







文章目录
一、ERNISage
文本图:节点与边带有文本的特殊图,文本图广泛应用于工业应用中例如搜索场景、贴吧推荐、知识图谱等。文本图的样例如下:

对于文本图的建模,仅仅使用类似于GraphSage的结构建模或ERNIE的语义理解模型不能同时满足对结构和语义的理解,因此为了同时对结构和语义进行建模,提出了ERNIESage。
ERNIE是一种语义理解模型,可以通过models.ernie_model.ernie.ErnieModel直接进行调用。根据将ERNIE作用在图结构的不同位置,可以将ERNIESage分为三种,分别是ERNIESage Node、ERNIESage Edge、ERNIESage 1-Neighbour。
1.ERNIESage Node
将ERNIE作用在文本图的节点上

ERNIESage Node的步骤如下:
- 利用ERNIE获取节点表示
- 聚合邻居特征
- 将当前节点和聚合后的邻居特征concat,更新节点特征
ERNIESage Node是一个双塔模型:

2.ERNIESage Edge
将ERNIE作用在文本图的边上
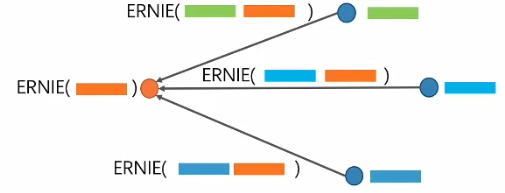
ERNIESage Edge的步骤如下:
- 利用ERNIE获取中心节点的文本特征表示
- 交互:中心节点和邻居节点一同作为ERNIE输入,计算交互特征
- 聚合邻居特征
- 将当前节点和聚合后的邻居特征concat,更新节点特征
ERNIESage Edge是一个单塔模型,大部分情况下,单塔模型要优于双塔模型。

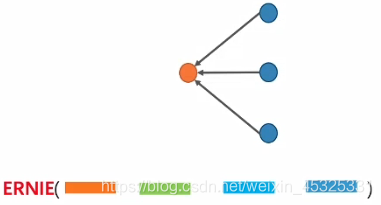
3.ERNIESage 1-Neighbour
将ERNIE作用在文本图的一阶邻居以及边上,将中心节点的文本与所有一阶邻居节点文本进行单塔拼接,再利用ERNIE做消息聚合。
以上方法存在两个问题:
- 如何确保输入时邻居不带有顺序
解决办法:为每个邻居设置独立的位置编码 - 邻居数量过多怎么办
解决办法:对邻居进行采样
二、UniMP
(一点都没听懂。。。)
UniMP:融合标签传递和图神经网络的统一模型
在一般的机器学习场景中,监督学习占了绝大部分,即数据和标签是一一对应的关系,通过构建模型来预测新的数据;而在图网络的场景中,训练数据不仅仅对应着标签,训练数据之间还有着各种各样的联系,通过这些联系,我们相当于构建了一个半监督的节点分类场景。
因此在图神经网络中,我们可以将训练集的标签作为特征进行训练,为了防止这样做会产生的标签泄露问题,UniMP提出了Maked Label Prediction。
Masked Label Prediction:通过Mask预测来学习标签之间的关系。加入训练集标签信息的方法如下图,首先对标签进行编码使维度和输入维度相同,之后直接和输入相加,得到的结果作为输入参与传播。

模型结构:

三、编程实践
1.ERNIESage V1
class ERNIESageV1Encoder():
def __init__(self, config):
self.config = config
def __call__(self, graph_wrappers, inputs):
# step1. ERNIE提取节点语义
# 输入每个节点的文本的id序列
term_ids = graph_wrappers[0].node_feat["term_ids"]
cls = L.fill_constant_batch_size_like(term_ids, [-1, 1], "int64",
self.config.cls_id) # cls [B, 1]
term_ids = L.concat([cls, term_ids], 1) # term_ids [B, S]
# [CLS], id1, id2, id3 .. [SEP]
ernie_model = ErnieModel(self.config.ernie_config)
# 获得ERNIE的[CLS]位置的表达
cls_feat, _ = ernie_model(term_ids) # cls_feat [B, F]
# step2. GNN聚合
feature = graphsage_sum(cls_feat, graph_wrappers[0], self.config.hidden_size, "v1_graphsage_sum", "leaky_relu")
final_feats = [
self.take_final_feature(feature, i, "v1_final_fc") for i in inputs
]
return final_feats
def take_final_feature(self, feature, index, name):
"""take final feature"""
feat = L.gather(feature, index, overwrite=False)
feat = linear(feat, self.config.hidden_size, name)
feat = L.l2_normalize(feat, axis=1)
return feat
def graphsage_sum(feature, gw, hidden_size, name, act):
# copy_send
msg = gw.send(lambda src, dst, edge: src["h"], nfeat_list=[("h", feature)])
# sum_recv
neigh_feature = gw.recv(msg, lambda feat: L.sequence_pool(feat, pool_type="sum"))
self_feature = linear(feature, hidden_size, name+"_l", act)
neigh_feature = linear(neigh_feature, hidden_size, name+"_r", act)
output = L.concat([self_feature, neigh_feature], axis=1) # [B, 2H]
output = L.l2_normalize(output, axis=1)
return output
2.ERNIESage V2
class ERNIESageV2Encoder():
def __init__(self, config):
self.config = config
def __call__(self, graph_wrappers, inputs):
gw = graph_wrappers[0]
term_ids = gw.node_feat["term_ids"] # term_ids [B, S]
# step1. GNN send 文本id
def ernie_send(src_feat, dst_feat, edge_feat):
def build_position_ids(term_ids):
input_mask = L.cast(term_ids > 0, "int64")
position_ids = L.cumsum(input_mask, axis=1) - 1
return position_ids
# src_ids, dst_ids 为发送src和接收dst节点分别的文本ID序列
src_ids, dst_ids = src_feat["term_ids"], dst_feat["term_ids"]
# 生成[CLS]对应的id列, 并与前半段concat
cls = L.fill_constant_batch_size_like(
src_feat["term_ids"], [-1, 1], "int64", self.config.cls_id) # cls [B, 1]
src_ids = L.concat([cls, src_ids], 1) # src_ids [B, S+1]
# 将src与dst concat在一起作为完整token ids
term_ids = L.concat([src_ids, dst_ids], 1) # term_ids [B, 2S+1]
# [CLS], src_id1, src_id2.. [SEP], dst_id1, dst_id2..[SEP]
sent_ids = L.concat([L.zeros_like(src_ids), L.ones_like(dst_ids)], 1)
# 0, 0, 0 .. 0, 1, 1 .. 1
position_ids = build_position_ids(term_ids)
# 0, 1, 2, 3 ..
# step2. ERNIE提取边语义
ernie_model = ErnieModel(self.config.ernie_config)
cls_feat, _ = ernie_model(term_ids, sent_ids, position_ids)
# cls_feat 为ERNIE提取的句子级隐向量表达
return cls_feat
msg = gw.send(ernie_send, nfeat_list=[("term_ids", term_ids)])
# step3. GNN recv 聚合邻居语义
# 接收了邻居的CLS语义表达,sum聚合在一起
neigh_feature = gw.recv(msg, lambda feat: F.layers.sequence_pool(feat, pool_type="sum"))
# 为每个节点也拼接一个CLS表达
cls = L.fill_constant_batch_size_like(term_ids, [-1, 1],
"int64", self.config.cls_id)
term_ids = L.concat([cls, term_ids], 1)
# [CLS], id1, id2, ... [SEP]
# step4. ERNIE提取中心节点语义并concat
# 对中心节点过一次ERNIE
ernie_model = ErnieModel(self.config.ernie_config)
# 获取中心节点的语义CLS表达
self_cls_feat, _ = ernie_model(term_ids)
hidden_size = self.config.hidden_size
self_feature = linear(self_cls_feat, hidden_size, "erniesage_v2_l", "leaky_relu")
neigh_feature = linear(neigh_feature, hidden_size, "erniesage_v2_r", "leaky_relu")
output = L.concat([self_feature, neigh_feature], axis=1)
output = L.l2_normalize(output, axis=1)
final_feats = [
self.take_final_feature(output, i, "v2_final_fc") for i in inputs
]
return final_feats
def take_final_feature(self, feature, index, name):
"""take final feature"""
feat = L.gather(feature, index, overwrite=False)
feat = linear(feat, self.config.hidden_size, name)
feat = L.l2_normalize(feat, axis=1)
return feat
3.ERNIESage V3
from models.encoder import v3_build_sentence_ids
from models.encoder import v3_build_position_ids
class ERNIESageV3Encoder():
def __init__(self, config):
self.config = config
def __call__(self, graph_wrappers, inputs):
gw = graph_wrappers[0]
term_ids = gw.node_feat["term_ids"]
# step1. GNN send 文本id序列
# copy_send
msg = gw.send(lambda src, dst, edge: src["h"], nfeat_list=[("h", term_ids)])
# step2. GNN recv 拼接文本id序列
def ernie_recv(term_ids):
"""doc"""
num_neighbor = self.config.samples[0]
pad_value = L.zeros([1], "int64")
# 这里使用seq_pad,将num_neighbor个邻居节点的文本id序列拼接在一下
# 对于不足num_neighbor个邻居的将会pad到num_neighbor个
neighbors_term_ids, _ = L.sequence_pad(
term_ids, pad_value=pad_value, maxlen=num_neighbor) # [B, N*S]
neighbors_term_ids = L.reshape(neighbors_term_ids, [0, self.config.max_seqlen * num_neighbor])
return neighbors_term_ids
neigh_term_ids = gw.recv(msg, ernie_recv)
neigh_term_ids = L.cast(neigh_term_ids, "int64")
# step3. ERNIE同时提取中心和多个邻居语义表达
cls = L.fill_constant_batch_size_like(term_ids, [-1, 1], "int64",
self.config.cls_id) # [B, 1]
# 将中心与多个邻居的文本全部拼接在一起,形成超长的文本(num_nerghbor+1) * seqlen
multi_term_ids = L.concat([cls, term_ids[:, :-1], neigh_term_ids], 1) # multi_term_ids [B, (N+1)*S]
# [CLS], center_id1, center_id2..[SEP]n1_id1, n1_id2..[SEP]n2_id1, n2_id2..[SEP]..[SEP]
slot_seqlen = self.config.max_seqlen
final_feats = []
for index in inputs:
term_ids = L.gather(multi_term_ids, index, overwrite=False)
position_ids = v3_build_position_ids(term_ids, slot_seqlen)
sent_ids = v3_build_sentence_ids(term_ids, slot_seqlen)
# 将需要计算的超长文本,使用Ernie提取CLS位置的语义表达
ernie_model = ErnieModel(self.config.ernie_config)
cls_feat, _ = ernie_model(term_ids, sent_ids, position_ids)
feature = linear(cls_feat, self.config.hidden_size, "v3_final_fc")
feature = L.l2_normalize(feature, axis=1)
final_feats.append(feature)
return final_feats














 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









