







 本文深入探讨SDW-MWF(语音失真加权多通道维纳滤波器),介绍了它作为GSC的改进在语音增强中的应用。通过对损失函数的优化,SDW-MWF在降低噪声残差的同时考虑了语音失真,提供了更优的权向量计算。此外,文章对比了空域SDW-MWF和传统方法,并分析了不同μ值对性能的影响。
本文深入探讨SDW-MWF(语音失真加权多通道维纳滤波器),介绍了它作为GSC的改进在语音增强中的应用。通过对损失函数的优化,SDW-MWF在降低噪声残差的同时考虑了语音失真,提供了更优的权向量计算。此外,文章对比了空域SDW-MWF和传统方法,并分析了不同μ值对性能的影响。
语音失真加权多通道维纳滤波器SDW-MWF
上一篇介绍了“GSC波束形成的推导。”
GSC-SDW-MWF可以看做是在上GSC的一种改进,本章介绍其在语音增强上的应用,GSC的结构如下图所示。
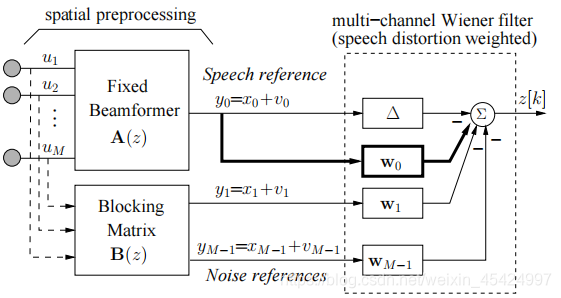
M为麦克风个数,其中固定波束形成器输出的信号
y
0
y_{0}
y0包括期望方向的信号
x
0
x_{0}
x0和残余噪声
v
0
v_{0}
v0。
y
1
,
.
.
,
y
M
−
1
y_{1} ,..,y_{M-1}
y1,..,yM−1为经过阻塞矩阵后的多个信号,由于可能产生的信号泄露
y
n
[
k
]
=
x
n
[
k
]
+
v
n
[
k
]
,
n
=
1
…
M
−
1
y_{n}[k]=x_{n}[k]+v_{n}[k], n=1 \ldots M-1
yn[k]=xn[k]+vn[k],n=1…M−1
其中也包含部分期望方向泄露的信号
x
n
[
k
]
x_{n}[k]
xn[k]。
与在GSC中的不一样的地方是,我们在这里会对每个麦克风接收L点的信号
y
n
[
k
]
\mathbf{y}_{n}[k]
yn[k]并将其拼成长度为M×L的向量
y
[
k
]
\mathbf{y}[k]
y[k],即
y
n
[
k
]
=
[
y
n
[
k
]
y
n
[
k
−
1
]
…
y
n
[
k
−
L
+
1
]
]
T
n
=
1
…
M
−
1
\begin{array}{c} \mathbf{y}_{n}[k]=\left[y_{n}[k] y_{n}[k-1] \ldots y_{n}[k-L+1]\right]^{T} \\ n=1 \ldots M-1 \end{array}
yn[k]=[yn[k]yn[k−1]…yn[k−L+1]]Tn=1…M−1
y
[
k
]
=
[
y
1
T
[
k
]
y
2
T
[
k
]
…
y
M
−
1
T
[
k
]
]
T
\mathbf{y}[k]=\left[\mathbf{y}_{1}^{T}[k] \mathbf{y}_{2}^{T}[k] \ldots \mathbf{y}_{M-1}^{T}[k]\right]^{T}
y[k]=[y1T[k]y2T[k]…yM−1T[k]]T
注意,这里不包括第一个参考麦克风的接收信号,然后可以将
y
[
k
]
\mathbf{y}[k]
y[k]写为每个麦克风的泄露值与噪声向量的和。
y
∣
k
]
=
x
[
k
]
+
v
[
k
]
\mathbf{y} \mid k]=\mathbf{x}[k]+\mathbf{v}[k]
y∣k]=x[k]+v[k]
现在我们希望得到一个长度为(M-1)×L权向量
w
[
k
]
=
[
w
1
T
[
k
]
w
2
T
[
k
]
…
w
M
−
1
T
[
k
]
]
T
\mathbf{w}[k]=\left[\mathbf{w}_{1}^{T}[k] \mathbf{w}_{2}^{T}[k] \ldots \mathbf{w}_{M-1}^{T}[k]\right]^{T}
w[k]=[w1T[k]w2T[k]…wM−1T[k]]T
去对消固定波束形成没有消除掉残余噪声
v
0
v_{0}
v0
得到残差:
z
[
k
]
=
y
0
[
k
]
−
w
T
[
k
]
y
[
k
]
式(
1
)
=
x
0
[
k
]
+
(
v
0
[
k
]
−
w
T
[
k
]
v
[
k
]
)
⏟
e
v
[
k
]
−
w
T
[
k
]
x
[
k
]
⏟
e
x
[
k
]
\begin{aligned} z[k] &=y_{0}[k]-\mathbf{w}^{T}[k] \mathbf{y}[k] \ \ \ \ \ \ \ \ 式(1)\\ &=x_{0}[k]+\underbrace{\left(v_{0}[k]-\mathbf{w}^{T}[k] \mathbf{v}[k]\right)}_{e_{v}[k]}-\underbrace{\mathbf{w}^{T}[k] \mathbf{x}[k]}_{e_{x}[k]} \end{aligned}
z[k]=y0[k]−wT[k]y[k] 式(1)=x0[k]+ev[k]
(v0[k]−wT[k]v[k])−ex[k]
wT[k]x[k]
其中
e
v
[
k
]
e_{v}[k]
ev[k]为噪声的残差,
e
x
[
k
]
e_{x}[k]
ex[k]为语音失真。
GSC中的维纳滤波器就是最小化噪声残差
e
v
[
k
]
e_{v}[k]
ev[k]。
即损失函数为
J
G
S
C
(
w
[
k
]
)
=
ε
v
2
[
k
]
=
E
{
∣
v
0
[
k
]
−
w
T
[
k
]
v
[
k
]
∣
2
}
J_{G S C}(\mathbf{w}[k])=\varepsilon_{v}^{2}[k]={E}\left\{\left|v_{0}[k]-\mathbf{w}^{T}[k] \mathbf{v}[k]\right|^{2}\right\}
JGSC(w[k])=εv2[k]=E{
v0[k]−wT[k]v[k]
2}
最小化上式,得最优权
w
[
k
]
=
E
{
v
[
k
]
v
T
[
k
]
}
−
1
E
{
v
[
k
]
v
0
[
k
]
}
\mathbf{w}[k]={E}\left\{\mathbf{v}[k] \mathbf{v}^{T}[k]\right\}^{-1} {E}\left\{\mathbf{v}[k] v_{0}[k]\right\}
w[k]=E{v[k]vT[k]}−1E{v[k]v0[k]}
其中
v
[
k
]
\mathbf{v}[k]
v[k]和
v
0
[
k
]
v_{0}[k]
v0[k]都可以通过噪声估计,如MCRA求得。
但是从式(1)中可以看到,GSC其实没有考虑信号泄露带来的语音失真。
还有一点值得注意,即阻塞矩阵支路是不包含参考麦克风的信号
y
0
[
k
]
\mathbf{y}_{0}[k]
y0[k]的,否则维纳滤波的最优权就会变为:
w
0
[
k
]
=
u
Δ
+
1
,
w
n
[
k
]
=
0
,
n
=
1
…
M
−
1
\mathrm{w}_{0}[k]=\mathbf{u}_{\Delta+1}, \quad \mathbf{w}_{n}[k]=\mathbf{0}, n=1 \ldots M-1
w0[k]=uΔ+1,wn[k]=0,n=1…M−1
u
Δ
+
1
\mathbf{u}_{\Delta+1}
uΔ+1为只有第L个元素为1的one-hot向量。
Speech Distortion Weighted Multichannel WienerFilter(SDW-MWF)介绍
SDW-MWF实际上就是把信号泄露带来的语音失真考虑进去来得到一个最优权向量。其损失函数为:
J
(
w
[
k
]
)
=
ε
v
2
[
k
]
+
1
μ
ε
x
2
[
k
]
=
E
{
∣
v
0
[
k
]
−
w
T
[
k
]
v
[
k
]
∣
2
}
+
1
μ
E
{
∥
w
T
[
k
]
x
[
k
]
∣
2
}
\begin{aligned} J(\mathbf{w}[k]) &=\varepsilon_{v}^{2}[k]+\frac{1}{\mu} \varepsilon_{x}^{2}[k] \\ &={E}\left\{\left|v_{0}[k]-\mathbf{w}^{T}[k] \mathbf{v}[k]\right|^{2}\right\}+\frac{1}{\mu} {E}\left\{\|\left.\mathbf{w}^{T}[k] \mathbf{x}[k]\right|^{2}\right\} \end{aligned}
J(w[k])=εv2[k]+μ1εx2[k]=E{
v0[k]−wT[k]v[k]
2}+μ1E{∥wT[k]x[k]
2}
其中
μ
\mu
μ用来在语音失真和残余噪声能量间进行权衡,
μ
=
1
\mu = 1
μ=1时就是GSC,
μ
=
0
\mu = 0
μ=0时
最小化损失函数,得到最优权:
w
[
k
]
=
[
E
{
v
[
k
]
v
T
[
k
]
}
+
1
μ
E
{
x
[
k
]
x
T
[
k
]
}
]
−
1
E
{
v
[
k
]
v
0
[
k
]
}
\mathbf{w}[k]=\left[{E}\left\{\mathbf{v}[k] \mathbf{v}^{T}[k]\right\}+\frac{1}{\mu} {E}\left\{\mathbf{x}[k] \mathbf{x}^{T}[k]\right\}\right]^{-1} {E}\left\{\mathbf{v}[k] v_{0}[k]\right\}
w[k]=[E{v[k]vT[k]}+μ1E{x[k]xT[k]}]−1E{v[k]v0[k]}
我们假设信号和噪声之间相互独立,因此纯净信号的自相关矩阵可以写为
E
{
x
[
k
]
x
T
[
k
]
}
=
E
{
y
[
k
]
y
T
[
k
]
}
−
E
{
v
[
k
]
v
T
[
k
]
}
{E}\left\{\mathbf{x}[k] \mathbf{x}^{T}[k]\right\}={E}\left\{\mathbf{y}[k] \mathbf{y}^{T}[k]\right\}-{E}\left\{\mathbf{v}[k] \mathbf{v}^{T}[k]\right\}
E{x[k]xT[k]}=E{y[k]yT[k]}−E{v[k]vT[k]}
由于SDW-MWF考虑了语音失真,因此参考麦克风的信号也可能被包括进去。
参考论文:
[1] Doclo S , Spriet A , Wouters J , et al. Speech Distortion Weighted Multichannel Wiener Filtering Techniques for Noise Reduction[M]. 2005.
论文中还讨论了频域的SDW-MWF的实现
空域SDW-MWF
在下面这篇文章中,作者抛弃了上述基于GSC的先进行多通道空域滤波,再结合SDW-MWF进行单通道后置滤波的方法,而是直接在空域去进行多通道语音增强,这样还同时避免了GSC需要计算导向矢量但是导向矢量可能难以准确得到的情况。下面进行介绍。
[2] Cornelis B , Moonen M , J Wouters. Performance Analysis of Multichannel Wiener Filter-Based Noise Reduction in Hearing Aids Under Second Order Statistics Estimation Errors[J]. Audio, Speech, and Language Processing, IEEE Transactions on, 2011, 19(5):p.1368-1381.
类似于MVDR中的推导
假设N个阵列某时刻接收信号
y
y
y, 语音信号
x
x
x和噪声
v
v
v都是N维向量。
y
=
x
+
v
\mathbf{y}=\mathbf{x}+\mathbf{v}
y=x+v
并且有参考麦克风的接收信号
Y
ref
=
e
ref
H
y
Y_{\text {ref }}=\mathbf{e}_{\text {ref }}^{H} \mathbf{y}
Yref =eref Hy
e
ref
=
[
0
…
0
1
0
…
]
N
×
1
T
\mathbf{e}_{\text {ref }}=\left[\begin{array}{llll}0 & \ldots & 0 & 1 & 0 & \ldots\end{array}\right]^{T}_{N×1}
eref =[0…010…]N×1T
同样参考麦克风的接收信号同样可以被分解为
Y
r
e
f
=
X
r
e
f
+
V
r
e
f
Y_{\mathrm{ref}}=X_{\mathrm{ref}}+V_{\mathrm{ref}}
Yref=Xref+Vref
目的是通过阵列N点接收信号去恢复
X
ref
X_{\text {ref }}
Xref 。
这里SDW-MWF的损失函数目的是最小化语音失真的能量同时尽可能降低残留噪声的能量。
则损失函数写为:
J
M
W
F
=
E
{
∣
X
r
e
f
−
w
H
x
∣
2
}
+
μ
E
{
∣
w
H
v
∣
2
}
J_{\mathrm{MWF}}={E}\left\{\left|X_{\mathrm{ref}}-\mathrm{w}^{H} \mathrm{x}\right|^{2}\right\}+\mu {E}\left\{\left|\mathrm{w}^{H} \mathrm{v}\right|^{2}\right\}
JMWF=E{
Xref−wHx
2}+μE{
wHv
2}
求解得最优权为:
w
M
W
F
=
(
R
x
+
μ
R
v
)
−
1
R
x
e
r
e
f
=
R
v
−
1
R
x
e
r
e
f
μ
+
R
v
−
1
R
x
\begin{aligned} w_{M W F} &=\left(R_{x}+\mu R_{v}\right)^{-1} R_{x} e_{r e f} \\ &=\frac{R_{v}^{-1} R_{x} e_{r e f}}{\mu+R_{v}^{-1} R_{x}} \end{aligned}
wMWF=(Rx+μRv)−1Rxeref=μ+Rv−1RxRv−1Rxeref
其中
R
y
=
E
{
y
y
H
}
,
R
x
=
E
{
x
x
H
}
,
R
v
=
E
{
v
v
H
}
\mathbf{R}_{y}={E}\left\{\mathbf{y y}^{H}\right\}, \quad \mathbf{R}_{x}={E}\left\{\mathbf{x} \mathbf{x}^{H}\right\}, \quad \mathbf{R}_{v}={E}\left\{\mathbf{v v}^{H}\right\}
Ry=E{yyH},Rx=E{xxH},Rv=E{vvH}
然后作者首先推导了单目标时的情况。
单目标时,阵列接收的语音信号在频域可以被写为某时刻的语音信号的实部值与导向矢量的乘积,即
x
=
a
S
\mathbf{x}=\mathbf{a} S
x=aS
上面
a
a
a表示导向矢量,S为某时刻语音的实部
这时接收语音的自相关矩阵(秩为1)可以写为
R
x
=
P
s
a
a
H
\mathbf{R}_{x}=P_{s} \mathbf{a a}^{H}
Rx=PsaaH
其中
P
s
=
E
{
∣
S
∣
2
}
P_{s}=\mathcal{E}\left\{|S|^{2}\right\}
Ps=E{∣S∣2}表示语音信号的功率。通过使用了一些矩阵求逆的trick,最终的最优权变为:
w
opt.
=
R
v
−
1
a
⋅
P
s
A
r
e
f
∗
μ
+
ρ
式(
2
)
\mathbf{w}^{\text {opt. }}=\mathbf{R}_{v}^{-1} \mathbf{a} \cdot \frac{P_{s} A_{\mathrm{ref}}^{*}}{\mu+\rho}\ \ \ \ \ \ \ 式(2)
wopt. =Rv−1a⋅μ+ρPsAref∗ 式(2)
其中
A
r
e
f
∗
=
a
H
e
r
e
f
A_{\mathrm{ref}}^{*}=\mathbf{a}^{H} \mathbf{e}_{\mathrm{ref}}
Aref∗=aHeref,
ρ
=
P
s
a
H
R
v
−
1
a
\rho=P_{s} \mathbf{a}^{H} \mathbf{R}_{v}^{-1} \mathbf{a}
ρ=PsaHRv−1a。
但是式(2)需要知道导向矢量,于是作者提出可以不求导向矢量,只由语音和噪声的自相关矩阵来得到最优权的值。通过将ρ重写为
ρ
=
P
s
a
H
R
v
−
1
a
=
P
s
Tr
{
R
v
−
1
a
a
H
}
=
Tr
{
R
v
−
1
R
x
}
\begin{aligned} \rho &=P_{s} \mathbf{a}^{H} \mathbf{R}_{v}^{-1} \mathbf{a} \\ &=P_{s} \operatorname{Tr}\left\{\mathbf{R}_{v}^{-1} \mathbf{a} \mathbf{a}^{H}\right\} \\ &=\operatorname{Tr}\left\{\mathbf{R}_{v}^{-1} \mathbf{R}_{x}\right\} \end{aligned}
ρ=PsaHRv−1a=PsTr{Rv−1aaH}=Tr{Rv−1Rx}
式(2)变为
w
opt
=
R
v
−
1
R
x
e
ref
μ
+
Tr
{
R
v
−
1
R
x
}
式(
3
)
\mathbf{w}^{\text {opt }} =\frac{\mathbf{R}_{v}^{-1} \mathbf{R}_{x} \mathbf{e}_{\text {ref }} }{\mu+\operatorname{Tr}\left\{\mathbf{R}_{v}^{-1} \mathbf{R}_{x}\right\}}\ \ \ \ 式(3)
wopt =μ+Tr{Rv−1Rx}Rv−1Rxeref 式(3)
尽管最终的这个表达式由单目标情况下推导出来,但是其同样适用于存在干扰的情况。
当
μ
=
1
\mu=1
μ=1 得到传统 MWF, 当
μ
<
1
\mu<1
μ<1 会保存更多的期望信号,但同时减小了对干扰和噪声的抑制, 当
μ
>
1
\mu>1
μ>1 我们会增大对噪声得抑制但代价是语音失真, 当
μ
=
0
\mu=0
μ=0 则退化为 MVDR 。

















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









