响应数据大小)/花费的时间 |
| 12 | Sent KB/S | 发送的网络带宽速度,计算方式:请求数据大小/花费的时间 |
8. 判断性能是否达标
(1)响应时间遵循2-5-8原则
(2)99%的人响应时间在2秒以内就认为性能OK,同时错误率不能超过1%。
9. 最大吞吐量和最大并发量
| 编号 | 项目 | 解释 | 举例说明 |
|---|
| 1 | 最大吞吐量 | 不并发,看一段时间的处理水平 | 前10分钟优惠有效 |
| 2 | 最大并发量 | 并发 ,看同一时间的处理水平 | 前30名优惠 |
10. 各性能测试执行
| 编号 | 测试项目 | 关注点 | 线程属性设置 | 备注 |
|---|
| 1 | 基准测试 | 不考虑并发,看吞吐量 | 线程数200,时间10秒,每秒20个,循环1次 | - |
| 2 | 负载测试 | 在基准测试的基础上继续加压 | 线程数100,时间10秒,循环20次 | 测吞吐量时不建议让本地电脑不停造人,实际需要测试的是接口调用,一般是快速造人,然后进行循环 |
| 3 | 压力测试 | 关注服务器会不会因为压力太大而挂掉 | 线程数100,时间10秒,循环次数不断增加 | 在增加压力的过程中错误率或响应时间会突然明显增加 |
| 4 | 稳定性测试 | 关注长时间运行,系统的稳定性 | 在调度器里设置运行时间 | - |
| 5 | 并发测试 | 此时不用太过关注吞吐量,重点关注响应时间和错误率 | 已经测出来最大吞吐量之后,比如每秒处理500个请求,则线程数设为500,时间可以设长一点30秒(自己调整),循环次数1次,然后设置同步定时器:500一组,超时时间为0 | 如果并发没有问题,可以不断往上加数据 |























 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











