






第四周:李宏毅机器学习
摘要
在进行梯度下降过程中,学习率是一个重要的参数,学习率的大小决定着模型训练的平滑程度和稳定性。本文介绍了如何自动调整学习率,学习率会随着梯度的改变而改变。从而在各个情况下采用合适的学习率。同时也介绍了 Adagrad算法和RMSProp算法,Learning Rate Decay和Warm up是机器学习中的优化技术,这两种方式可以改变学习率中的 η \eta η,将 η \eta η随着时间的改变而改变,从而可以避免 “梯度爆炸” 等现象,本文对此都有详细解释。本文也对深度学习的卷积神经网络 (CNN) 进行详细的拆解分析,对卷积的作用、卷积特征值的具体计算方法、特征图、步长、卷积核尺寸大小、边缘填充进行推导分析。
Abstract
In performing gradient descent, the learning rate is an important parameter, and the size of the learning rate determines the smoothness and stability of the model training. This paper describes how to automatically adjust the learning rate, which changes as the gradient changes. Thus, the appropriate learning rate is used in each case. Adagrad algorithm and RMSProp algorithm are also introduced. Learning Rate Decay and Warm up are optimization techniques in machine learning, which can change the \etaη in the learning rate and change the \etaη with time, so that we can avoid "gradient explosion " and other phenomena, which are explained in detail in this paper. This paper also provides a detailed disassembly analysis of the convolutional neural network (CNN) for deep learning, with derivation and analysis of the role of convolution, the specific calculation of convolutional eigenvalues, feature maps, step size, convolutional kernel size, and edge filling.
1. 自动调整学习速率 (Learning Rate)
上周了解了局部最小点和鞍点,但在进行梯度下降的过程中,参数更新至局部最小点和鞍点并不一定是最大障碍。我们往往在训练模型时,会把Loss损失值记录下来,在进行梯度下降不断优化模型后,Loss值会越来越小。最终Loss值会逐渐趋于平稳。Adagrad 算法只是针对不同参数而动态改变学习率,有时候就算是同一个参数,也需要学习率随着其梯度的改变而改变。RMSProp算法有效解决了这一问题。

Loss值变得平稳,可能是由于梯度为0,也可能是由于学习率过大,导致梯度在最小值附近来回震荡,甚至可能无法收敛。如果学习率过小,梯度更新过程十分缓慢,下降速度太慢,可能要花很长的时间才会找到最小值。
那么我们应该如何合理的设置学习率呢?
我们往常都是采用所有参数都采用同一个学习率,这样显然不可行,不同的参数应该设置不同的学习率。如果在某个方向上梯度值很小,那我们会增加学习率,如果在某个方向上梯度值很大,那我们会相应的降低学习率。我们往常用的梯度下降方式为:
θ
i
t
+
1
=
θ
i
t
−
η
g
i
t
\theta^{t+1}_{i} = \theta^{t}_{i} - \eta g^{t}_{i}
θit+1=θit−ηgit,其中
g
i
t
=
∂
L
∂
θ
i
∣
θ
=
θ
t
g^{t}_{i} = \frac{\partial L}{\partial \theta_{i}}|_{\theta=\theta^{t}}
git=∂θi∂L∣θ=θt。现在我们需要能够自动调整学习率,我们将原来梯度下降中的
η
\eta
η 改写为
η
σ
t
\frac{\eta}{\sigma^{t}}
σtη,即
θ
i
t
+
1
=
θ
i
t
−
η
σ
t
g
i
t
\theta^{t+1}_{i} = \theta^{t}_{i} - \frac{\eta}{\sigma^{t}} g^{t}_{i}
θit+1=θit−σtηgit,其中
σ
t
\sigma^{t}
σt是随着梯度
g
i
t
g^{t}_{i}
git 而改变的。以下是
σ
t
\sigma^{t}
σt的手推计算过程:


1.1 Adagrad 算法
上述的推导方法应用于 A d a g r a d Adagrad Adagrad 算法中,Adagrad是一种优化算法,用于在机器学习中自适应地调整学习率。Adagrad算法的主要思想是根据每个参数的梯度历史信息来自适应地调整学习率。之前我们所采用的梯度下降对所有的参数都使用的固定的学习率进行参数更新,但是不同的参数梯度可能不一样,所以需要不同的学习率才能比较好的进行训练,但是这个事情又不能很好地被人为操作,所以 Adagrad 便能够帮助我们做这件事。
Adagrad算法的步骤如下:
- 初始化累计梯度平方的初始值为零,记为r。
- 对于每个训练样本,计算参数的梯度。
- 将梯度的平方累加到r中,即r = r + 梯度²。
- 根据公式计算每个参数的学习率:学习率 = η σ t \frac{\eta}{\sigma^{t}} σtη,其中 σ t \sigma^{t} σt是为了数值稳定性而加入的小值,随梯度的改变而改变。
- 根据学习率和梯度更新参数的值:参数 = 参数 - 学习率 × 梯度。
在梯度下降的过程中,根据梯度的大小自动更改 σ t \sigma^{t} σt,从而更改学习率,从而规避了学习率过大和过小的问题。Adagrad算法能够更好地处理不同参数的梯度差异,从而有助于收敛到全局最优解。
但是 Adagrad 算法只是针对不同参数而动态改变学习率,有时候就算是同一个参数,也需要学习率随着其梯度的改变而改变。参数沿着同一方向更新梯度时,可能在某个地方梯度更新比较平坦,此时需要自动将学习率增大。随后也可能在某个地方梯度更新比较陡峭,此时需要自动将学习率降低。我们可以用 RMSProp 算法来解决这个问题。
1.2 RMSProp 算法
RMSProp 是一种优化算法,用于在机器学习中自适应地调整学习率。它是Adagrad算法的改进版本,用于解决Adagrad算法可能出现的学习率过于下降的问题。与Adagrad算法不同,RMSProp算法引入了一个衰减系数
α
\alpha
α,用来控制梯度平方累加项的贡献程度。具体而言,给定一个优化目标和一组参数。


RMSProp算法的步骤如下:
- 初始化累计梯度平方的初始值为零,记为 σ i t − 1 \sigma^{t-1}_{i} σit−1。
- 初始化衰减系数 α \alpha α 为一个小的常数(如0.9)。
- 对于每个训练样本,计算参数的梯度 g i t g^{t}_{i} git。
- 更新累计梯度平方: σ i t \sigma^{t}_{i} σit = α \alpha α × σ i t − 1 \sigma^{t-1}_{i} σit−1 + (1 - α \alpha α) × ( g i t ) 2 (g^{t}_{i})^{2} (git)2。
- 根据公式计算每个参数的学习率:学习率 = η σ t \frac{\eta}{\sigma^{t}} σtη,其中 σ t \sigma^{t} σt是为了数值稳定性而加入的小值,随梯度的改变而改变。
- 根据学习率和梯度更新参数的值:参数 = 参数 - 学习率 × 梯度。
如下图中黑点表示更新的参数,我们不自动调整学习率时,参数更新到梯度为0时(局部最小点或鞍点),就不再更新。但是距离橙色的目标点还仍有距离

我们运用传统的 Adagrad 算法进行梯度下降,参数可以更新到橙色目标点处,我们在计算
σ
i
t
\sigma^{t}_{i}
σit时是将过去梯度之和,然后取平均值开根号,因为在纵轴的方向,刚开始梯度比较大学习率比较小,因此在纵轴方向积累了很多很小的
σ
i
t
\sigma^{t}_{i}
σit,累计到一定量之后,梯度就会变很大,这时就会走到梯度比较大的地方,累计的
σ
i
t
\sigma^{t}_{i}
σit又会慢慢变大,学习率降低,参数更新的步伐又会变小,慢慢的又回到横轴位置。如下图

怎么避免这种“梯度爆炸”的出现呢?
1.3 Learning Rate Scheduling(学习率调度)
我们可以使用 Learning Rate Scheduling,Learning Rate Scheduling(学习率调度)是机器学习中的一种优化技术,用于在训练过程中动态地调整学习率的数值。

这样,随着训练时间的推移,学习率的不断降低,
σ
i
t
\sigma^{t}_{i}
σit也逐渐稳定到了一个值,不会出现 “梯度爆炸” 的现象。因为当学习率如果小到趋于0时,新的梯度
g
i
t
g^{t}_{i}
git可以几乎忽略不计,此时梯度可能更新至了全局最小点,也就是参数即将优化至最佳。如下图:

除了 Learning Rate Decay 以外,另外还有一种比较常用的 Learning Rate Scheduling 的方式,叫做 Warm up 。Warm up 与 Learning Rate Decay 不同,通过 Warm up 使
η
t
\eta^{t}
ηt 先增大后减小。
使用 Warm up 的目的是在训练初期防止模型陷入局部最优解,并帮助模型跳出局部最优点,更好地探索训练空间。通过逐渐增加学习率,模型可以在初始阶段进行更大的权重更新,然后在后期以较小的步伐进行微调。
通俗的来说,由于 σ i t \sigma^{t}_{i} σit是告诉我们梯度下降过程中某个方向的平滑度和陡峭度,但是需要堆叠多笔梯度后才能更加精准,梯度下降初始阶段,由于迭代次数较少, σ i t \sigma^{t}_{i} σit是不精准的,并不能精准的体现梯度下降过程的平滑度和陡峭度,此时如果我们采用较大的学习率,有很大的可能使模型对于数据“过拟合”(“学偏”),后续需要更多的轮次才能“拉回来”。
因而一开始我们不要让模型的参数更新过快,也就是不要让学习率过大。在初始阶段逐步增加学习率,进行一定的迭代次数后,使得 σ i t \sigma^{t}_{i} σit 逐步精准后,模型对数据具有一定的先验知识,此时使用较大的学习率模型就不容易学“偏”,可以使用较大的学习率加速模型收敛,通过自动调整学习率,合理的提高和降低学习率,进行参数调优。
2. 卷积神经网络 (CNN)
卷积神经网络分别由输入层、卷积层、池化层、全连接层。输入层指的是图像数据,通常是三维的结构,如 28 x 28 x 1 的一个图像数据。卷积层可以简单理解为是提取特征,池化层可以简单理解为压缩特征。全连接层的每个神经元都与上一层的所有神经元相连,每个连接都有一个权重。在前向传播过程中,每个神经元的输出是上一层所有神经元的加权求和,并通过激活函数进行非线性处理。输出层最后得到的是一组概率值。
2.1 卷积的作用
假设我们输入的图像是一个 32 x 32 x 3 的矩阵数值,而卷积无非是要做特征提取。但是我们在进行特征提取时,不同的特征,训练起来的精准度也不同。就比如我们输入的图像是一只小猫,小猫位于图片的正中间,图像中仍然有背景,图像边界的特征和小猫体态的某个细节部分的特征是不同的,因此我们需要做的是对图像不同区域提取出跟图像辨识物体的尽可能相似的特征,比如小猫的眼睛和鼻子,这两处特征不同,但通过这两处特征也能够区分出这张图像是小猫。同理,对于不同的特征,应该有不同的权重,比如这张图的背景,我们在提取特征的过程中也可能会将图像背景当成特征输入神经网络,但是通过图像背景特征并不能辨识这是只小猫,如果这些特征权重过大,最后训练出来的神经网络难免会存在较大的误差。因此我们需要将图片与辨识目标相近的地方,作为主要特征,比如小猫的眼睛、鼻子、爪子等。图像的不同区域要进行区别处理。
当我们在进行卷积的过程中,我们需要先将图像进行分割,分割成若干个小块。每一个小块代表一个区域,每一个区域由多个像素点构成,对每个区域进行特征提取。假设每个小区域为 3x3 的矩阵


2.2 卷积特征值计算方法
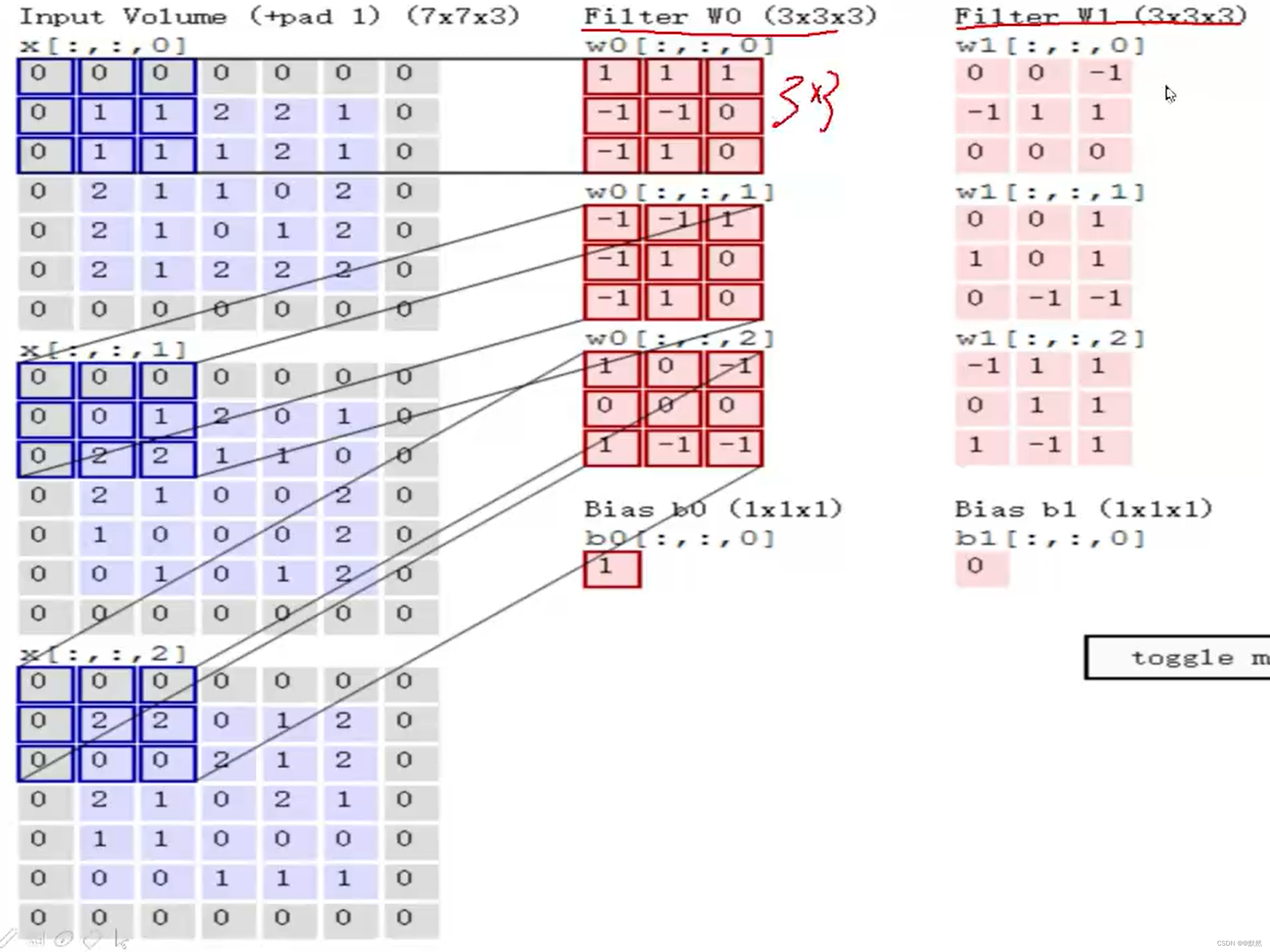
如果我们输入的不是黑白图像,而是RGB彩色图像,则这个图像有三个颜色通道,分别是R、G、B三个通道,实际我们在进行特征提取的过程中,我们要对每个颜色通道进行特征提取。根据 2.1 中的思路,分别对三个通道求特征图,然后最后让三个通道的特征图相加,得到这个完整的特征图。即需要分别求三个图像通道的特征值,然后再累加。

假设我们输入的数据为 7x7x3 的图像。R、G、B 三个颜色通道输入均为 7x7 的矩阵数值。接下来我们需要分区域对我们当前的图像数据进行特征提取,我们在这三个颜色通道分别随机初始化三组不同的权重参数矩阵,每个颜色通道对应一组随机的权重参数矩阵
w
0
w_{0}
w0。权重参数矩阵与原图像划分的小区域大小一致,比如原图像每一个颜色通道划分的小区域为 3x3 ,则权重参数也为 3x3 矩阵,而我们将 3x3 大小的区域称为卷积核。如果权重参数矩阵为 4x4 矩阵,则原图像选择区域就得选择 4x4 矩阵大小的区域进行特征提取。卷积特征值计算方法如下:
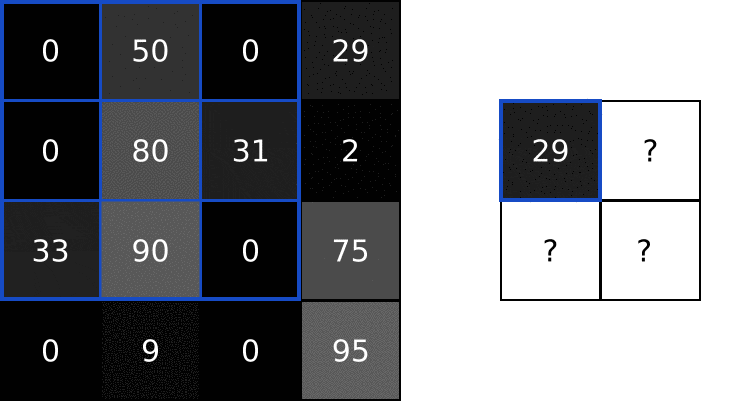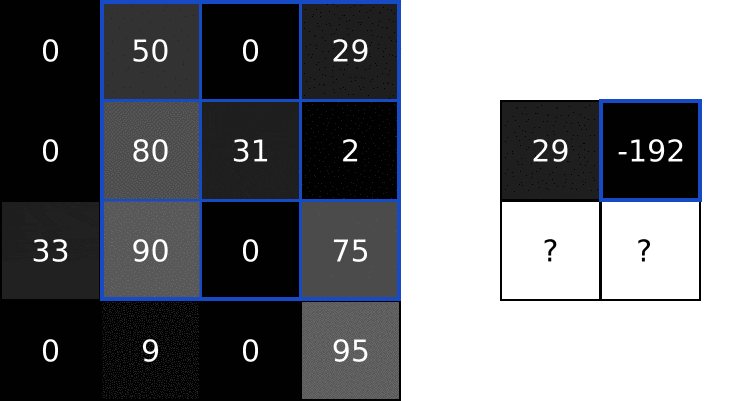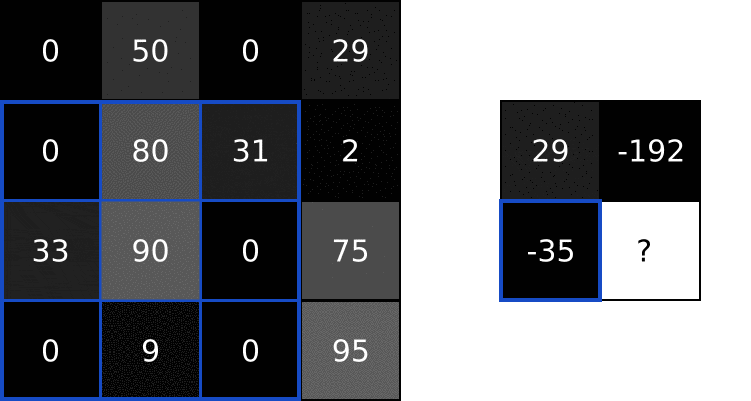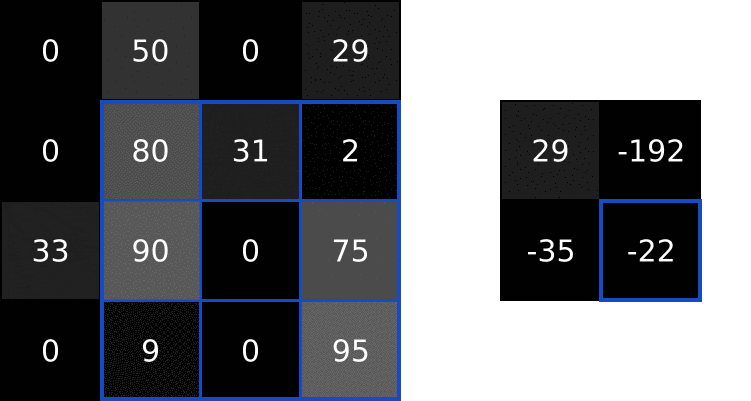
首先需要先计算图像三个颜色通道的区域矩阵与其对应的随机权重矩阵的内积,将三个颜色通道求出的内积相加,下图手算过程为其中的R通道

求出图像R颜色通道区域与权重参数矩阵的内积后,G颜色通道区域与权重参数的内积和B颜色通道区域与权重参数的内积与上述手推思路一致。如下图,求出三个内积之后,将其相加,最后加上偏置项 bias,下图中将偏置项
b
0
b_{0}
b0设置为1。

根据上图的计算,特征值 = 三个内积之和 + bias偏置项 ==> 特征值 = (0 + 2 + 0)+ 1 = 3
2.3 得到特征图表示
依照上述计算思路,每一块区域对应一个随机的权重参数矩阵,在输入数据上按照步长
s
t
r
i
d
e
=
1
stride = 1
stride=1依次向右或向下移动,计算后续的值:
这个动图只是计算的是一个颜色通道,将3个颜色通道卷积计算完后,按照上述手算思路,最后再加上偏置项,最终所有区域的特征值组成一个特征矩阵,也就是特征图。我们的特征图最后也可以是多个,这样可以使得我们的特征提取更加丰富。如果我们在原有的基础上,再增加一组权重参数矩阵
w
1
w_{1}
w1,将输入的矩阵区域分别分别向右或向下移动步长为1,逐步移动,每移动一次,对应的权重参数矩阵
w
0
w_{0}
w0和
w
1
w_{1}
w1都会改变,最后依次计算出二者对于图像的特征值,将每个区域的特征值组合一起,也就得到了两个特征图,注意,特征图中的每个特征值对应的是图像的3个颜色通道中某个小区域输入的矩阵与权重参数进行内积之和,因为通过一组权重参数(卷积核),可以输出一个特征图,下图中是外加了一组权重参数
w
1
w_{1}
w1,故最后得到两个特征图。计算思路与上述的手算过程一致。
最终得到的两个特征图如下:

但是,在实际过程中,我们会只进行一次卷积吗?
显然,我们如果要将输入的特征提取的更好,做一次卷积是不够的,我们需要进行多次卷积,我们做完第一次卷积后,根据我们有多少组权重参数矩阵,对应就生成多少个不同的特征图,然后我们将这些特征图当成中间特征,进行第二次卷积,进行进一步特征提取,最终得到特征图。以此类推,可以进行多轮卷积,先粗粒度提取特征,其次再细粒度提取中间特征,最后再提取一些组合的高级特征。
2.4 步长与卷积核大小对结果的影响
步长为输入图像区域的移动长度,可以根据实际需求自行设定。步长为1的卷积是在原有的基础上移动了一个单元格,步长为2的卷积是在原有的基础上移动了两个单元格。红框的输入区域经过卷积,对应一个特征值。绿色框的区域也是对应一个特征值。由下图可知,步长为1的与步长为2的得到的特征图的大小也不同。步长为1的卷积得到的是 5x5 的特征图,步长为2的卷积得到的是 3x3 的特征图。当我们步长较小时,我们相当于是逐渐的去提取特征,细粒度的去提取特征,这样得到的特征是比较丰富的。当步长比较大时,特征提取比较粗糙,得到的特征比较少,也不丰富。不管输入的图像区域有尺寸是多少,最终经过卷积,都是输出一个特征值,多个特征值组合到一起,同样也是一个特征图。与步长同理,卷积核越小,特征提取的越细腻,卷积核越大,特征提取的越粗糙。不过常用的卷积核尺寸是 3x3 的。具体尺寸大小得根据实际需求而定。下图是步长为1的卷积和步长为2的卷积对比:

2.5 边缘填充方法

总结
通过这一周的学习,我知道了如何自动调整学习率,也理解了Adagrad算法的优缺点,Adagrad算法的主要思想是根据每个参数的梯度历史信息来自适应地调整学习率。但是 Adagrad 算法只是针对不同参数而动态改变学习率,为此我们引入了改进后的RMSProp算法,此算法引入了一个衰减系数 α α α,用来控制梯度平方累加项的贡献程度,可以根据梯度的值来合理的增大和减少学习率,从而避免出现学习率过大,导致梯度来回震荡。避免学习率过小,梯度下降过程十分缓慢。但是用Adagrad算法自动调整学习率也会出现 “梯度爆炸” 现象,为了解决这个问题,我们采用学习率调度的两个方法来改变学习率中 η \eta η的值。在学习完自动调整学习率后,我又学习了卷积神经网络,了解了卷积的作用、卷积特征值的计算方法、以及特征图堆叠、步长与卷积核大小对结果的影响、边缘填充方法,使得我对卷积的过程有了深刻印象。最后,我会一直保持对科研的热爱,继续努力,加油!















 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











