







文章目录
一、机器学习生命周期和部署概述
1. 概述
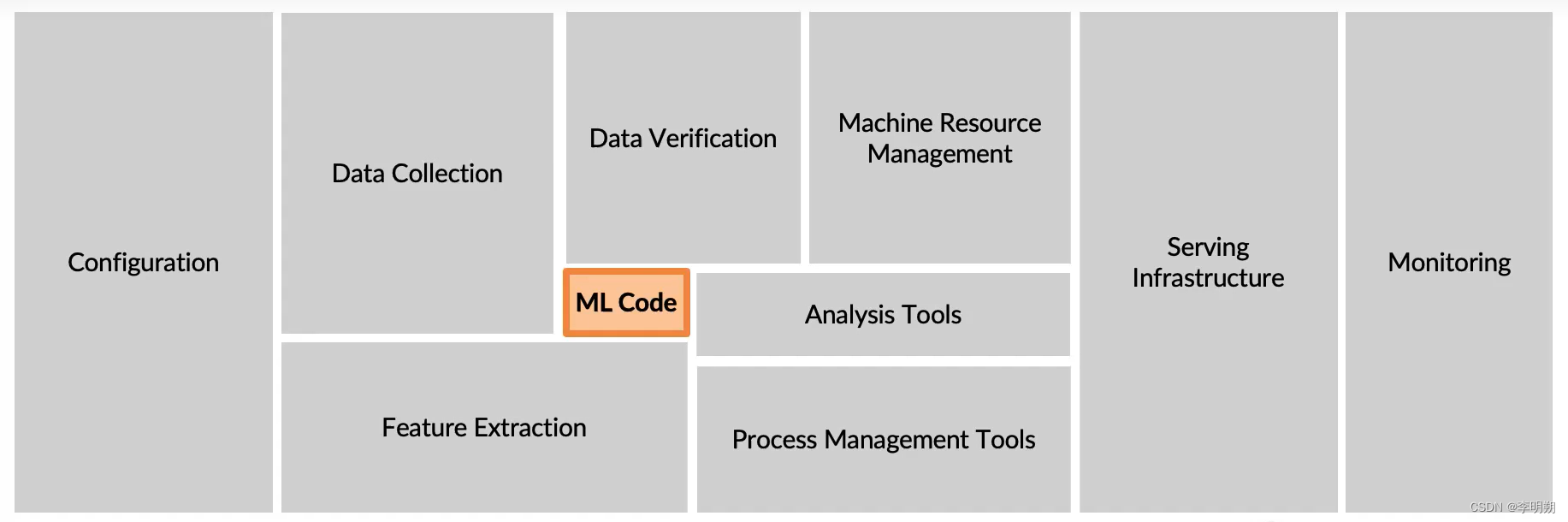
下图展示了一个机器学习项目包含的内容
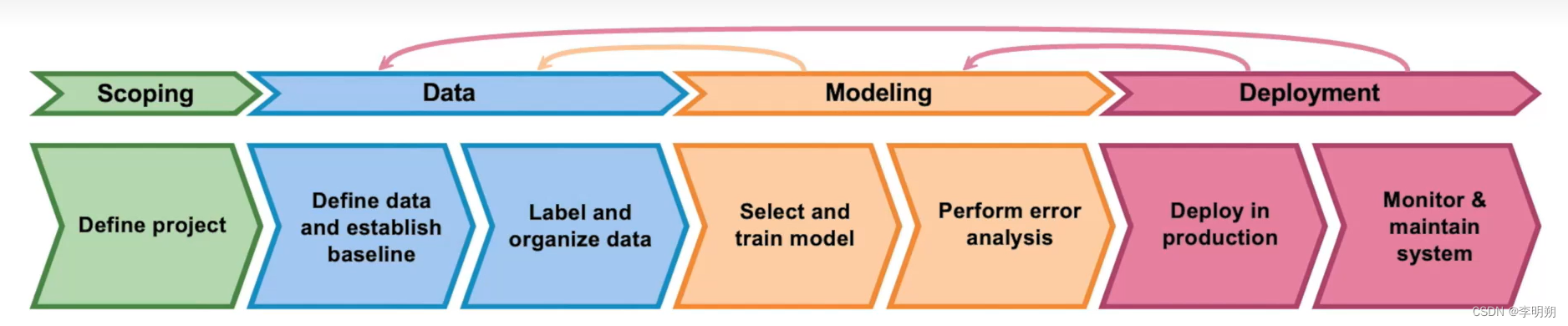
2.机器学习的生命周期
机器学习项目的生命周期包括:
- 定义项目:确定模型的输入输出
- 数据:收集数据、标记数据
- 建模:训练模型、误差分析
- 部署:部署、监控、维护
3. 机器学习模型部署的挑战
-
概念偏移(concept drift)或数据偏移(data drift):当模型部署完成后数据的分布发生变化
- 逐渐变化:例如语音识别中年轻人的样本比重逐渐增多
- 瞬间变化:例如由于新冠大流行,信用卡反诈骗系统失灵了因为个人购买方式发生了巨大变化,由线下购物转为线上购物
数据偏移通常指数据本身发生变化,概念偏移通常指x->y的过程发生变化。
-
软件设计时的要求,包括
- 实时处理/批处理
- 云/边缘
- 计算资源是否足够
- 延迟、QPS(query per second)
- 日志记录
- 安全和隐私
4. 项目部署模式
常见部署用例:
- 新产品,新功能:常见的设计模式是先启动少量流量,再逐渐增加流量
- 使用自动化/协助方法完成已有任务:
- 代替之前的机器学习系统
核心思想:监控和回滚(在系统无法工作时回滚到上一个版本)
部署模式:
- 影子模式(shadow mode):在初期我们使用影子模式部署,在这个模式中,机器学习算法和人类同时对某任务进行判断,我们会采取人类的判断作为结果。这样做的目的是收集有关学习算法和人类判断进行对比的数据。
- canary deployment:在中期我们将5%左右的流量交给机器学习算法进行决策并监控算法的好坏。之后可以逐步增加流量来让机器学习算法进行决策。
- blue green deployment:蓝色代表旧版本,绿色代表新版本,我们通过路由来对版本之间进行迅速切换。优点是方便进行回滚。
自动化程度分类:仅人工->影子模式->ai辅助->半自动->全自动
5. 项目监控
使用dashboard来监控系统的一些指标。
常见的监控指标包括:
- 软件指标:内存、计算、延迟、生产量和系统负载
- 输入指标:平均输入长度、平均输入量、缺失值数量、平均图像亮度。主要观察输入分布是否发生变化。
- 输出指标:返回空值次数、CTR。主要用于判断输出是否发生某种形势的改变。
部署/监控和建模类似,是一个迭代的过程。
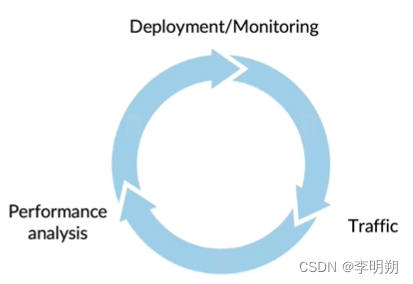
我们通过设定警告阈值来进行监控。
二、建模
AI系统=数据+模型,模型的训练是一个迭代的过程
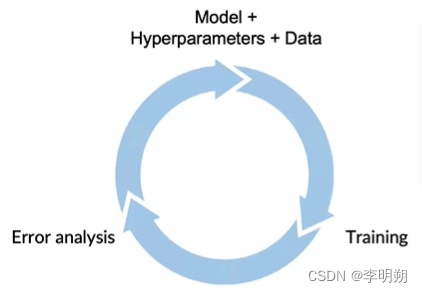
1.模型训练的挑战
- 在重要样本上的表现:例如在网络搜索中,将搜索分为两种,一种是信息检索,例如搜索附近的餐厅,另一种是导航式检测,例如搜索youtube,很显然,我们希望后者更为精准。因此如果我们只是用平均准确率会导致模型在后者表现的很糟糕,解决方法是为后者添加更多的权重,
- 在关键部分的表现:例如在贷款发放中,我们不能因为性别、地理位置、语言等方面产生歧视。
- 在稀有分类的表现:例如在医疗诊断问题中,99%的样本都是健康的人,而我们更应该关注剩余1%的样本。
2. 误差分析
我们可以在误差分析中对样本打上不同的标签,以视觉检查为例,标签可以是特定的类型标签(与y有关),可以是图片的质量(模糊度、光照 ),可以是一些元数据(手机品牌、工厂)。
对于不同的标签,我们可以进行分析,例如该标签下的样本误分类率、有多少错误样本包含该标签
3. 性能审计
审计框架:检查准确率、偏差或其他问题。步骤包括
- 寻找系统可以出现误差的方法
- 在数据子集的表现(某一种族、某一性别)
- 准确率、召回率
- 在稀有类别的表现
- 建立评价指标来评估一部分数据在这些问题上的表现
- 在业务逻辑进行分析
4. 以数据为中心的ai
使用工具来增加数据的质量,进而训练模型。对于非结构化数据我们可以进行数据增强,对于结构化数据我们可以增加特征。
数据增强的目的:创建更多现实的样本,在创建新样本中,我们时刻要注意一下问题
- 样本是否看起来真实
- x->y的映射是否发生改变
- 算法在新数据的表现是否好
另外,我们需要对不同的试验进行跟踪,记录每次试验的模型、超参数和结果。
三、数据定义和baseline
数据标注时可能会对数据有不同的标注,如下图所示

这三种标注方法都有一定意义,但如果数据集中包含了这三种方法,学习到的模型可能会很糟糕。
提高标签一致性的方法:
- 多个数据标注人员标注同一张图
- 创建一个新标签
数据标注的方法:内部自己标注、外包、众包。
1. HLP(人类水平性能)
HLP是指人类在某项任务中可以达到的水平。
HLP的用途包括:
- 在学术界作为benchmark
- 为工业项目制定更合理的目标
- 证明机器学习系统可以比人类在某一任务上更加优秀
提高标签一致性可以提高HLP
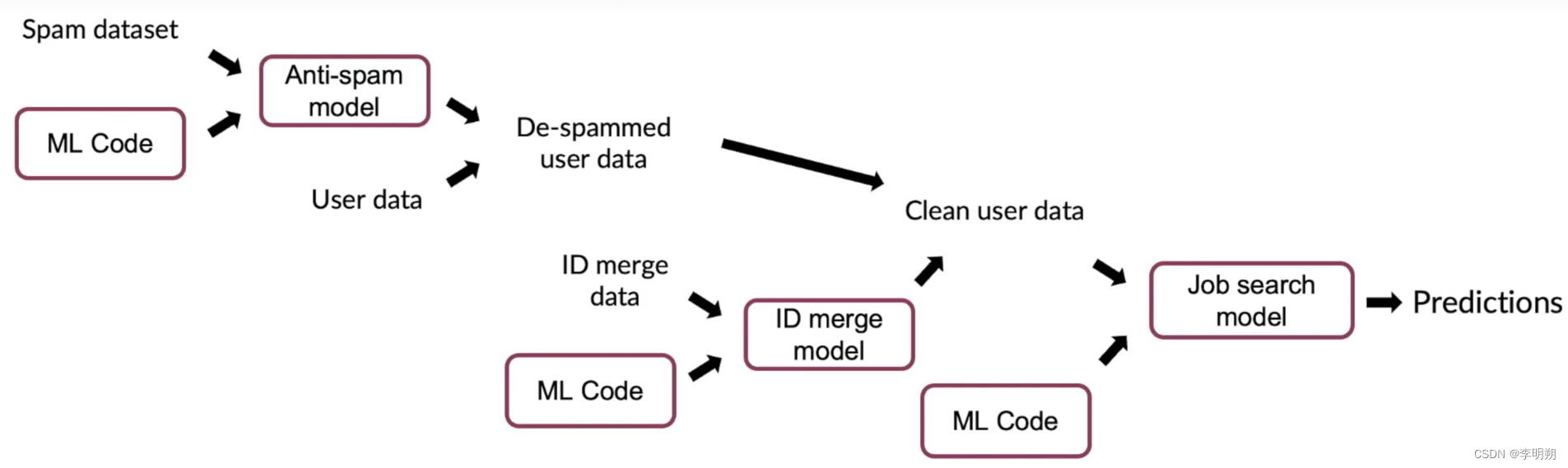
2. 数据管道
下图是一个预测用户是否找工作的pipelne
企业存储解决方案:数据仓库、数据湖
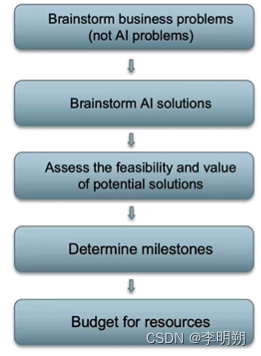
3. 范围确定(scoping)
范围确定流程:
可行性分析:使用外部基准(文献、其他公司)
4. 数据标注的方法
- 过程反馈:监控系统输出并获取系统反馈作为标签。例如CTR(点击率预估)
- 人工标注
- 半监督学习:使用小部分已标注的数据集合大量未标注数据集结合起来进行训练,前提是不同的标签类会聚类到一起或特征空间中含有可识别的结构
- 主动学习:通过智能采样选取数据集中最有用的数据子集进行标注并训练,继续选择有用的数据子集不断迭代。主动学习的采样技术包括边界采样、基于聚类的采样
- 弱监督:利用含有噪声、不准确的标签来进行训练,例如Snorfel方法
5. 特征工程
文本数据预处理方法:词干提取、词性还原、TF-IDF、n-grams、词嵌入等
图像数据预处理方法:翻转、模糊等
特征工程方法:
- 数值型变量:缩放、归一化、标准化(z-score)
- 类别型变量:分桶、词袋模型
- 降维:PCA、t-SNE、UMAP
- 特征组合:将多个特征组合成一个新特征
特征选择方法:
- 过滤法:使用相关性检测去除冗余特征,例如皮尔逊相关系数、单变量特征选择、互信息、斯皮尔曼相关系数、F-检验、卡方检验
- 包装法:选择特征的一个子集进行训练,根据训练结果选择新的子集不断迭代,最终得到需要的特征
- 前向选择:从一个特征开始,每次迭代增加一个特征,选择效果最好的特征,直到效果不再变好
- 反向选择:首先选择所有特征,每次迭代删除一个特征,选择效果最好的特征,直到结果不再变好
- 递归特征消除:使用模型来评估特征的重要性,删除最不重要的特征
- 嵌入法:L1正则化、使用树模型来计算特征重要性
一些高级数据增强技术:
- 半监督数据增强:例如UDA、使用GAN进行数据增强
- 基于策略的数据增强:AutoAugment
6. 元数据
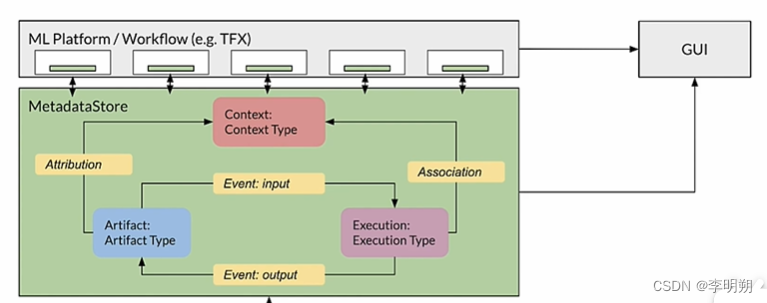
机器学习管道中的每一次运行都会产生元数据,包含各种管道组件执行或训练时产生的信息。当运行出现问题时,我们可以利用这些元数据进行debug。
机器学习元数据库:用来追踪机器学习管道组件之间的元数据 ML Metadata,一些数据实体可视为单元,每个单元包含:
- artifacts:数据的基本单元,作为组件的输入或组件的输出
- execution:记录数据管道中的每个组件的执行情况
- context:工件和执行的分组关系















 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









