






一、神经网络要如何聚合图结构中的信息呢?
我们先来看下卷积是如何聚合信息的。一个 3×3 的权重矩阵作为滑动窗口,Element-wise 乘上图像对应位置的值后相加求和。它相当于对 (x, y) 这个位置的周边8个方向的邻居,做了加权求和。在图结构中我们没法固定窗口,不过也可以用把邻居信息加权求和的思想来聚合信息。这里的邻居都是在空间上的概念,所以这种方法也叫作 Spatial-based Convolution。
一个图的节点通常是用一个嵌入向量来表征的。信息聚合意思是,让包含一个节点信息的嵌入向量,也表征了它周围节点的信息。
在 Spatial-based Convolution 中,我们需要有两个信息聚合的操作:
- 一个是用邻居特征更新下一层的隐层,叫 Aggregate
- 另一个是把所有的节点的特征聚合成一个代表整个图的向量表征,叫Readout。
二、图神经网络的发展
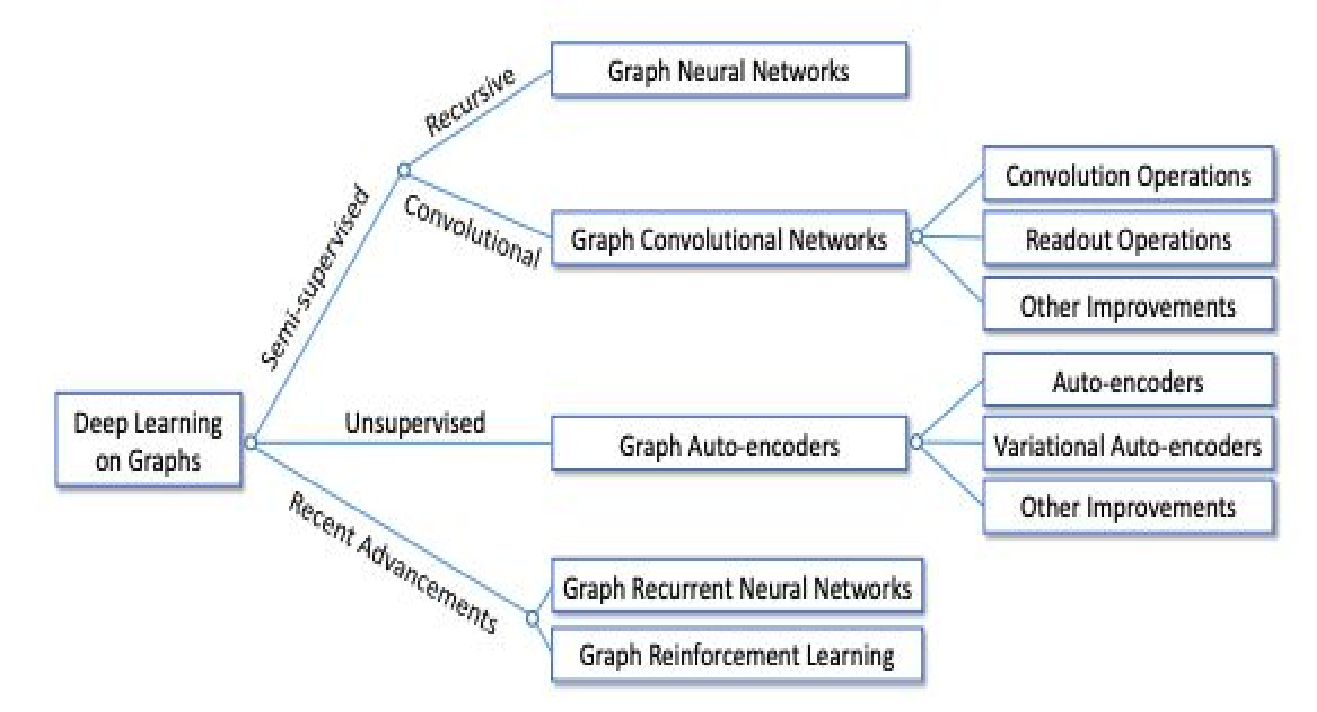
图自编码器的intention 和用途:
获取合适的 embedding 来表示图中的节点不是容易的事,而如果能找到合适的 embedding,就能将它们用在其他任务中。VGAE 通过 encoder-decoder 的结构可以获取到图中节点的 embedding,来支持接下来的任务,如链接预测等。
————————————————
版权声明:本文为CSDN博主「zenRRan」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_27590277/article/details/106264270















 1453
1453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









