







案例3:各州累计病例分区统计
1、将美国疫情数据不同州的输出到不同文件中,属于同一个州的各个县输出到同一个结果文件中。
一、需求分析
输出到不同文件中–>reducetask有多个(>2)–>默认只有1个,如何有多个?—>可以设置,
job. setNumReduceTasks(N)—>当有多个reducetask意味着数据分区---->默认分区规则是什么? hashPartitioner–→>默认分区规则符合你的业务需求么?---->符合,直接使用—>不符合,自定义分区。
HashPartitioner默认规则
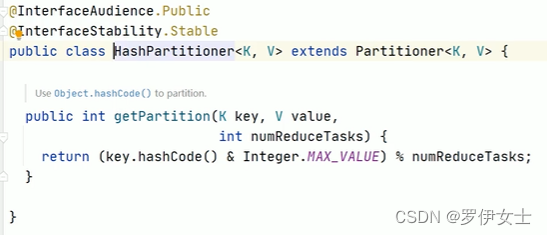
二、代码实现
(一)自定义分区代码
package mapreduce.partition;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.HashMap;
public class StatePartitioner extends Partitioner<Text,Text> {
//模拟美国各州的数据字典,实际中可以从redis进行读取加载,如果数据量不大,也可以创建数据集合保存
public static HashMap<String,Integer> stateMap= new HashMap<String, Integer>();
static {
stateMap.put("Alabama",0);
stateMap.put("Alaska",1);
stateMap.put("California",2);
}
/**
* todo 自定义分区器中分区规则的实现方法 只要getPartition返回的int一样,数据就会被分到同一个分区
* 同一个分区指的是数据到同一个reducetask处理
* k:state州 -------字符串===Text
* v:这一行内容 -------字符串整体,无需封装==Text
*/
@Override
public int getPartition(Text key, Text value, int numPartitions) {
Integer code = stateMap.get(key.toString());
if(code != null){
return code;
}else
return 3;
}
}
(二)StatePartitionMapper
package mapreduce.partition;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class StatePartitionMapper extends Mapper<LongWritable, Text,Text,Text> {
Text outKey = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、切割,为了拿到州
String[] lines = value.toString().split(",");
//2、以州作为key,参与分区,通过自定义分区,同一个州的数据到同一个分区同一个reducetask处理
String state = lines[2];
//3、赋值
outKey.set(state);
//4、写出去
context.write(outKey, value);
}
}
(三)StatePartitionReducer
package mapreduce.partition;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 因为state在那一行数据里,再输出那行数据没有意义,可以使用nullWritable
*/
public class StatePartitionReducer extends Reducer<Text,Text,Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values){
context.write(value,NullWritable.get());
}
}
}
(四)StatePartitionDriver
package mapreduce.partition;
import beans.CovidCountBean;
import mapreduce.CovidSum.CovidSumMapper;
import mapreduce.CovidSum.CovidSumReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 该类就是MapReduce程序客户端驱动类
* 主要是构造Job对象实例
* 指定各种组件属性:mapper、reducer类,输入输出的数据类型,输入输出的数据路径,提交job作业(job.submit())
*/
public class StatePartitionDriver {
public static void main(String[] args) throws Exception {
//创建驱动类
Configuration conf = new Configuration();
//构造job作业的实例,参数(配置对象,job名字)
Job job = Job.getInstance(conf, StatePartitionDriver.class.getSimpleName());
//设置mr程序运行的主类
job.setJarByClass(StatePartitionDriver.class);
//设置本次mr程序的mapper类型、reducer类型
job.setMapperClass(StatePartitionMapper.class);
job.setReducerClass(StatePartitionReducer.class);
//指定mapper阶段输出的key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//指定reducer阶段输出的key value数据类型,也是mr程序最终的输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//todo 设置程序Partition类; 注意:分区组件能够生效的前提是MapReduce程序中的reduceTask的个数 >=2
/**
* 探究: reducetask个数和分区个数之间的关系
* 正常情况下: reducetask个数 == 分区个数
* 特殊情况下: reducetask个数 > 分区个数 ====> 程序可以运行,但多有空文件产生,浪费性能
* reducetask个数 < 分区个数 ====> 程序直接报错:非法分区
*/
job.setNumReduceTasks(4);
job.setPartitionerClass(StatePartitioner.class);
//配置本次作业的输入数据路径和输出数据路径
Path inputPath = new Path(args[0]);
Path outputPath = new Path(args[1]);
//todo 默认组件 TextInputFormat TextOutputFormat
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job,outputPath);
//todo 判断输出路径是否已经存在,如果已经存在,先删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outputPath)){
fs.delete(outputPath,true); //递归删除
}
//最终提交本次job作业
//job.submit();
//采用waitForCompletion提交job,参数表示是否开启实时监视追踪作业的执行情况
boolean resultFlag = job.waitForCompletion(true);
//退出程序 和job结果进行绑定, 0是正常退出,1是异常退出
System.exit(resultFlag ? 0: 1);
}
}
视频链接:
https://www.bilibili.com/video/BV11N411d7Zh/?spm_id_from=333.999.0.0&vd_source=93d5a9dea4745391f195ebaad9df2db6
















 482
482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









