







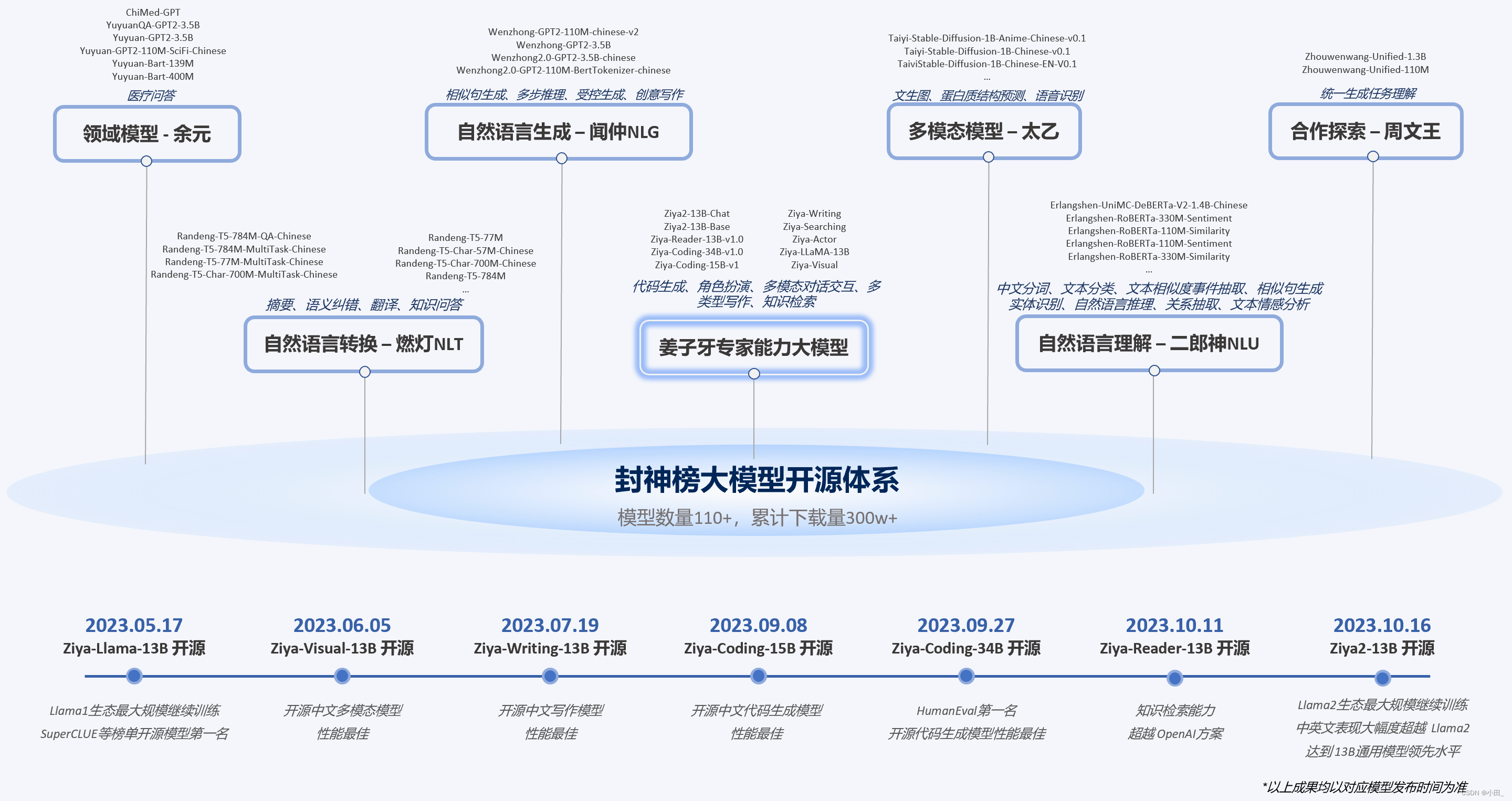
 IDEA研究院的‘封神榜’大模型开源体系包含模型、框架和榜单,提供多模态、知识检索和代码生成等功能。Ziya系列模型如Ziya-Visual、Ziya-Reader和Ziya-Coding各具特色,推动中文预训练模型社区进步。
IDEA研究院的‘封神榜’大模型开源体系包含模型、框架和榜单,提供多模态、知识检索和代码生成等功能。Ziya系列模型如Ziya-Visual、Ziya-Reader和Ziya-Coding各具特色,推动中文预训练模型社区进步。
- huggingface : https://huggingface.co/IDEA-CCNL
- github : https://github.com/IDEA-CCNL/Fengshenbang-LM
- 官网:https://fengshenbang-lm.com
封神榜大模型
2021年11月22日, IDEA 研究院创始人兼理事长沈向洋在IDEA大会上正式宣布启动“封神榜”大模型开源体系。
“封神榜”是由 IDEA-CCNL 的工程师、研究人员、实习生团队共同维护的一项长期开源计划。
项目基于Apache 2.0开源许可,计划包括封神榜模型,封神框架还有封神榜单三个部分。
封神榜的模型可以在 HuggingFace 社区中免费下载和使用,封神框架可以通过访问我们的GitHub获得: Fengshenbang-LM 。
封神榜单将会在未来数月内完善并正式公布。
“封神榜”开源体系将会重新审视整个中文预训练大模型开源社区,全方位的推进整个中文大模型社区的发展,旨在成为中文认知智能的基础设施。
封神榜 - 大模型开源体系
https://fengshenbang-doc.readthedocs.io/zh/latest/
多模态
Ziya-Visual多模态模型结合了视觉和语言两大模态的能力,并且继承了Ziya-v1推理能力和创作能力,所以能够很好地回答用户的各种问题或者针对用户的需求进行想象和创作。
https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1
知识检索
Ziya-Reader可以从多个候选中找到正确的答案,准确地回答问题。该模型具有8k的上下文窗口,相比其他具有更长窗口的模型,我们在多个长文本任务的评测中胜出。
https://huggingface.co/IDEA-CCNL/Ziya-Reader-13B-v1.0
代码生成
Ziya-Coding将成为编程的高效助手,该模型让用户和开发者轻松使用中文生成高可用的代码,对代码做高质量的中文解释,并支持私有化部署和继续训练,助力企业生产力提升。
https://huggingface.co/IDEA-CCNL/Ziya-Coding-34B-v1.0
姜子牙系列模型
姜子牙通用大模型V1是基于LLaMa的130亿参数的大规模预训练模型,具备翻译,编程,文本分类,信息抽取,摘要,文案生成,常识问答和数学计算等能力。
目前姜子牙通用大模型已完成大规模预训练、多任务有监督微调和人类反馈学习三阶段的训练过程。


















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









