






1、数据分析和数据挖掘的区别
数据分析:描述和探索性分析,评估现状和修正不足;侧重于实际的业务知识;掌握统计学、数据库、EXCEL、可视化等技术;需结合业务知识统计结果。
数据挖掘:数据采矿过程,发现未知模式和规律;要求数学功底和编程能力;生成模型或规则。
数据挖掘侧重现状的描述和查因,而数据挖掘倾向未知数据的预测。
2、常见的数据结构—字符串、列表、元组、字典
(1)字符串的构造
当字符串中含有双引号时,使用单引号
当字符串中含有单引号时,使用双引号
当字符串中既含有单引号又有双引号时,使用三引号
# 单引号
string1 = ' "i am a student" '
# 双引号
string2 = " 'i' want to study "
# 三引号
string3 = """ "i am a student",'i' want to study """
print(string1,'\n',string2,'\n',string3)
(2)字符串索引、切片
字符串属于序列,每个元素都有顺序
.strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
. rstrip() 删除 string 字符串末尾的指定字符(默认为空格)
注:切片区间索引为“左闭右开”
格式化插入“方法” , .format (values)
# 有限切片
price2 = '24.5元/500g'
# 取出价格,并转换为浮
print(float(price2[0:4]))
ID = '123456198908187890'
# 取后六位,去掉最后一位
print(ID[-7:-1])
# 查询“方法”
price3 = '89.9元/桶'
# 查询“元”所在的位置
print(price3.index('元'))
# 取出价格,并转换为浮点型
print(float(price3[:price3.index('元')]))
# 压缩“方法”
prodName = '乒乓球拍(红双喜) '
# 压缩右侧的空白字符
print(prodName.rstrip())
sentence = '&&&^_^很喜欢,给满分!(^-^)'
# 剔除评论中首尾的特殊字符
print(sentence.strip('&^_^(^-^)'))
# 替换“方法”
tel = '13612347890'
# 隐藏手机号中间四位
print(tel.replace(tel[3:7],'****'))
# 格式化插入“方法”
# 转换为格式化风格
print('尊敬的{}{},您的话费余额为{}元,请及时充值,以免影响通话!'.format('刘','先生',6.78))
# 生成5个有规则的网页链接
for month in [1,2,3,4,5]:
print('http://tianqi.2345.com/t/wea_history/js/20190{0}/60008_20190{0}.js'.format(month))
# 分割“方法”
info = '博佳花园 | 2室2厅 | 94.44平米 | 南 北 | 精装'
print(info.split('|'))

(3)列表属于序列
字符串索引和切片的使用方法在列表上同样适用。
列表的append和extend方法可以实现列表元素的增加,所不同的是append在列表尾部增加一个元素,而extend可以增加多个元素。
列表其他方法
list. count
list. index
list. sort
list3 = [1,10,100,1000,10000]
# 在列表末尾添加
list3.append([20,200,2000,20000])
print(list3)
# 在列表末尾添加20,200,2000,20000四个值
list3 = [1,10,100,1000,10000]
list3.extend([20,200,2000,20000])
print(list3)

(4)元组
• 元组与列表基本相同,都是属于存储数据的容器使用一对圆括号可以构造元组对象。
• 元组同样属于序列。
•注: 元组是不可变对象。
• 构造只包含一个元素的元组,需在元组后面加逗号
列表、元组区别

(5)字典
构造字典对象需要使用大括号表示,即{};
字典元素都是以键值对的形式存在,并且键值对之间用英文状态下的冒号隔开,即key:value
键在字典中是唯一的,不能有重复
字典不属于序列,所以不能下标索引、切片,可转化为列表进行。
如需返回字典的元素,可以使用键索引或者get方法。
字典是可变对象
字典中括号**[ ]**有三大功能:建索引取元素、增加内容、修改内容
dict1 = {'姓名':'张三','年龄':33,'性别':'男','子女':{'儿子':'张四','女儿':'张美'},
'兴趣':['踢球','游泳','唱歌']}
# 取出年龄
print(dict1['年龄'])
# 取出子女中的儿子姓名
print(dict1['子女']['儿子'])
# 取出兴趣中的游泳
print(dict1['兴趣'][1])
# 更改年龄
dict1['年龄']=44
print(dict1)
3、控制流语句
while和for大多数可替换;
如果存在明显的迭代对象(列表、元组、字符串),优先使用for;
下面介绍
(1)if语句
格式:if、elif、else
if condition1:
expression1
elif condition2:
expression2
else:
expression3
(2)for语句
统计b中各元素出现的次数
b = ['a','b','c','a','a','b','c','a','b','b','b']
c= {}
for i in b:
c[i] = b.count(i) # 列表count方法
print(c)
d = list(c.items())
print(d)
d.sort(key =lambda x:x[1],reverse=True) # 列表sort方法
print(d)

(3)while语句
猜数游戏,输入设定范围的随机值,进行盲猜
import random
A=int(input('输入范围最小值'))
B=int(input('输入范围最大值'))
number = random.randint(A,B)
while True:
guess = int(input("请输入一个在{}--{}范围的一个整数".format(A,B)))
if guess == number:
print('dui')
break
elif guess >number:
print('pian da ')
B =guess
else:
print('pain xiao')
A =guess

4、高级函数应用
(1)lambda表达式 又被称之为匿名函数
格式:lambda参数列表:函数体
匿名函数,可以用lambda关键字定义。通过lambda构造的函数可以没有名称,最大特点是“一气呵成”,即在自定义匿名函数时,所有代码可在一行内完成。
虽然匿名函数很灵活,会在很多代码中遇到,但它的最大特点也是它的短板,即无法通过lambda函数构造一个多行而复杂的函数。为了弥补其缺陷,Python提供了另一个关键字def,可以构造逻辑复杂的自定义函数。
# 函数方式
def add(x,y):
return x+y
print(add(3,4))
# lambda表达式
add_lambda = lambda x,y:x+y
print(add_lambda(3,4))
(2)三元运算符
condition = True
print(1 if condition else 2)
condition = False
print(1 if condition else 2)

(3)map函数
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
# # map函数的应用
list1 = [1,2,3,4,5]
r = map(lambda x:x+x,list1)
print(list(r))
m1 = map(lambda x,y:x*x+y,[1,2,3,4,5],[1,2,2,3,3])
print(list(m1))

(4)filter过滤器
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
def is_not_none(s):
return s and len(s.strip())>0
list1 = ["","","abc","hello","word"]
result = filter(is_not_none,list1)
print(list(result))
(5)reduce函数
reduce() 函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
# reduce函数
from functools import reduce
f = lambda x,y:x+y
r = reduce(f,[1,2,3,4,5],10)
print(r)
(6)三大推导式
列表、元组、字典推导式
# 列表推导式
list1 = [1,2,3,4,5,6]
f = map(lambda x:x+x,list1)
print(list(f))
list2 = {i+i for i in list1}
print(list2)
# 有选择性的筛选
list3 = [i**2 for i in list1 if i > 3]
print(list3)
# 集合推导式
list1 = [1,2,3,4,5,6]
list2 = {i+i for i in list1}
print(list2)
# 有选择性的筛选
list3 = {i**2 for i in list1 if i > 3}
print(list3)
# 字典推导
s = {'zhangsan':20,'lisi':13,'wangwu':10 }
# 取出key,变成列表
s_key = [key for key,value in s.items()]
print(s_key)
# key和value互换位置
s1 = {value:key for key,value in s.items()}
print(s1)
# 取出符合条件的值
s2 = {key:value for key,value in s.items() if key =='lisi'}
print(s2)

5、正则表达式
基础知识
专门用于描述或者刻画字符串的内在规律的形式
使用的场景:
1、无法通过切片将字符串的子串返回
2、借助于replace方法无法完成非固定值或非固定位置值的替换
3、借助于split方法无法按照多种值实现字符串的分割
常用的正则符号:
• 原字符:指代直接存在于字符串内部的子串。
• 英文状态的句号点 :指代任意字符(如数字、字母、标点符号、汉字等),但除了换行符\n。
• 反斜杠 \:表示转义符,用于转换含义的符号。
\n:指代换行;
\t:指代Tab制表符;
\d:指代0~9中的任一数字;
\s:指代任意一种空白(如空格、Tab、换行等);
\w:指代字母、数字和下划线中的任意一种;
. :指代句号点本身;
• 英文状态的中括号 []:指代字符集合,当需要特定字符匹配时,可以选择中括号。
• 英文状态的圆括号 ():指代特定内容的截取(抠)。
• 英文状态的问号 ?:表示匹配前一个字符0次或1次。
• 加号 +:表示匹配前一个字符1次及以上。
• 星号 *:表示匹配前一个字符0次及以上。
• 英文状态的大括号 {}
表示匹配前一个字符特定的次数或范围。
{m}:匹配前一个字符m次;
{m,}:匹配前一个字符至少m次;
{m,n}:匹配前一个字符m~n次;
{,n} :匹配前一个字符之多n次;
• 英文状态的大括号 {}:表示匹配前一个字符特定的次数或范围。
正则查找函数:re.findall(…)
替换函数:re.sub(…)
分割函数:re.split(…)
# 导入用于正则表达式的re模块
import re
# 取出字符中所有的天气状态,
string1 ="{ ymd:'2018-01-01',tianqi:'晴',aqiInfo:'轻度污染'},{ymd:'2018-01-02',tianqi:'阴~小雨',aqiInfo:'优'}," \
"{ymd:'2018-01-03',tianqi:'小雨~中雨',aqiInfo:'优'},{ymd:'2018-01-04',tianqi:'中雨~小雨',aqiInfo:'优'}"
# 使用()提取内容,.*?取值
print(re.findall("tianqi:'(.*?)'", string1))

6、爬虫(使用正则和bs4选取数据)
爬虫流程
发送请求:向对方服务器发送待抓取网站的链接URL;
返回请求:在不发生意外的情况下(意外包括网络问题、客户端问题、服务器问题等),对方服务器将会返回请求的内容(即网页源代码)
数据存储:利用正则表达式或解析法对源代码作清洗,并将目标数据存储到本地(txt、csv、Excel等)或数据库(MySQL、SQL Server、MongoDB等)
(1)静态网页爬虫
静态指当在网页点击换页面时,网页网址会变。
下面应用发爬虫,步骤:1、打开https://sh.lianjia.com/ershoufang/pudong/pg1/ 2、按F12 3、按F5刷新 4、随便点一个选项 5、找Headers下面的Request Headers ,然后下拉找到User-agent

import requests
import bs4
import pandas as pd
url = r'https://sh.lianjia.com/ershoufang/pudong/pg1/'
# 反爬虫
Headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
response = requests.get(url,headers = Headers)
# print(response)
responses = bs4.BeautifulSoup(response.text)
# print(responses)
name = [i.text.strip() for i in responses.findAll(name='a',attrs={'data-el':'region'})]
type = [i.text.split('|')[0].strip() for i in responses.findAll(name='div',attrs={'class':'houseInfo'})]
size = [float(i.text.split('|')[1].strip()[:-2]) for i in responses.findAll(name='div',attrs={'class':'houseInfo'})]
direction = [i.text.split('|')[2].strip() for i in responses.findAll(name='div',attrs={'class':'houseInfo'})]
repair = [i.text.split('|')[3].strip() for i in responses.findAll(name='div',attrs={'class':'houseInfo'})]
floor = [i.text.split('|')[4].strip() for i in responses.findAll(name='div',attrs={'class':'houseInfo'})]
year = [i.text.split('|')[5].strip() for i in responses.findAll(name='div',attrs={'class':'houseInfo'})]
toal = [float(i.text[:-1])for i in responses.findAll(name='div',attrs={'class':'totalPrice'})]
price = [int(i.text[2:-4]) for i in responses.findAll(name='div',attrs={'class':'unitPrice'})]
print(type)
resule = pd.DataFrame({'name':name,'type':type,'size':size,'direction':direction,'repair':repair,'floor':floor,'year':year,'toal':toal})
print(resule)

(2)动态网页爬虫
动态网页爬虫-----变化页数,网址不变
url为.js后缀的用正则做
动态网页爬虫步骤:1、打开网址http://tianqi.2345.com/wea_history/58362.htm 2、按F12 3、选择JS 4、点击下一页 5、点击name下文件 6,Headers-----General-----Request URL 7、复制URL

import re
import requests
import bs4
import pandas as pd
url = r'http://tianqi.2345.com/t/wea_history/js/202004/58362_202004.js'
response = requests.get(url)
data = re.findall("ymd:'([\d-]+)',",response.text)
wendu = re.findall("yWendu:'([\d-]+)℃',",response.text)
tianqi = re.findall("tianqi:'(.*?),",response.text)
aqi = re.findall("aqiInfo:'(.*?),",response.text)
print(aqi )
result = pd.DataFrame({'data':data,'wendu':wendu,'tianqi':tianqi,'aqi':aqi})
print(result)

7、数组
数组和列表的区别:
1)列表只是一种数据的存储容器,它不具有任何计算能力!
借助于array函数可以将列表或元组转换为数组
2)数组可适用于列表的索引和切片;数组可指定行列索引,多列表先取出列表,再取元素[][]。
3)数组计算方便
数组元素的返回
1)在一维数组中,列表的所有索引方法都可以使用在数组中,而且还可以使用间断索引和逻辑索引;
2)在二维数组中,位置索引必须写成[rows,cols]的形式,方括号的前半部分用于锁定二维数组的行索引,后半部分用于锁定数组的列索引;
3)如果需要获取二维数组的所有行或列元素,那么,对应的行索引或列索引需要用英文状态的冒号表示;
数学运算符

常用的数学函数

常用的统计函数
**注:**axis=0 计算各列的统计值
axis=1 计算各行的统计值

import numpy as np
a = np.array([[1,2,3,4,5,6,7],[1,2,3,4,5,6,7]])
b = np.array([22,1,4,55,4,3])
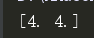
print(np.median(a,axis=1))
``
`
函数:
随机整数:np.random.randint()
随机均匀分布:np.random.uniform()
随机正态分布:np.random.normal()
range(start,end,step) 返回**列表list**,不含end
np.arange(start,end,step) 返回**array**,不含end
案例:设定一场赌局,有1000元成本,赌局赢输概率0.5,赌1500局,赢一局8元,输一局8元,输出每次的剩余money
```python
import numpy as np
import matplotlib.pyplot as plt
R = np.random.uniform(0,1,1500) # 均匀分布
# print(R)
initial = 1000
money = [initial]
for i in R:
if i >0.5:
initial += 8
else:
initial -= 8
money.append(initial)
print(money)
print("最终剩余的money",initial)
plt.plot(range(1501),money)
plt.show()

每次赌局后剩余money,生成的仿真数据图:
















 2197
2197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









