






相比于全连接神经网络,卷积神经网络在分类任务上具有更好的表现,识别准确率更高,在大型数据集上面表现更为突出,本文以MNIST数据集为例,构建包含两层卷积层的卷积神经网络,以下是具体代码:
1. 配置库文件
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
2. 导入数据库
# 下面一行是在线加载方式
# mnist = tf.keras.datasets.mnist
# 下面两行是加载本地的数据集
datapath = r'E:\Pycharm\project\project_TF\.idea\data\mnist.npz'
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data(datapath)
3. 数据预处理
由于导入的为60000* 28* 28 的数据,全连接网络应reshape为60000* 784(也即打平的作用Flatten()), 卷积网络则为60000* 28 * 28*1(黑白单通道),因此需要进行数据预处理。
# 数据预处理
x_train = x_train.reshape(x_train.shape[0],28,28,1).astype('float32')
x_test = x_test.reshape(x_test.shape[0],28,28,1).astype('float32')
# 归一化
x_train = tf.keras.utils.normalize(x_train, axis=1)
x_test = tf.keras.utils.normalize(x_test, axis=1) #归一化
4.建立卷积神经网络结构模型
建立两层卷积层和两层池化层的卷积神经网络。其中,第一层卷积核深度(个数)16,大小为5 * 5,same的填充是指输出图像大小与输入一致(这一点比PyTorch简便一点);第二层卷积核深度为36,以提取更高维度的信息,大小为5 * 5。一般来说,最大池化层比平均池化层在分类上表现更好。
model = keras.models.Sequential([
layers.Conv2D(filters=16, kernel_size=(5,5), padding='same',
input_shape=(28,28,1), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(filters=36, kernel_size=(5,5), padding='same',
activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(10,activation='softmax')
])
#打印模型
print(model.summary())
网络结构模型打印出来如下:
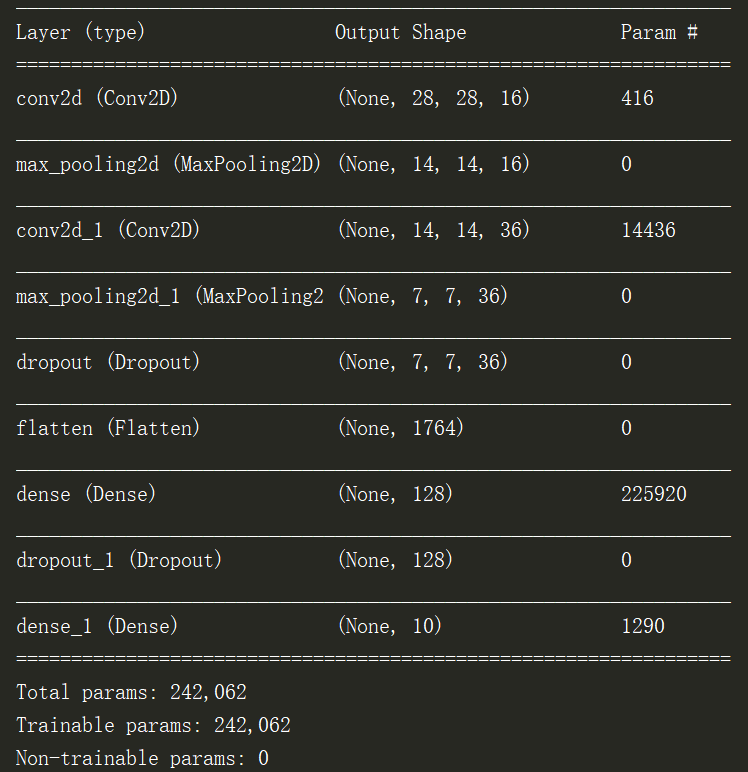
5.模型编译及训练
损失函数使用交叉熵损失函数,优化器使用adam;训练10个epoch和128的batch_size。
#训练配置
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
#开始训练
model.fit(x=x_train, y=y_train, validation_split=0.2, ##validation_split是指将一部分作为验证集使用,0.2代表80%的数据作为训练集,20%作为验证集
epochs=10, batch_size=128, verbose=1) #verbose=1代表显示训练过程
6. 测试集验证
val_loss, val_acc = model.evaluate(x_test, y_test) # model.evaluate输出计算的损失和精确度
print('Test Loss:{:.6f}'.format(val_loss))
print('Test Acc:{:.6f}'.format(val_acc))
整个程序到此结束了。
7. 测试结果
在cpu环境下,每个epoch运行完成需要70s左右。最终训练的平均准确率为:98.62%,平均Loss为:0.0439。而在测试集中,识别的准确率达到99.07%,Loss为0.0277。与上一篇的全连接神经网络的97.87%相比,准确率有所上升。















 4044
4044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









