






#NeurIPS #
今天分享的是NeurIPS 2021的一篇论文《神经成像时空回归模型的有效分层贝叶斯推理》
原文链接:https://arxiv.org/abs/2111.01692

摘要
神经影像学及其他领域的一些问题需要对多任务稀疏层次回归模型的参数进行推断,例如M/EEG逆问题、基于任务的功能磁共振成像分析的神经编码模型、气候科学。在这些领域中,需要推断的模型参数和测量噪声都可能表现出复杂的时空结构。现有的工作要么忽略了时间结构,要么推理方案需要的计算量很大。为了克服这些限制,作者设计了一个新的、灵活的层次贝叶斯框架,在其中模型参数、噪声的时空动力学被建模为具有克罗内克乘积的协方差结构。作者框架中的推理基于优化-最小化优化算法,并保证了收敛性。作者提出的高效算法针对时间自协方差矩阵利用了黎曼几何原理。对于由托普利茨矩阵描述的平稳动力学,采用了循环嵌入理论。作者证明了凸边界的性质,并推导了所得算法的更新规则。通过对来自M/EEG的合成和真实的神经数据上进行实验,作者证明了他们的方法可以提高性能。
1.介绍
在神经科学、神经成像等领域,经常对回归问题使用概率图形模型,其中模型参数和测量噪声都可能具有复杂的时空相关结构。本文的重点是脑源成像(BSI),即利用非侵入性磁电或脑电图(M/EEG)传感器重建脑源活动。虽然之前在BSI回归问题中已经提出了许多包含时空相关性的生成模型,但推理解决方案要么实施了特定的简化和模型约束,要么总体上忽略了时间相关性,因此没有完全解决其固有的时空问题结构。
2.贡献
- 作者提出了一种新的和有效的算法框架,使用Type-II贝叶斯回归,明确地考虑了模型系数和测量噪声的时空协方差结构。
- 作者重点研究了脑源重建中的M/EEG逆问题,采用了一种多任务回归的方法,并将脑源重建问题表述为一个概率生成模型。
- 作者对具有克罗内克结构的协方差矩阵,利用黎曼流形上测地线凸性的概念,推导出了健壮、快速和高效的优化-最小化(MM)优化算法,用于具有可证明收敛保证的模型推理。
- 作者除了推导出了针对正定时间协方差矩阵的更新规则外,还假设时间协方差矩阵具有Toeplitz结构,这样可以在所提出的MM框架内产生计算效率较高的更新规则。
3.时空生成模型
作者重点研究脑源成像(BSI)问题,采用了多任务回归的方法,一个多任务线性回归问题的数学表述为 Y g = L X g + E g f o r g = 1 , . . . , G ( 1 ) Y_g=LX_g+E_g\;for\;g=1,...,G\;(1) Yg=LXg+Egforg=1,...,G(1)
其中,
-
L ∈ R M × N L\in R^{M×N} L∈RM×N表示前向矩阵
-
X g ∈ R N × T X_g \in R^{N×T} Xg∈RN×T表示一组脑源活动
-
Y g ∈ R M × T Y_g \in R^{M×T} Yg∈RM×T表示M/EEG测量结果
-
E g ∈ R M × T E_g \in R^{M×T} Eg∈RM×T表示噪声
所以本文中BSI的目标是从给定L的M/EEG测量结果中推断出潜在的大脑活动。
作者考虑将多任务线性回归问题表示为概率图形模型,给出了两个假设:
-
假设1:脑源的时空结构可以用高斯分布来建模,则 p ( X g ∣ Γ , B ) ∼ N ( 0 , Σ 0 ) p(X_g|\Gamma,B)\sim N(0,\Sigma_0) p(Xg∣Γ,B)∼N(0,Σ0),其中 Σ 0 = Γ ⊗ B \Sigma_0=\Gamma⊗B Σ0=Γ⊗B。 Γ \Gamma Γ和B分别表示空间和时间协方差矩阵,并设置 Γ \Gamma Γ是对角矩阵,B为大小T×T的正定矩阵。
-
假设2:噪声的时空结构可以用高斯分布来建模,则协方差矩阵 Σ e = Λ ⊗ Υ \Sigma _e=\Lambda⊗\Upsilon Σe=Λ⊗Υ。 Λ \Lambda Λ和 Υ \Upsilon Υ分别表示空间噪声和时间噪声协方差矩阵,设置 Λ \Lambda Λ是对角矩阵,并在这里假设噪声和脑源具有相同的时间结构,所以 Υ = B \Upsilon=B Υ=B。
其中,⊗表示克罗内克乘积,指两个任意大小的矩阵间的运算。
则本文的概率图形模型如下:
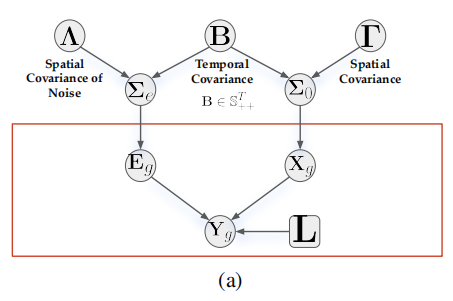
- Λ \Lambda Λ是空间噪声的协方差矩阵,它和时间协方差B的克罗内克积形成了 Σ e \Sigma_e Σe; Γ \Gamma Γ是空间协方差,和时间协方差B的克罗内克积形成了 Σ 0 \Sigma_0 Σ0。
- 而 Σ e \Sigma_e Σe是独立的高斯噪声 E g E_g Eg的方差, Σ 0 \Sigma_0 Σ0是脑源活动 X g X_g Xg的方差。
- 最后加上矩阵L,形成多任务回归问题的 Y g Y_g Yg。
- 通过这样的方式把多任务回归问题表示成概率模型,同时把 X g X_g Xg和 E g E_g Eg划分成了时间与空间的结构。
4.算法实现
4.1 重要公式
时空生成模型中包含三个未知参数 Γ , Λ , B \Gamma,\Lambda,B Γ,Λ,B,本文提出的算法可以在交替迭代过程中对其进行优化。在此给出两个重要公式。
脑源的后验分布 x g x_g xg是高斯分布,即 p ( x g ∣ y g , Γ , Λ , B ) ∼ N ( x ‾ g , Σ x ) p(x_g|y_g,\Gamma,\Lambda,B)\sim N(\overline{x}_g,\Sigma_x) p(xg∣yg,Γ,Λ,B)∼N(xg,Σx)
x ‾ g \overline{x}_g xg是它的均值, Σ x \Sigma_x Σx是它的方差。公式如下:
x ‾ g = Σ 0 D T ( Λ ⊗ B + D Σ 0 D T ) − 1 y g = Σ 0 D T Σ ~ y − 1 y g ( 2 ) \overline{x}_g=\Sigma_0D^T (\Lambda⊗B+D\Sigma_0 D^T)^{-1} y_g=\Sigma_0D^T \tilde{\Sigma}_y^{-1} y_g\;(2) xg=Σ0DT(Λ⊗B+DΣ0DT)−1yg=Σ0DTΣ~y−1yg(2)
Σ x = Σ 0 − Σ 0 D T Σ ~ y − 1 D Σ 0 ( 3 ) \Sigma_x=\Sigma_0-\Sigma_0D^T\tilde{\Sigma}_y^{-1}D\Sigma_0\;(3) Σx=Σ0−Σ0DTΣ~y−1DΣ0(3)
4.2 流形学习
针对参数B的更新,文章给出了直观的几何表示:

B ∈ S + + B\in S_{++} B∈S++,这是一个正定矩阵集,对B的更新采用了流形学习的思想,图中展示了{ B k , M t i m e k B^k,M^k_{time} Bk,Mtimek}这个矩阵对之间的测地线路径,通过计算这个矩阵对之间的几何平均值来更新 B k + 1 B^{k+1} Bk+1。
其中流形学习指的是,假设数据在高维空间的分布位于某一更低维的流形上,基于这个假设来进行数据的分析。
4.3 full Dugh
文章给出了算法full Dugh的具体实现

该算法中涉及公式6,公式9,公式7,公式10、11、12,如下:
M t i m e k : = 1 M G ∑ g = 1 G Y g T ( Σ y k ) − 1 Y g ( 6 ) M^k_{time}:=\frac1{MG}\sum_{g=1}^GY_g^T(\Sigma_y^k)^{-1}Y_g\;(6) Mtimek:=MG1g=1∑GYgT(Σyk)−1Yg(6)
M S N k : = H k Φ T ( Σ y k ) − 1 M s p a c e k ( Σ y k ) − 1 Φ H k , w i t h ( 9 ) M^k_{SN}:=H^k\Phi^T(\Sigma_y^k)^{-1}M^k_{space}(\Sigma_y^k)^{-1}\Phi H^k,with\;(9) MSNk:=HkΦT(Σyk)−1Mspacek(Σyk)−1ΦHk,with(9)
M s p a c e k : = 1 T G ∑ g = 1 G Y g ( B k ) − 1 Y g T ( 9 ) M^k_{space}:=\frac1{TG}\sum_{g=1}^GY_g(B^k)^{-1}Y_g^T\;(9) Mspacek:=TG1g=1∑GYg(Bk)−1YgT(9)
B k + 1 ← ( B k ) 1 2 ( ( B k ) − 1 2 M t i m e k ( B k ) − 1 2 ) 1 2 ( B k ) 1 2 ( 7 ) B^{k+1}\leftarrow(B^k)^{\frac12}((B^k)^{\frac{-1}2}M^k_{time}(B^k)^{\frac{-1}2})^{\frac12}(B^k)^{\frac12}\;(7) Bk+1←(Bk)21((Bk)2−1Mtimek(Bk)2−1)21(Bk)21(7)
H k + 1 = d i a g ( h k + 1 ) , h i k + 1 ← g i k z i k f o r i = 1 , . . . , N + M , w h e r e ( 10 ) H^{k+1}=diag(h^{k+1}),{h_i}^{k+1}\leftarrow\sqrt{\frac{{g_i}^k}{{z_i}^k}}\;for\;i=1,...,N+M,where\;(10) Hk+1=diag(hk+1),hik+1←zikgikfori=1,...,N+M,where(10)
g : = d i a g ( M S N k ) ( 11 ) g:=diag(M^k_{SN})\;(11) g:=diag(MSNk)(11)
z : = d i a g ( Φ T ( Σ y k ) − 1 Φ ) ( 12 ) z:=diag(\Phi^T(\Sigma_y^k)^{-1}\Phi)\;(12) z:=diag(ΦT(Σyk)−1Φ)(12)
- 公式6的作用是对 M t i m e k {M^k_{time}} Mtimek进行定义
- 公式9的作用是对 M S N k {M^k_{SN}} MSNk进行定义
- 公式7的作用是对B进行更新
- 公式10、11、12的作用是对H进行更新
所以,对后验分布的最终估计 x ‾ g \overline{x}_g xg可以从模型参数H、B的任何初始猜测开始得到,在更新公式(7)(10、11、12)和(2)之间进行迭代。
4.4 thin Dugh
文章给出了算法thin Dugh的具体实现

该算法中涉及公式16、17、18,公式19,如下:
p l k + 1 ← g ^ l k z ^ l k f o r l = 1 , . . . , L , w h e r e ( 16 ) {p_l}^{k+1}\leftarrow\sqrt{\frac{{\hat{g}_l}^k}{{\hat{z}_l}^k}}\;for\;l=1,...,L,where\;(16) plk+1←z^lkg^lkforl=1,...,L,where(16)
g ^ : = d i a g ( P k Q H ( B k ) − 1 M t i m e k ( B k ) − 1 Q P k ) ( 17 ) \hat{g}:=diag(P^kQ^H(B^k)^{-1}M^k_{time}(B^k)^{-1}QP^k)\;(17) g^:=diag(PkQH(Bk)−1Mtimek(Bk)−1QPk)(17)
z ^ : = d i a g ( Q H ( B k ) − 1 Q ) ( 18 ) \hat{z}:=diag(Q^H(B^k)^{-1}Q)\;(18) z^:=diag(QH(Bk)−1Q)(18)
x ‾ g = ( Γ ⊗ B ) D T Σ ~ y − 1 y g = t r ( Q P ( Π ⊙ Q H Y g T U x ) ( U x T L Γ T ) ) ( 19 ) \overline{x}_g=(\Gamma⊗B)D^T\tilde{\Sigma}_y^{-1}y_g=tr(QP(\Pi⊙Q^H{Y_g}^TU_x)({U_x}^TL\Gamma^T))\;(19) xg=(Γ⊗B)DTΣ~y−1yg=tr(QP(Π⊙QHYgTUx)(UxTLΓT))(19)
- 该算法中的B是正定托普利茨矩阵
- 公式19的作用是给出对 x ‾ g \overline{x}_g xg的计算
- 公式10、11、12的作用是对H进行更新
- 公式16、17、18的作用是对p进行更新
所以,对后验的计算通过在更新公式(16、17、18)(10、11、12)和(19)之间迭代得到。
5.实验对比
四种不同脑源成像方案的比较:

在宽范围的信噪比、不同的时间样本数量、不同的AR模型顺序三种情况下对四种脑源成像的算法进行了性能评估,EMD(陆地移动距离)和TCE(时程相关误差)是进行性能评价的两个度量标准。
可以看到,Dugh在EMD度量方面取得了优越的性能,而在TCE方面则具有竞争力。
6.总结
- 针对脑源成像问题,采用多任务线性回归,提出了脑源和噪声的时空生成模型
- 提出了Full Dugh和Thin Dugh两个算法
- 在真实脑磁图和脑电图数据中进行了实验,表现出稳健和具有竞争力的性能
- 可以用于其他领域,如高斯过程回归中的核宽度、字典学习问题中的字典元素需要从数据中推断出来















 6487
6487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









