








思路
最开始,我想直接爬取这个在线人数条目:

可以看到是能够定位到的,然而却因为这个是动态加载的页面,在获取html后,并无法找到该属性,因此,后来使用charles抓包,想看看视频aid是多少,然而费劲查到之后才发现,网址中的BV号,直接能转成av号…(因为aid可以调用接口查找cid,然后就可以查到在线人数了)

最后有了aid,cid,我们就是常规的爬虫操作了,具体细节实现如下。
具体实现
首先,选中一个你想要找的视频,博主这里是选择了这个(大概率两天内被毙):

我要爬在线观看人数首先要查找aid,在这个网站可以查到:
http://www.atoolbox.net/Tool.php?Id=910

然后我们得到了aid,拼接url去这个网址查找cid:
https://api.bilibili.com/x/web-interface/view?aid=683265582

这里可以看到,分p视频的aid是唯一的,cid是1p一个的,因此,对每一个aid,cid可以拼接url如下,以随机一章为例:
https://api.bilibili.com/x/player.so?id=cid:578550150&aid=683265582

在这里我们搜索online,可以看的到在线人数了就,
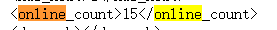
值得注意的是,这个和网站上的在线观看人数不一样,文档中的是偏少的,我合理怀疑他是经过某个函数进行放缩搞得数据哈哈哈,日后想看看hy的真实在线人数哈哈,然后就是常规操作了,拼接字符串,遍历访问,最后再正则表达式提取,代码如下。
完整代码
注意:第一部分的代码中的data.txt就是这个页面复制进来
另外,data用的是a模式,为了模块化,所以有的时候记得要删除一下啊,好啦,可用代码如下,先执行1再执行2哈。
1.
import pandas as pd
import re
str = ''
with open('data.txt', 'r', encoding='utf-8') as f:
str = f.read()
# {"cid":578522269,"page":1,"from":"vupload"
pattern = re.compile('{"cid":(.*?),"page".*?from.*?"part":"(.*?)","dura',re.S)
print(str)
items = re.findall(pattern, str)
print(items)
df = pd.DataFrame()
for item in items:
df_temp = pd.DataFrame({'cid':item[0],
'lecture':item[1]}, index=[0])
df = df.append(df_temp, ignore_index=True)
df.to_csv('data.csv', mode='a', index=False)
import requests
from requests.exceptions import RequestException
import re
import time
import pandas as pd
import random
def g_o_p(url):
# cookie = 'douban-fav-remind=1; gr_user_id=43de4397-8960-4e7f-8cfe-37beeadd9db2; bid=C6zWqEPqK9Q; __gads=ID=00d484a8240cb6a7-22d289a35fcf00ec:T=1638796500:S=ALNI_MaSQwrgAqMwAsokColX7dLZO3BC6A; dbcl2="206773614:ULV1E9V3yl4"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.20677; ll="118137"; __yadk_uid=FEckGGA8QtCVvV7gogugU6KyF891OtUA; _vwo_uuid_v2=D29217A79AE113967136677FF73D3EB65|eafbe5aa32dec2ac20ff0e80187251ba; Hm_lvt_16a14f3002af32bf3a75dfe352478639=1648570091; ck=6E_k; ap_v=0,6.0; __utma=30149280.867113084.1648455141.1648631136.1648737380.8; __utmc=30149280; __utmz=30149280.1648737380.8.6.utmcsr=cn.bing.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt=1; _pk_ref.100001.4cf6=["","",1648737393,"https://www.douban.com/search?source=suggest&q=%E6%8A%95%E5%90%8D%E7%8A%B6"]; _pk_ses.100001.4cf6=*; __utma=223695111.1479750006.1648455141.1648631218.1648737393.8; __utmc=223695111; __utmz=223695111.1648737393.8.6.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/search; __utmb=30149280.6.10.1648737380; __utmb=223695111.3.10.1648737393; _pk_id.100001.4cf6=eef76dfe807d4fb9.1648455140.8.1648737503.1648631233.'
my_headers = [
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
]
# proxy_list = {
# 'http': '192.168.1.9:80',
# 'http': '194.5.193.183:80',
# 'http': '106.54.141.54:3128',
# }
try:
headers = {
'User-Agent': random.choice(my_headers),
# 'Cookie': cookie
}
# response = requests.get(url, headers=headers, proxies=proxy_list)
response = requests.get(url, headers=headers)
print(response.status_code)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def p_o_p(html, data):
pattern = re.compile('<online_count>(.*?)</online_count>',re.S)
items = re.findall(pattern, html)
print(items)
df = pd.DataFrame()
for item in items:
df_temp = pd.DataFrame({'lesson':data,
'people':item}, index=[0])
df = df.append(df_temp, ignore_index=True)
df.to_csv('04.20_online_people.csv', mode='a', index=False)
def modify():
data = pd.read_csv('04.20_online_people.csv')
data = data.drop([i for i in range(0, len(data)) if i%2==1 and i!=0])
data.to_csv('04.20_modified_online_people.csv')
data = pd.read_csv('data.csv')
cid = data['cid']
# 整体思路 先把每个cid取出,对每个cid拼接url,然后正则表达式提取,最后联系课程名称
for i in range(0,31):
url = 'https://api.bilibili.com/x/player.so?id=cid:'+str(cid[i])+'&aid=683265582'
print(url)
html = g_o_p(url)
# time = time.strftime('%H:%M', time.localtime())
p_o_p(html, data['lecture'][i])
time.sleep(random.randint(0,5))
print('------------------------'+str(round(i/31,2)*100)+'%------------------------')
modify()















 6890
6890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









