






目录
分类损失函数
1. 交叉熵损失函数
交叉熵损失函数常用于分类的任务中,与softmax搭配,softmax函数用于使多个类的预测值之和为1。
(参考:https://blog.csdn.net/b1055077005/article/details/100152102)
交叉熵损失函数来源于相对熵(KL散度),这是用于衡量两种分布(P、Q)之间的差异,如在机器学习中,P一般为真实分布,Q为预测分布。如对于某次预测的标签(真实分布)为:猫、狗、羊、猪为[1,0,0,0],预测分布为[0.7,0.2, 0.1,0.1]
KL散度与交叉熵损失函数的关系为:
K
L
散
度
=
交
叉
熵
−
信
息
熵
KL散度 = 交叉熵 - 信息熵
KL散度=交叉熵−信息熵
多分类的交叉熵损失函数公式:
H
(
p
,
q
)
=
−
∑
i
=
1
M
p
(
x
i
)
l
o
g
(
q
(
x
i
)
)
H(p,q) = -\sum_{i=1}^{M}p(x_{i})log(q(x_{i}))
H(p,q)=−i=1∑Mp(xi)log(q(xi))
其中,共有M类,p(xi)为第i类的真实分布(即label,如是该类,则为1,否则为0),q(xi)为预测为该类的概率。
常用的,二分类交叉熵损失函数:
H
(
p
,
q
)
=
−
(
p
∗
l
o
g
(
q
)
+
(
1
−
p
)
∗
l
o
g
(
1
−
q
)
)
H(p,q) = -(p*log(q)+(1-p)*log(1-q))
H(p,q)=−(p∗log(q)+(1−p)∗log(1−q))
回归损失函数
1. L1损失函数
若另残差r = f(x) - y,则
L
1
l
o
s
s
=
∣
r
∣
L1_{loss} = |r|
L1loss=∣r∣
也即平均绝对误差(MAE)损失函数:
M
A
E
=
1
n
∑
i
=
1
n
(
∣
y
i
^
−
y
i
∣
)
MAE = \frac{1}{n}\sum_{i=1}^{n}(\left | \hat{y_{i}}-y_{i} \right |)
MAE=n1i=1∑n(∣yi^−yi∣)
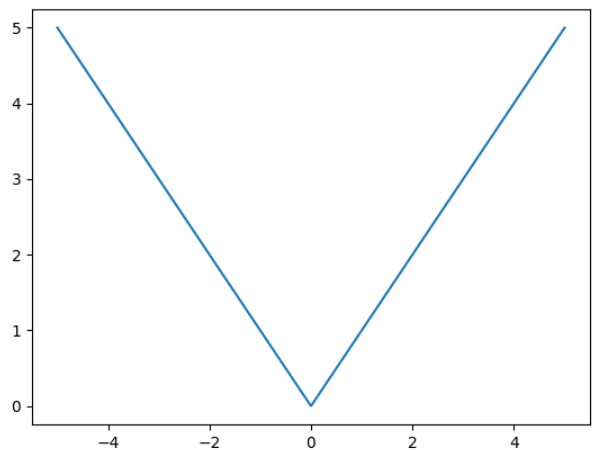
从图中可以发现L1 loss存在的问题,存在不可导点,因此出现了smooth L1 loss
2. L2损失函数
相对于L1 loss,一般在CNN中用L2 loss较多,因为L2的收敛速度较快,并且较为稳定,但鲁棒性不好,训练时容易跑飞。。
L
2
l
o
s
s
=
1
2
∣
r
∣
2
L2_{loss} = \frac{1}{2}|r|^2
L2loss=21∣r∣2
也即均方误差(MSE):
M
S
E
=
1
n
∑
i
=
1
n
(
∣
y
i
^
−
y
i
∣
)
2
MSE = \frac{1}{n}\sum_{i=1}^{n}(\left | \hat{y_{i}}-y_{i} \right |)^2
MSE=n1i=1∑n(∣yi^−yi∣)2
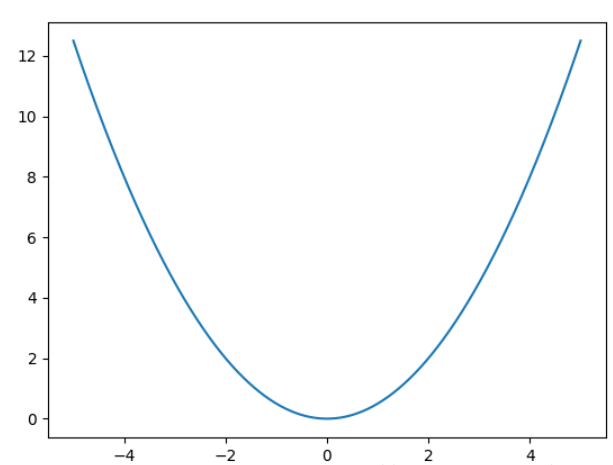
3. smooth L1 loss
针对L1 loss进行了平滑处理,
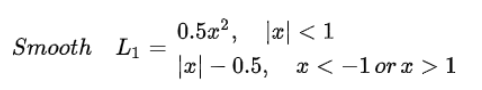

分割损失函数
2. dice loss
参考:https://blog.csdn.net/qq_34106574/article/details/95077597
dice loss本质上是衡量两个样本的重叠程度,指标范围为[0, 1],1代表完全重叠。
D
i
c
e
l
o
s
s
=
2
∣
A
⋂
B
∣
∣
A
∣
+
∣
B
∣
Dice_{loss} = \frac{2\left | A\bigcap B \right |}{\left | A \right |+\left | B \right |}
Diceloss=∣A∣+∣B∣2∣A⋂B∣
其中,A∩B以A与B的点乘表示,分母的A和B则分别以元素值相加之和表示。
计算示例:

2. Focal loss
Focal loss是何凯明在目标检测领域提出来的一种方法,专门用于解决类间不平衡的问题。
比如像YOLO划分网格,有的网格部分并无目标,即为负样本,并且在一幅图像的所有网格中,含目标的网格只是占少数,这种就造成了类间不平衡,可能会导致Loss过大,并将含正样本中计算的loss遮盖,不利于目标函数的收敛。
计算公式如下:
F
o
c
a
l
l
o
s
s
=
−
α
t
∗
(
1
−
p
t
)
γ
∗
l
o
g
(
p
t
)
Focal_{loss} = -\alpha _t*(1-p_t)^\gamma *log(p_t)
Focalloss=−αt∗(1−pt)γ∗log(pt)
其中,
p
t
=
{
p
,
i
f
y
=
1
1
−
p
,
o
t
h
e
r
w
i
s
e
p_t = \left\{\begin{matrix}p,\ if \ y=1\\1-p, \ otherwise\end{matrix}\right.
pt={p, if y=11−p, otherwise
α为权重系数,对于正样本α∈[0, 1],对于负样本为1-α,这种是常用的改进方法,focal loss更主要的是引入γ项的调节因子,γ∈[0, 5],调节项主要有两个作用,当网络错分类时,pt接近于0,1-pt接近于1,则公式基本不变,而当分类正确,pt接近1,大大降低了这种情况下的损失权重。
目标检测损失函数
参考:https://zhuanlan.zhihu.com/p/112640903
目标检测位置回归的loss的发展顺序是:
smooth L1 loss → IOU loss → GIOU loss → DIOU loss → CIOU loss
1. IOU loss
IOU loss类似于Dice loss,其定义如下:
I
O
U
l
o
s
s
=
∣
A
⋂
B
∣
∣
A
∣
+
∣
B
∣
−
∣
A
⋂
B
∣
IOU_{loss} = \frac{\left | A\bigcap B \right |}{\left | A \right |+\left | B \right |-\left | A\bigcap B \right |}
IOUloss=∣A∣+∣B∣−∣A⋂B∣∣A⋂B∣
缺点是当目标框与预测框不重合时,IOU loss无法反映距离的远近。
2. GIOU loss
GIOU改善了IOU loss的不重合时无法反映远近的问题。
G
I
O
U
l
o
s
s
=
I
O
U
−
∣
A
c
−
U
∣
∣
A
c
∣
GIOU_{loss} = IOU - \frac{\left | A_c-U \right |}{\left | A_c \right |}
GIOUloss=IOU−∣Ac∣∣Ac−U∣
其中,Ac为包含真实框与预测框的最小矩形,U为A、B的并集,相当于计算非目标框与预测框的部分所占比重,这样就可以度量非重合时的距离远近。
缺点是,对尺度不敏感。、
3. DIOU loss
好的目标检测损失函数应当考虑 中心点距离、长宽比、重叠面积,DIOU未考虑长宽比,CIOU都考虑了。
D
I
O
U
l
o
s
s
=
I
O
U
−
ρ
2
(
c
,
c
′
)
d
2
DIOU_{loss} = IOU - \frac{\rho ^2(c,{c}')}{d^2}
DIOUloss=IOU−d2ρ2(c,c′)
其中,ρ(c,c’)为真实框与预测框中心点距离,d为包含两个框最小矩形的对角线距离。
4. CIOU loss
CIOU是在DIOU的基础上增加了一个惩罚因子。
C
I
O
U
l
o
s
s
=
1
−
(
I
O
U
−
ρ
2
(
c
,
c
′
)
d
2
)
+
α
v
CIOU_{loss} = 1 - (IOU - \frac{\rho ^2(c,{c}')}{d^2}) + \alpha v
CIOUloss=1−(IOU−d2ρ2(c,c′))+αv
这个因子将真实框与预测框的长宽比都考虑进去了,其中α为权重,v用于衡量长宽一致性。
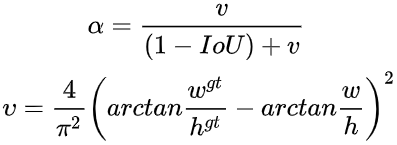














 1187
1187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









