






目录
前言
程序开发工作中,尤其是涉及到数据的处理时,其中一个屡见不鲜的数据处理场景就是将一个用来接收的临时缓冲区中数据拷贝到另一个缓冲区去处理,随后再将临时缓冲区置零。这很容易让我们想到strcpy字符串拷贝函数,只是恰如其名的是strcpy仅仅是用来实现字符串的拷贝,对于整型、结构体等各种其他数据类型数组的拷贝strcpy是无能为力的。因此C语言函数库提供了memcpy()、memcmp()、memmove()、memset()等内存操作函数,望文生义不难理解它们都是操作内存的函数,这也意味着它们可以无视数据类型,适用于所有类型数据的拷贝、比较、初始化操作。
常用的内存操作函数就是memcpy()、memcmp()、memmove()、memset()这四个,主要注意其参数,结合应用场景灵活使用。
一、内存操作函数
1.1 memcpy()
函数原型:void* memcpy(void* dest,const void* src,size_t num)
dest为指向目标空间的指针,src为指向源空间的指针;memcpy()实现将src指向空间的num个字节数的数据拷贝到dest指向的空间,返回指向dest空间的指针。
下图是模拟实现memcpy()函数例程,注意void*不能做自增自减等移动指针运算和直接解引用:
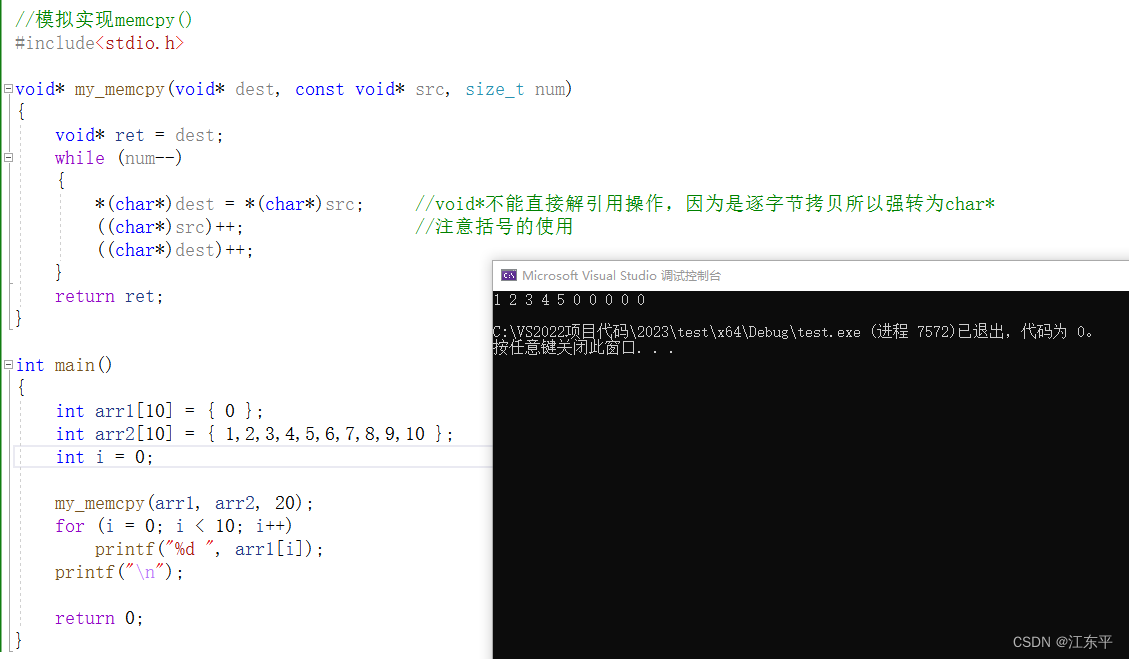
1.2 memmove()
函数原型:void* memmove(void* dest,const void* src,size_t num)
dest为指向目标空间的指针,src为指向源空间的指针;memmove()实现将src指向空间的num个字节数的数据拷贝到dest指向的空间,返回指向dest空间的指针。
1.2.1 重叠内存拷贝分析
memmove()和memcpy()函数的参数一样,都是对内存进行拷贝的函数。但是在重叠内存这一块,即目标区域和源区域有重叠的话,memmove()是比memcpy()更安全的方法,memmove()能够保证源空间数据在被覆盖之前将重叠区域的字节拷贝到目标区域中,复制后源区域的内容会被更改。如果目标区域与源区域没有重叠,则和memcpy()函数功能相同。下面解释内存重叠时memcpy()拷贝数据可能会出错的原因,因为内存重叠时源空间和目标空间存在两种情况,如下图所示:
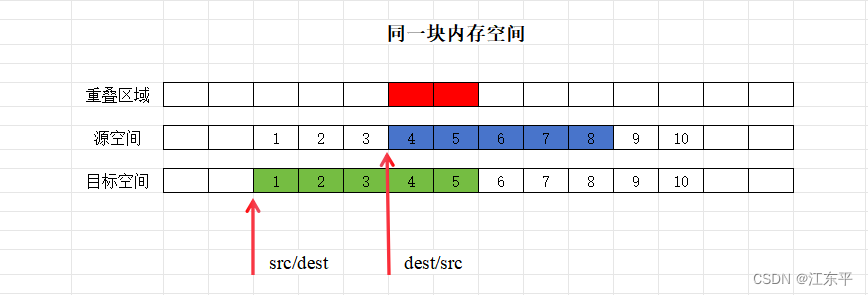
第一种情况:源空间在目标空间之后,假设如图所示拷贝5个字节,如果是从前往后逐字节拷贝,这种情况不会有问题,能达到预期效果。
第二种情况:源空间在目标空间之前,假设如图所示拷贝5个字节,如果还是从前往后逐字节拷贝,那么拷贝到重叠区域以后,4和5会被1和2覆盖致使源数据丢失无法拷贝,会导致最终内存数据为:

可见这种情况从前向后逐字节拷贝势必会出错,为了解决数据覆盖的问题,可以从后向前拷贝。因此不难想到模拟实现memmove()只需要分两种情况分别从前向后和从后向前拷贝即可,下图是模拟实现memmove()例程及运行结果,编程时易错点在注释中体现:
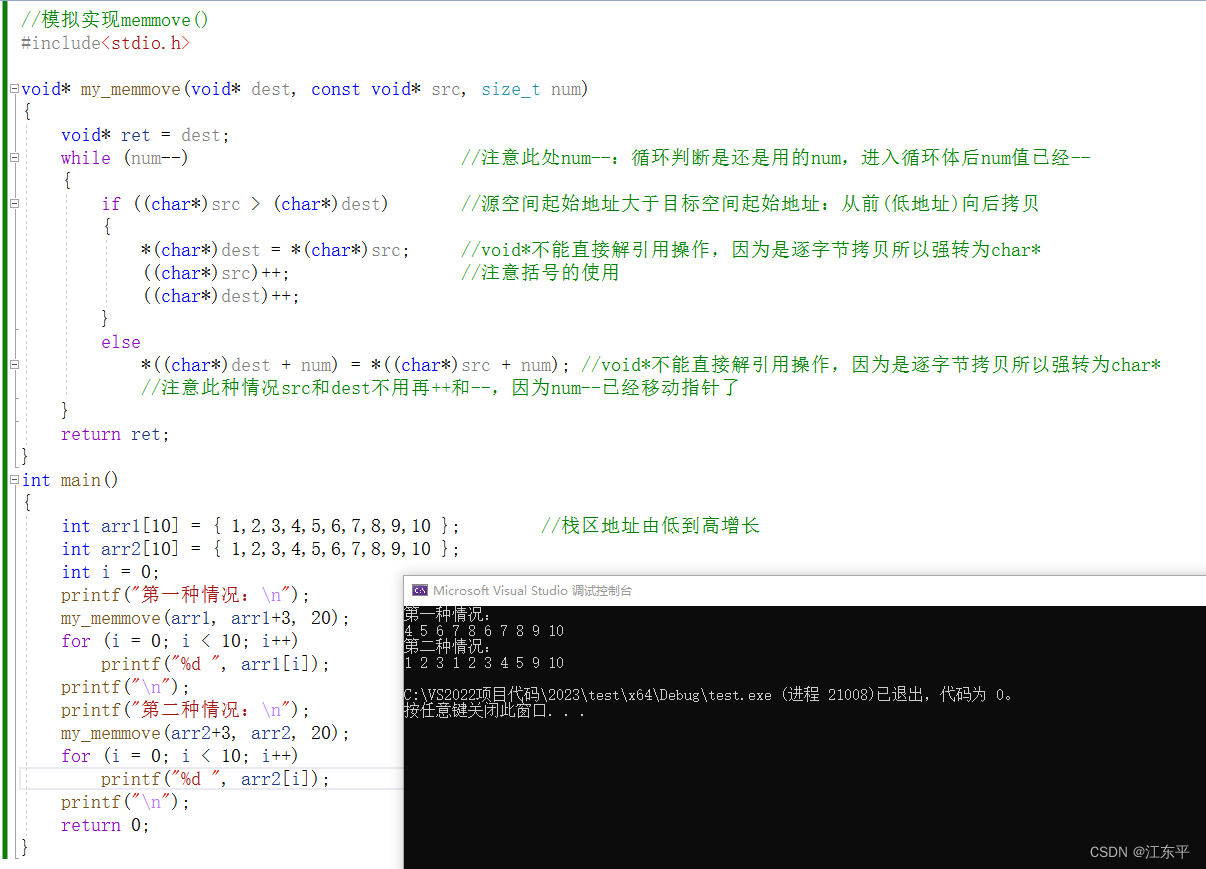
1.2.2 记模拟memmove()时写出的一个bug
模拟memmove()时写出的一个bug,bug代码和结果如下图:
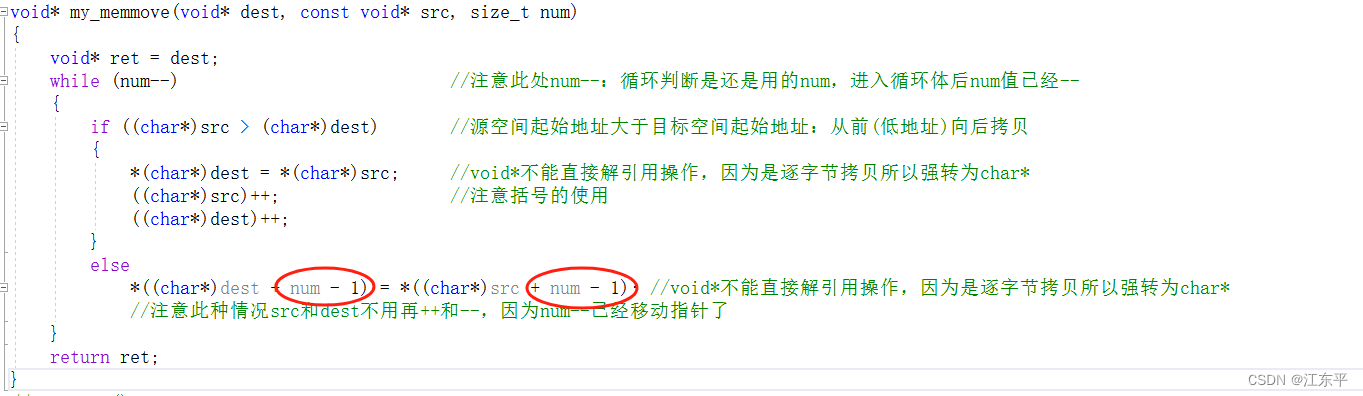
写出这个bug的原因在于我对while循环条件语句num--的错误认知,起初我错误的认为num--在判断时和进入循环体后的num值相同,后通过调试监视num值发现,假设之前num值是20,那么在执行至while(num--)时,循环判断时num还是20;进入循环体后num就变为19,这也符合后置--或++是先使用再--或++,是我理解错误了,最终也导致在由后向前拷贝时不是从最后一个值开始而是从倒数第二个值开始。
虽然有些编译器memcpy()函数能够实现和memmove()一样的功能,但不能保证万无一失,所以在源空间和目标空间有重叠时还是选用memmove()函数,memcpy()函数不用来处理重叠内存之间的数据拷贝。
1.3 memcmp()
函数原型:int memcmp(const void* str1,const void* str2,size_t num)
memcmp()实现把指向str1空间和指向str2空间的num个字节逐字节进行比较,直至遇见不同,如果str1<str2返回值<0;如果str1>str2返回值>0;如果str1=str2返回值=0。
注意memcmp()也是逐字节进行比较的,实参传递num时一定要结合待比较数据类型给出正确的字节数,模拟实现memcmp()的例程及其运行结果如下图所示:
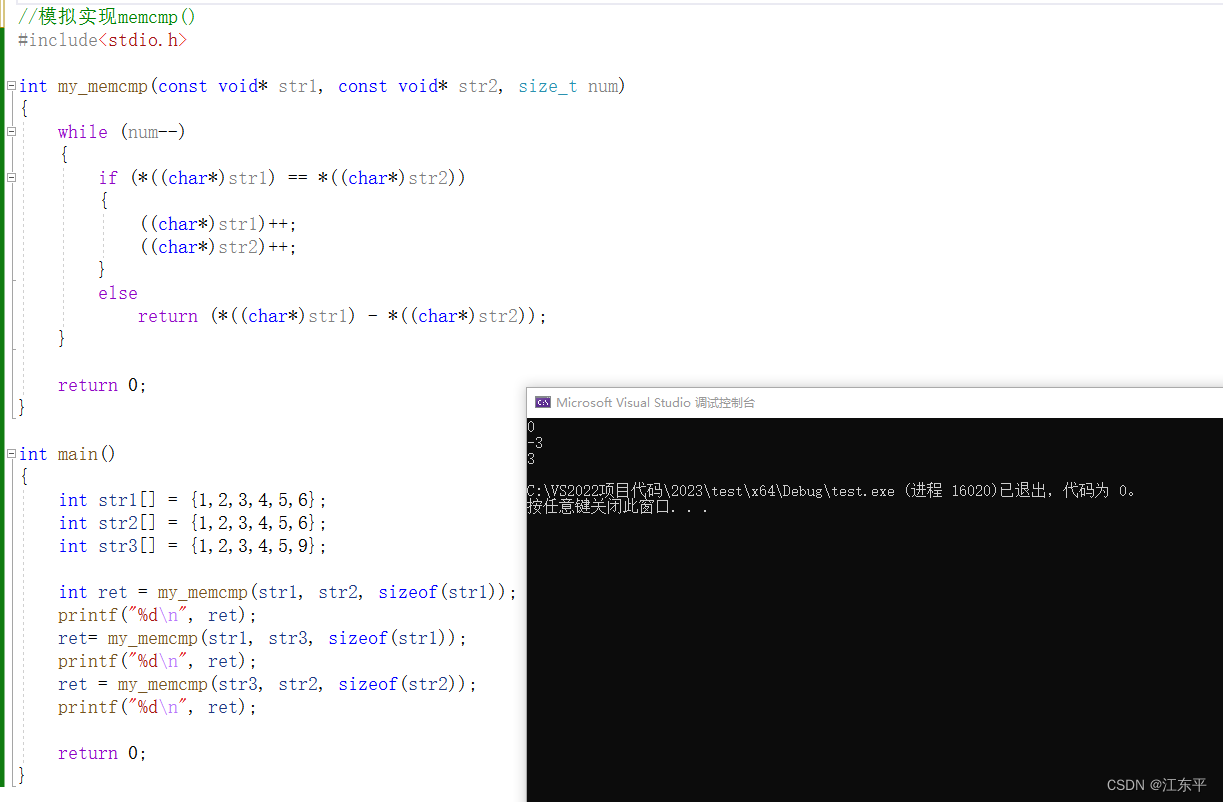
1.4 memset()
函数原型:void* memset(void* dest,int value,size_t num)
memset()实现将参数dest指向的内存空间中num个字节逐字节设置为value值。
1.4.1 value参数中的名堂
虽然参数是int型,但显然因为是逐字节设置value,value值肯定仅限于一个字节所表示的数据范围,下面通过在例程中设置不同值验证是否如此。
value为255:
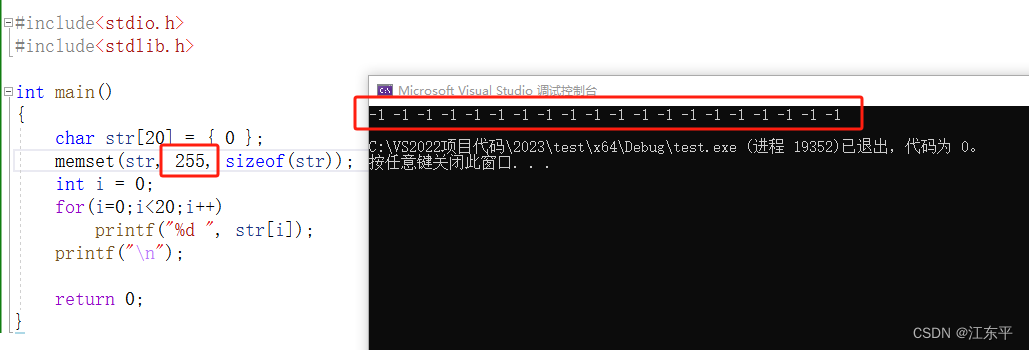
可以看出最终结果竟然是-1,这是因为“%d”是输出有符号32位整数,会进行整型提升所以最终结果是-1;将打印改成“%hhu”(输出8位无符号整数)或者定义数组str为unsigned char类型,结果就是255了,如下所示:
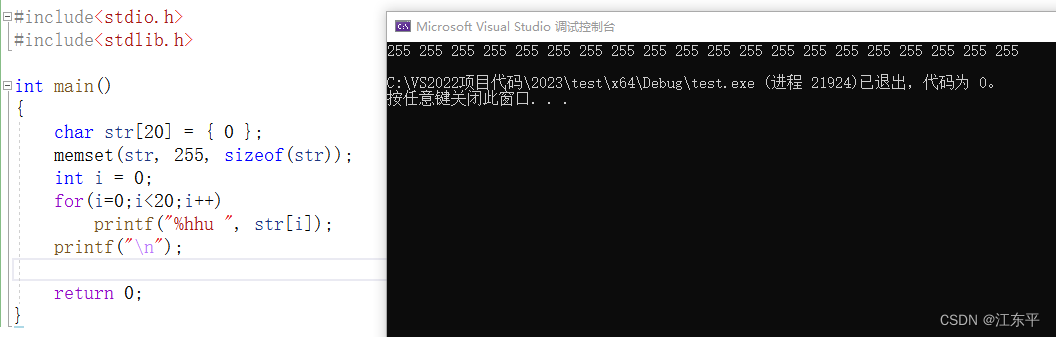
言归正传,上面涉及到无符号数和有符号数存储格式及打印输出格式的问题,不难推断,value值在0-127输出肯定都是原值,在128-255就都是负数了。那么在255以上会是什么结果呢?这次设置value为520试试:
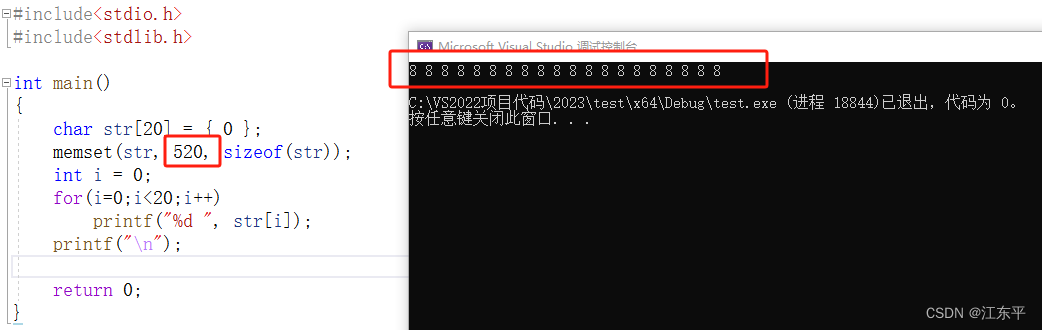
最终设置的值是8,为什么?因为520等于0b0010 0000 1000,将其存放于一个char型内存空间,截断就是0b0000 1000,所以自然是8了。
1.4.2 memset()的局限性
memset()函数是按一个字节一个字节,以字节为单位进行设置value操作的,这就势必导致memset有这样一个局限性:如果想要初始化一个整型数组每个元素都是1,用memset()函数肯定是不能实现的。会产生如下错误结果:
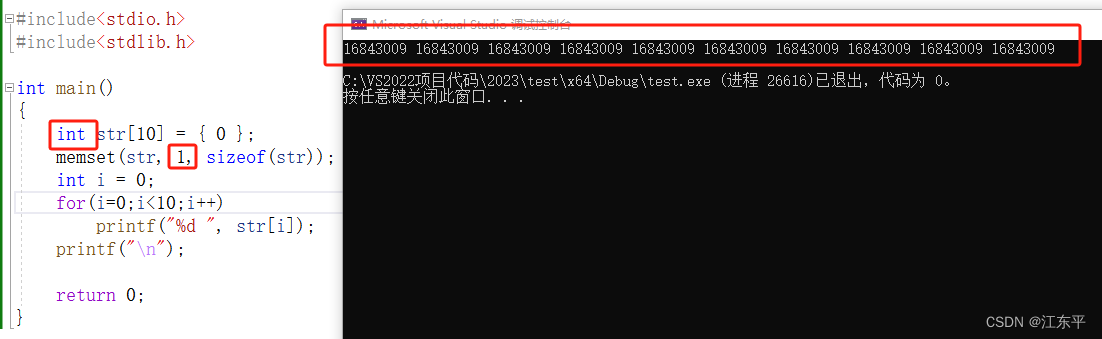
下图是调试结果,可以更直观的观察到memset()函数是逐字节设置内存值的:
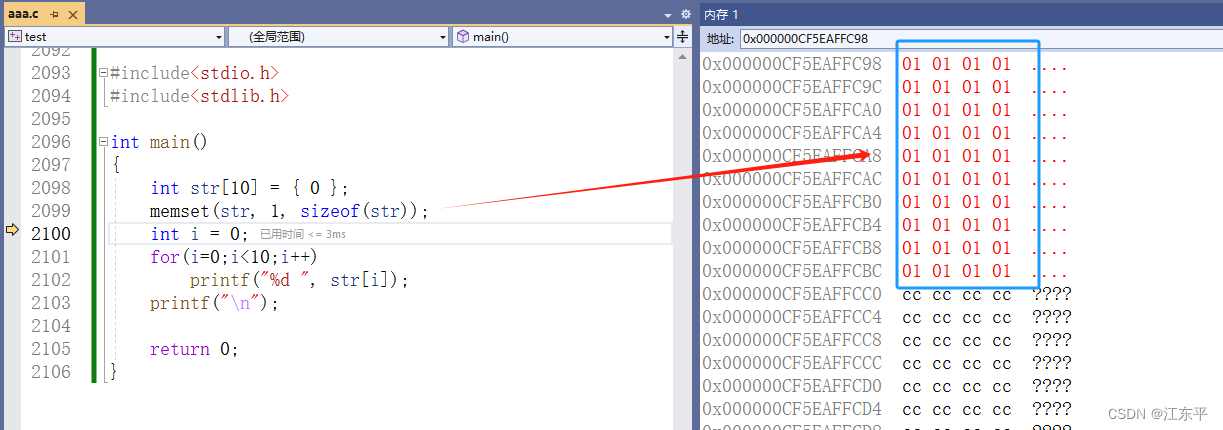
由调试结果可知,整型数组每个元素是4字节,memset是把每个字节都设置为1了,这就导致整型数组元素值为0x01010101,不能实现将整型数组每个元素赋值为1。因此可以得出结论:对于整型或者其他非字符型数组初始化为一个value值是不能用menset()函数的,如果value为非0,那么只能用循环赋值来实现了。
memset()函数大多数时候用于初始化内存,但是千万不要以为它的功能只是用来设置整个缓冲区的数据,因为其num参数还可以使其用来改变缓冲区一部分数据,例如改变一个字符串中的某几个字符,所以不要局限了memset()函数的功能。
二、回顾曾经写过的一个bug
strcpy()的局限性仅仅只有一个只能拷贝字符型数据的限制吗? 一切都要从我曾经在工作中写的一个bug开始讲起,也是从这以后我开始明白memcpy()是多么的好用。去年我负责开发增加一个产品的固件远程升级功能,其中的一个步骤就是把服务器下发的一个个固件包进行接收组包。这不难实现,组包的具体过程就是将服务器下发的每个固件包中固件内容拷贝到一个总的缓冲区中去。因为固件包内容是逐个字节填充的,所以我程序中定义用来接收固件包的数组也是字符型,于是我最先想到的是用strcpy()函数来将接收固件内容缓冲区中数据拷贝到大缓冲区。结果就是发现每次拷过来的数据字节数很少且不一样,正常应该是980字节数而实际却只有200多字节甚至更少。
通过报文接收窗口看服务器下发的每包数据是完整的,这说明是装置接收到拷贝过程出了差错。立刻想到strcpy()拷贝数据是遇到 '\0'(ASCII码十进制值就是0)就停止,观察报文接收窗口果然发现固件包中存在0x00值,这就解释的通为什么拷过来的数据不完整了!下面通过一个例程模拟此现象并使用memcpy()函数观察拷贝结果:
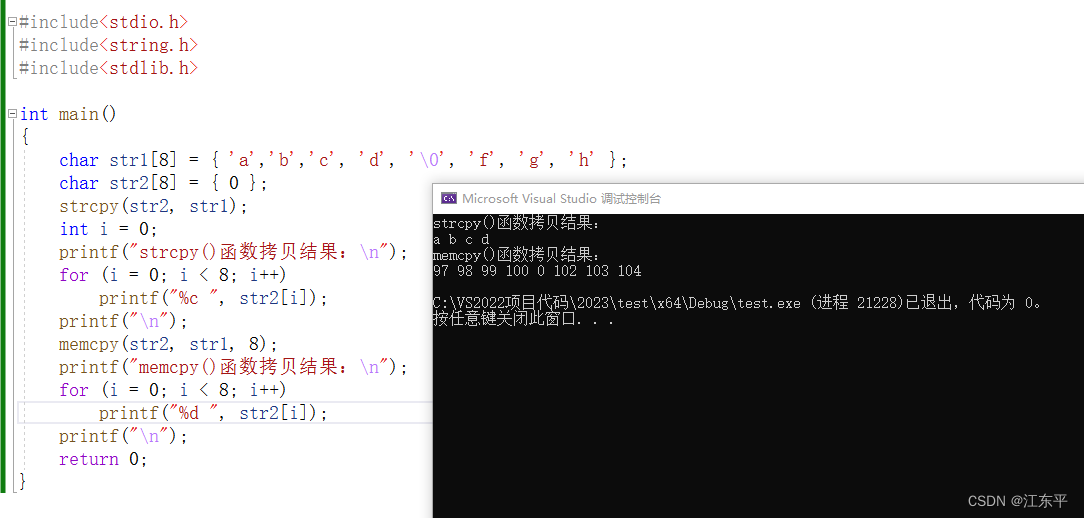
memcpy()遇到'\0'是不会停止的,所以使用strcpy()进行数据拷贝时一定要注意拷贝数据中是否包含0值,个人以为还是用memcpy()函数吧,直接针对内存拷贝。
















 1312
1312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









