






文章目录
1.单层神经网络实现(CH3.7)
'''
PyTorch实现iris数据集的分类
'''
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
from sklearn.datasets import load_iris
from torch.autograd import Variable
from torch.optim import SGD
#判断GPU是否可用
use_cuda = torch.cuda.is_available()
print('user_cuda: ',use_cuda)
use_cpu = torch.fbgemm_is_cpu_supported()
print('user_cpu: ',use_cpu)
#加载数据集
iris = load_iris()
print(iris.keys())
#dict_key =(['target_names','data','feature_names','DESCR','target'])
#数据预处理
x = iris['data'] #特征信息
y = iris['target'] #目标分类
print(x.shape) #(150,4)
print(y.shape) #(150,)
print(y)
x = torch.FloatTensor(x)
y = torch.LongTensor(y)
x,y = Variable(x),Variable(y)
#网络模型定义,需要继承module
class Net(torch.nn.Module):
#初始化函数,接受自定义输入特征维数,隐含层特征维数,输出层特征维数
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(n_feature,n_hidden) #一个线性隐含层
self.predict = torch.nn.Linear(n_hidden,n_output) #线性输出层
#前向传播过程
def forward(self, x):
x = torch.tanh(self.hidden(x)) #tanh的效果比sigmoid差很多,原因未知
x = self.predict(x)
out = F.log_softmax(x,dim=1)
return out
#网络实例化,并查看网络结构
#iris中输入特征4维,隐含层和输出层可以自己选择
net = Net(n_feature=4,n_hidden=5,n_output=3)
print(net)
#判断GPU/是否可用CPU,若可用,则放到相应的处理器上面
x = x.cpu()
y = y.cpu()
net = net.cpu()
#设置学习率为0.5
optimizer = SGD(net.parameters(),lr=0.5)
px,py = [],[] #记录绘制的数据
for i in range(1000):
#数据集传入网络前向计算
prediction = net(x)
#计算loss
loss = F.nll_loss(prediction,y)
#清除网络状态
optimizer.zero_grad()
#loss反向传播
loss.backward()
#更新参数
optimizer.step()
#打印每次迭代的损失情况:
print(i,'loss: ',loss.item())
px.append(i)
py.append(loss.item())
#每十次迭代绘制训练动态
if i%10 == 0:
#动态画出loss的走向
plt.cla()
plt.plot(px,py,'r-',lw=1)
plt.text(0,0,'Loss=%.4f' %loss.item(),fontdict={'size':20,'color':'red'})
plt.pause(0.1)
plt.savefig('E:\Pycharm\project\project1\ tanh训练结果.png')
plt.show()
训练结果:
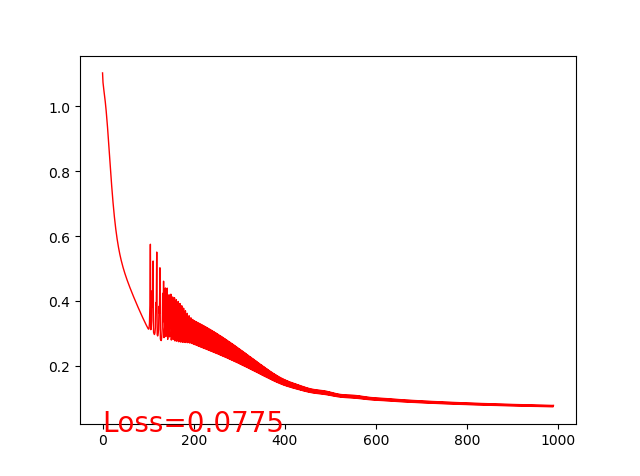
2.(optimizer)优化器的使用示例(CH4.3)
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
torch.manual_seed(1) #保证结果可复现
LR = 0.01
BATCH_SIZE = 20
EPOCH = 10
#生成数据
x = torch.unsqueeze(torch.linspace(-1,1,1500),dim=1)
y = x.pow(3) + 0.1*torch.normal(torch.zeros(*x.size()))
#数据画图
plt.scatter(x.numpy(),y.numpy())
plt.show()
#把数据转化为torch类型
torch_dataset = Data.TensorDataset(x,y)
loader = Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=0,) #值为0,单线程,多线程要在main函数下调用
#定义模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1,20)
self.predict = torch.nn.Linear(20,1)
def forward(self,x):
#pdb.set_trace
x = torch.relu(self.hidden(x)) #隐含层的激活函数
x = self.predict(x) #输出层,线性输出
return x
#不同的网络模型
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_AdaGrad = Net()
net_Adam = Net()
nets = [net_SGD,net_Momentum,net_AdaGrad,net_RMSprop,net_Adam]
#不同的优化器
opt_SGD = torch.optim.SGD(net_SGD.parameters(),lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(),lr=LR,momentum=0.8)
opt_AdaGrad = torch.optim.Adagrad(net_AdaGrad.parameters(),lr=LR)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR,alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))
optimizers = [opt_SGD,opt_Momentum,opt_AdaGrad,opt_RMSprop,opt_Adam]
loss_func = torch.nn.MSELoss()
losser_his = [[],[],[],[],[]] #存储loss数据
#模型训练
for epoch in range(EPOCH):
print('Epoch: ',epoch)
for step,(batch_x,batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net,opt,l_his in zip(nets,optimizers,losser_his):
output = net(b_x)
# pdb.set_trace() #断点
loss = loss_func(output,b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.item())
labels = ['SGD','Momentum','Adagrad','RMSprop','Adam']
for i,l_his in enumerate(losser_his):
plt.plot(l_his,label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0,0.2))
plt.show()
训练结果如下:
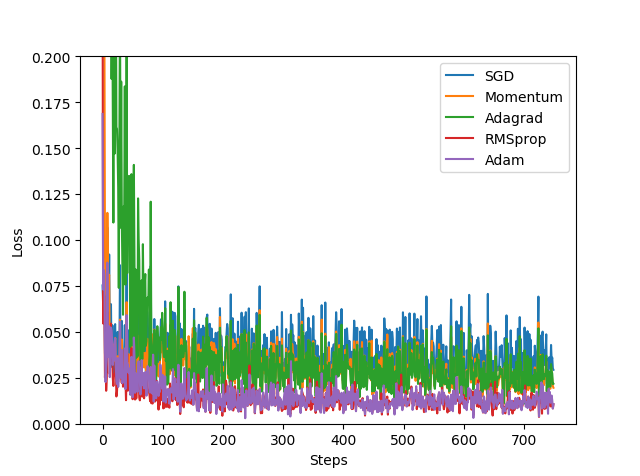
3.深度神经网络实现
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transform
from torch.autograd import Variable
#配置参数
torch.manual_seed(1) #确保结果可重复
input_size = 784
hidden_size = 500
num_classes = 10
num_epochs = 5 #训练次数
batch_size = 100 #批量处理数据大小
learning_rate = 0.001
#加载MNIST数据
train_dataset = dsets.MNIST(root='./data', #数据保持的位置
train=True, #训练集
transform=transform.ToTensor(), #将数据范围为0~255的PIT.Image,转化为0~1的Tensor
download=True)
test_dataset = dsets.MNIST(root='./data',
train=False, #测试集
transform=transform.ToTensor())
#数据批处理
#尺寸大小为batch_size
#在训练集中,shuffle必须为True,表示次序随机
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
#创建DNN模型
#定义神经网络模型
class Net(nn.Module):
def __init__(self,input_size,hidden_size,num_classes):
super(Net,self).__init__()
self.fc1 = nn.Linear(input_size,hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size,num_classes)
def forward(self,x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
net = Net(input_size,hidden_size,num_classes)
print(net)
#训练流程
#定义loss和optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=learning_rate)
#开始训练
for epoch in range(num_epochs):
for i,(images,labels) in enumerate(train_loader): #批处理
images = Variable(images.view(-1,28*28))
labels = Variable(labels)
#forward + backard + optimze
optimizer.zero_grad() #梯度清零,以免影响其他batch批
outputs = net(images) #前向传播
loss = criterion(outputs,labels)
loss.backward() #后向传播,计算梯度
optimizer.step()
if(i+1) % 100 ==0:
print('Epoch [%d/%d],Step[%d/%d], Loss :%.4f'%(epoch+1,num_epochs,i+1,len(train_dataset)//batch_size,loss.item()))
#在测试集上验证模型
correct = 0
total = 0
for images,labels in test_loader: #test set 批处理
images = Variable(images.view(-1,28*28))
outputs = net(images)
_,predicted = torch.max(outputs.data,1) #预测结果
#predicted = Variable(predicted)
total += labels.size(0) #正确结果
correct += (predicted == labels).sum() #正确结果总数
print('Accuracy of the network on the 10000 test images: %d %%' % (100*correct/total))
4.MNIST数据集上卷积神经网络的实现(CH5.3)
#配置库
import torch
from torch import nn,optim
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
#配置参数
torch.manual_seed(1)
batch_size = 128 #批处理大小
learning_rate = 1e-2
num_epocher = 10 #训练次数
#加载MNIST数据
train_dataset = datasets.MNIST(
root='./data',
train = True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(
root='./data',
train=False, #测试集
transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=batch_size,shuffle=False)
#定义卷积神经网络模型
class Cnn(nn.Module):
def __init__(self,in_dim,n_class):
super(Cnn,self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_dim,6,3,stride=1,padding=1), #28x28
nn.ReLU(True),
nn.MaxPool2d(2,2), #14x14,池化层减小尺寸
nn.Conv2d(6,16,5,stride=1,padding=0), #10x10x16
nn.ReLU(True),
nn.MaxPool2d(2,2) #5x5x16
)
self.fc = nn.Sequential(
nn.Linear(400,120), #400=5*5*16
nn.Linear(120,84),
nn.Linear(84,n_class)
)
def forward(self,x):
out = self.conv(x)
out = out.view(out.size(0),400)
out = self.fc(out)
return out
model = Cnn(1,10) #图片大小28*28,10为数据种类
#打印模型
print(model)
#模型训练
#定义loss和optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=learning_rate)
#开始训练
for epoch in range(num_epocher):
running_loss = 0.0
running_acc = 0.0
for i,data in enumerate(train_loader,1):
img,label = data
img = Variable(img)
label = Variable(label)
#前向传播
out = model(img)
print(out)
loss = criterion(out,label) #loss
running_loss += loss.item() * label.size(0)
#total loss ,由于loss是取batch均值的,因此,需要把batch size成回去
_,pred = torch.max(out,1) #预测结果
num_correct = (pred == label).sum() #正确结果的数量
#accuracy = (pred == label).float().mean() #正确率
running_acc += num_correct.item() #正确结果的总数
#后向传播
optimizer.zero_grad() #梯度清零
loss.backward() #后向传播计算梯度
optimizer.step() #利用梯度更新W,b参数
#打印一个循环后,训练集合上的loss和正确率
print('Train{} epoch, Loss: {:.6f},Acc: {:.6f}'.format(epoch+1,running_loss / (len(train_dataset)),running_acc / (len(train_dataset))))
#测试集中测试识别率
#模型测试
model.eval() #需要说明是否模型测试
eval_loss = 0
eval_acc = 0
for data in test_loader:
img,label = data
img = Variable(img,volatile=True) #with torch.no_grad():这里的volatile在新的版本被移除了
#volatile用于测试是否不调用backward
#测试中不需要label= Variable...
out = model(img) #前向算法
loss = criterion(out,label) #计算loss
eval_loss += loss.item() * label.size(0) #total loss
_,pred = torch.max(out,1) #预测结果
num_correct = (pred == label).sum() #正确结果
eval_acc += num_correct.item() #正确结果总数
print('Test Loss:{:.6f},Acc: {:.6f}'.format(eval_loss/ (len(test_dataset)),eval_acc * 1.0/(len(test_dataset))))
#print('Accuracy: ' % (accuracy))
5.自编码器实现(CH6.2)
#加载库
import os
import pdb
import torch
import torchvision
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
from torchvision.utils import save_image
from torchvision import datasets
import matplotlib.pyplot as plt
#配置参数
torch.manual_seed(1)
batch_size = 128
learning_rate = 1e-2
num_epochs = 10
#下载数据
train_dataset = datasets.MNIST(
root='./data',
train=True,
transform=transforms.ToTensor(),
download=False
)
test_dataaset = datasets.MNIST(
root='./data',
train=False,
transform=transforms.ToTensor()
)
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_dataaset,batch_size=10000,shuffle=False)
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28,1000),
nn.ReLU(True),
nn.Linear(1000,500),
nn.ReLU(True),
nn.Linear(500,250),
nn.ReLU(True),
nn.Linear(250,2)
)
self.decoder = nn.Sequential(
nn.Linear(2,250),
nn.ReLU(True),
nn.Linear(250,500),
nn.ReLU(True),
nn.Linear(500,1000),
nn.ReLU(True),
nn.Linear(1000,28*28),
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
model = autoencoder()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(
model.parameters(),lr=learning_rate,weight_decay=1e-5
)
#模型训练
for epoch in range(num_epochs):
for data in train_loader:
img,_ = data
img = img.view(img.size(0),-1)
img = Variable(img)
#前向传播
output = model(img)
print(output)
loss = criterion(output,img)
#后向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('epoch[{}/{}],loss:{:.4f}'.format(epoch+1,num_epochs,loss.item()))
#测试模型
model.eval()
eval_loss = 0
for data in test_loader: #批处理
img,label = data
img = img.view(img.size(0),-1)
img = Variable(img,volatile=True)
label = Variable(label,volatile=True)
out = model(img) #前向算法
y = (label.data).numpy()
plt.scatter(out[:,0],c=y)
plt.colorbar()
plt.title('autocoder of MNIST test dataset')
plt.show()
训练结果如下:

6.基于自编码器的图形去噪
#去噪编码器
import torch
import torch.nn as nn
import torch.utils as utiles
from torch.autograd import Variable
import torchvision.datasets as dset
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
#配置参数
torch.manual_seed(1)
n_epoch = 1000
batch_size = 100
learning_rate = 0.0002
#下载图片训练集
mnist_train = dset.MNIST(root='./data',train=True,transform=transforms.ToTensor(),target_transform=None,download=False)
train_loader = torch.utils.data.DataLoader(dataset=mnist_train,batch_size=batch_size,shuffle=True)
#encoder模型设置
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, 3, padding=1), # batch x 32 x 28 x 28
nn.ReLU(),
nn.BatchNorm2d(32),
nn.Conv2d(32, 32, 3, padding=1), # batch x 32 x 28 x 28
nn.ReLU(),
nn.BatchNorm2d(32),
nn.Conv2d(32, 64, 3, padding=1), # batch x 64 x 28 x 28
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(64, 64, 3, padding=1), # batch x 64 x 28 x 28
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(2, 2) # batch x 64 x 14 x 14
)
self.layer2 = nn.Sequential(
nn.Conv2d(64, 128, 3, padding=1), # batch x 128 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(128),
nn.Conv2d(128, 128, 3, padding=1), # batch x 128 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, padding=1), # batch x 256 x 7 x 7
nn.ReLU()
)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(batch_size, -1)
return out
encoder = Encoder()
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.layer1 = nn.Sequential(
nn.ConvTranspose2d(256, 128, 3, 2, 1, 1), # batch x 128 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 128, 3, 1, 1), # batch x 128 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 64, 3, 1, 1), # batch x 64 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 64, 3, 1, 1), # batch x 64 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(64)
)
self.layer2 = nn.Sequential(
nn.ConvTranspose2d(64, 32, 3, 1, 1), # batch x 32 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(32),
nn.ConvTranspose2d(32, 32, 3, 1, 1), # batch x 32 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(32),
nn.ConvTranspose2d(32, 1, 3, 2, 1, 1), # batch x 1 x 28 x 28
nn.ReLU()
)
def forward(self, x):
out = x.view(batch_size, 256, 7, 7)
out = self.layer1(out)
out = self.layer2(out)
return out
decoder = Decoder()
#Loss函数和优化器
parameters = list(encoder.parameters())+list(decoder.parameters())
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(parameters,lr=learning_rate)
#添加噪声
noise = torch.rand(batch_size,1,28,28)
for I in range(n_epoch):
for image,label in train_loader:
image_n = torch.mul(image+0.25,0.1*noise)
image = Variable(image)
image_n = Variable(image_n)
optimizer.zero_grad()
output = encoder(image_n)
output = decoder(output)
loss = loss_func(output,image)
loss.backward()
optimizer.step()
break
print('epoch [{}/{}],loss: {:.4f}'.format(I+1,n_epoch,loss.item()))
img = image[0]
input_img = image_n[0]
output_img = output[0]
origin = img.data.numpy()
inp = input_img.data.numpy()
out = output_img.data.numpy()
plt.figure('denoising autoencoder')
plt.subplot(131)
plt.imshow(origin[0],cmap='gray')
plt.subplot(132)
plt.imshow(inp[0],cmap='gray')
plt.subplot(133)
plt.imshow(out[0],cmap='gray')
plt.show()
print(label[0])
#loss = 0.0164
训练结果如下:
1.训练30次
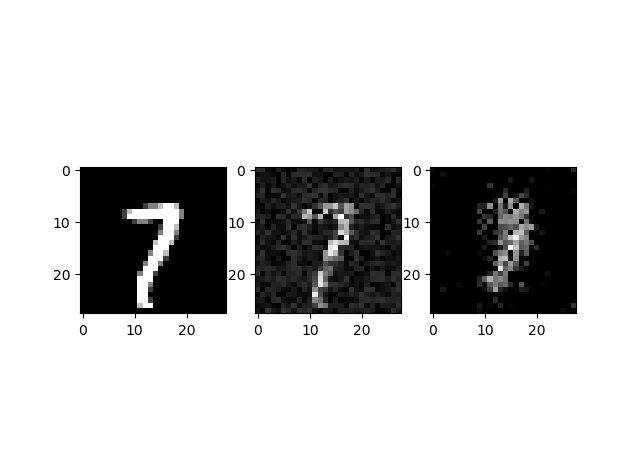
2.训练100次

3.训练200次

4.训练 1000次

7.PyTorch实现PCA(CH6.1)
PCA的基本原理是从大量数据中找到少量的主成分变量,从而在数据维度降低的情况下尽可能地保存原始数据信息,实现减少数据量,提高数据处理能力。以下是PyTorch实现PCA:
from sklearn import datasets
import torch
import numpy as np
import matplotlib.pyplot as plt
def PCA(data,k=2):
#preprocess the data
X = torch.from_numpy(data)
X_mean = torch.mean(X,0)
X = X - X_mean.expand_as(X)
#svd
U,S,V = torch.svd(torch.t(X))
return torch.mm(X,U[:,:k])
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_PCA = PCA(X)
pca = X_PCA.numpy()
plt.figure()
color = ['red','green','blue']
for i, target_name in enumerate(iris.target_names):
plt.scatter(pca[y==i,0],pca[y==i,1],label = target_name,color=color[i])
plt.legend()
plt.title('PCA of IRIS dataset')
plt.show()














 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









