







 本文详细介绍了计算机指令系统的各个方面,包括指令格式、寻址方式以及CISC和RISC的基本概念。讲解了指令的基本格式、不同地址数的指令格式以及扩展操作码的划分方法等内容。
本文详细介绍了计算机指令系统的各个方面,包括指令格式、寻址方式以及CISC和RISC的基本概念。讲解了指令的基本格式、不同地址数的指令格式以及扩展操作码的划分方法等内容。
第四章 指令系统
目录
4.1 指令格式
指令是指示计算机执行某种操作的命令,一台计算机的所有指令的集合构成该机的指令系统,也称为指令集。
1.指令的基本格式
一条指令就是机器语言的一个语句,是一组有意义的二进制代码。一条指令一般会包括操作码字段和地址码字段两部分。其中操作码指出指令中该指令应执行什么性质的操作和使用方法等的关键信息。地址码给出被操作的信息的地址。
指令的长度是指一条指令中所包含的二进制代码的位数,取决于操作码的长度,地址码的长度和地址码的个数。指令长度与机器字长没有固定关系,指令字长等于机器字长的称之为单字长指令,等于双倍机器字长的为双字长指令,等于半个机器字长的为半字长指令
指令系统中,如果所有指令字长都相同,则为定长指令字结构;如果指令字长不相同则为变长指令字结构。
根据指令中操作数地址码的不同,分为以下几种格式:
一.零地址指令
使用零地址指令一般会有以下两种情况:
- 不需要操作数,比如停机、同操作、关中断指令
- 在堆栈计算机中,两个操作数隐含存放在栈顶和次栈顶
二.一地址指令
- 只需要单操作数,比如自增、自减、取反、求补等,指令含义 O P ( A 1 ) → A 1 OP(A_1)\to A_1 OP(A1)→A1,完成一条指令需要三次访存,取指令→读A1→写A1
- 需要两个操作数,但是其中一个操作数位于某个寄存器, ( A C C ) O P ( A 1 ) → A C C (ACC)OP(A_1)\to ACC (ACC)OP(A1)→ACC,这种只需要两次访存:取指令→读A1
3.二地址指令
| OP | A1 | A2 |
|---|
常用语需要两个操作数的算术运算、逻辑运算相关指令,指令含义$ ( A 1 ) O P ( A 2 ) → A 1 (A_1)OP(A_2)\to A_1 (A1)OP(A2)→A1,完成一条指令需要四次访存,分别是取指令→读A1→读A2→写A1
4.三地址指令
| OP | A1 | A2 | A3(存结果) |
|---|
常用语需要两个操作数的算术运算、逻辑运算相关指令,指令含义$ ( A 1 ) O P ( A 2 ) → A 3 (A_1)OP(A_2)\to A_3 (A1)OP(A2)→A3,完成一条指令需要四次访存,分别是取指令→读A1→读A2→写A3
5.四地址指令
| OP | A1 | A2 | A3(存结果) | A4(下址) |
|---|
对于其他指令,取址后PC+1,指向下一条指令;而对于四地址指令,则会直接跳到A4指向的地址,PC也会指向A4。完成一条指令需要四次访存,分别是取指令→读A1→读A2→写A3
指令字长:一条指令的总长度,可变,有着半字长指令、单字长指令和双字长指令等。
机器字长:CPU进行一次整数运算所能处理的二进制数据位数,同ALU直接相关
存储字长:一个存储单元中二进制代码的位数,同MDR位数相同
在指令中,有定长操作码也有变长操作码。其区别是操作码的长度是否固定。另外也有定长指令系统和变长指令系统
2.定长操作码指令格式
定长操作码指令在指令的最高位部分分配若干位表示操作码。可以简化计算机硬件设计,提高指令译码和识别的速度。当计算机字长超过32位后,这是普遍做法。定长操作码中,观察操作码位数可以知道该系统支持多少个指令
3.扩展操作码指令格式
为了在指令字长有限的前提下能够容纳较为丰富的指令种类,可以采用可变长度的操作码。但是这会增加指令译码和分析的难度,使得控制器的设计复杂化。最常见的变长操作码方法就是扩展操作码,使得操作码的长度随着地址码的减少而增加,不同地址数的指令可具有不同长度的操作码,从而有效缩短指令字长。通过不同长度的操作码来确定是何种格式的指令。
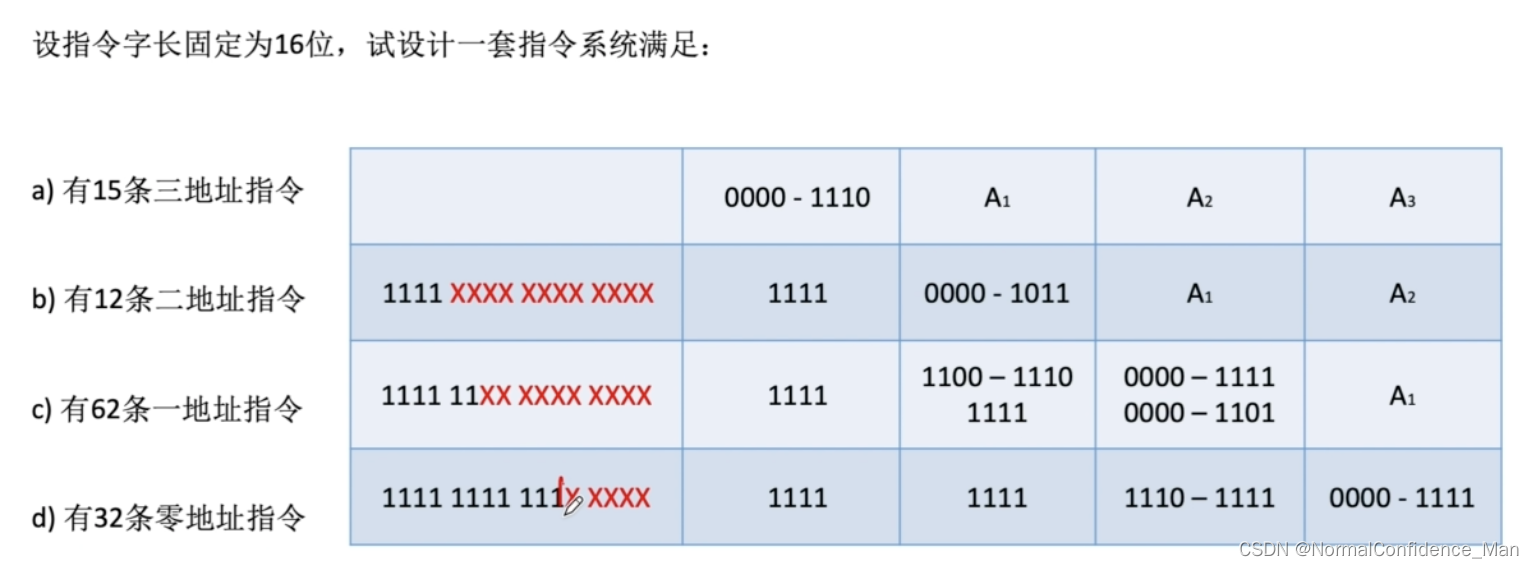
扩展操作码划分方法一
比如一个指令字长为16位的计算机,假设每个地址码占4位,如果是3地址指令,则地址位占12个,操作码占4个位,能表示总共15条指令。
如果是二地址指令,那么指令前4位必须是1111,指令格式为:
| 1111 | 操作码(4bit) | 地址码(8bit) |
|---|
这样计算机就可以识别出二地址指令了,这也是三地址指令只能表示24-1条指令的原因。同理,二地址指令也只能表示15条指令,因为一地址指令必须是由8个1开头,特殊的是零地址指令,能够表示16条指令。
设计扩展操作码的时候,不允许短码是长码的前缀,并且个指令操作码不能重复。
扩展操作码划分方法二
根据各种指令的个数划分操作码
设地址长度为n,那上一层流出m中状态,下一层可扩展出m*2n种状态
4.2 指令的寻址方式
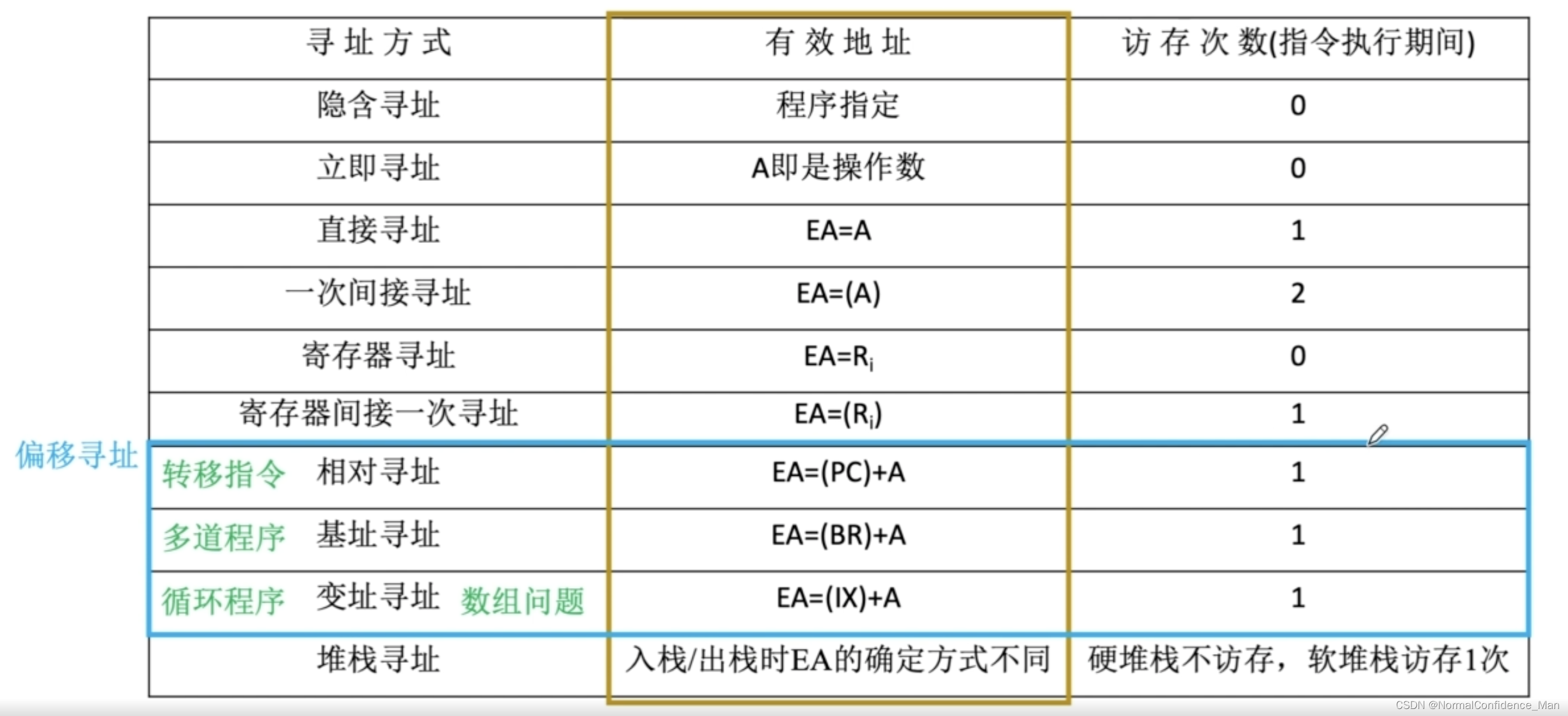
寻址方式是指寻找指令或者操作数有效地址的方式,即确定本条指令的数据地址以及下一条待处执行指令的地址方法。指令中的字段不代表操作数的真实地址(EA),而是一种形式地址(A),形式地址结合寻址方式可以得出存储器中的真实地址。
一、指令寻址和数据寻址
寻址方式分为指令寻址和数据寻址两大类,寻找下一条要执行的指令位指令寻址,而寻找本条指令的数据地址称为数据寻址
二、指令寻址的两种方式
顺序寻址
通过程序计数器PC加1,自动形成下一跳指令的地址。对于某些情况还需要具体分析:
- 对于按字寻址的,那么每次程序计数器PC是加一的,因为一条指令也是一个字这么长。
- 对于按字节寻址的,比如一个指令16bit,那么程序计数器应该是 P C → P C + 2 PC\to PC+2 PC→PC+2
- 上述两种情况都是对于定长指令字结构的,而对于变长指令字结构,则计算机会先读入第一个字,根据第一个字中的信息判断该指令的长度(详情请看上面的“扩展操作码指令格式”),然后决定执行完该指令后,PC应该加多少。
跳跃寻址
通过转移指令JMP来决定该执行哪条指令,该指令会强制将PC中的值改为对应值
三、常见数据寻址方式
对于数据寻址来说,跳跃寻址指令JMP使用的是相对地址,指示的是从当前程序计数器指向的位置向前跳跃多少条指令。
计算机中数据寻址方式有许多种,并且对于一条指令中的不同的地址码,可能会采用不同的寻址方式,因此一般在每一个地址码前,需要若干个二进制位来表示采用的是什么寻址方式,这就是指令中的寻址特征部分,加入了寻址特征后,一条指令的结构如下:
| 操作码(OP) | 寻址特征1 | 形式地址1 | 寻址特征2 | 形式地址2 |
|---|
1.隐含寻址
这种类型的指令不明显给出操作数地址,而是在指令中隐含操作数的地址。比如单地址指令就只给出了第一个操作数的地址,而隐式地指出ACC寄存器为第二个操作数地址。其优点在于有利于缩短指令字长,缺点是需要增加存储操作或者隐含地址的硬件。
2.立即(数)寻址
这种类型的指令的地址字段存储的不是操作数的地址,而是操作数本身,又称为立即数,通常采用补码表示,其寻址特征为#。优点是指令在执行的时候不需要访问主存,直接取位于指令地址段的操作数,甚至不需要访问寄存器,速度最快,缺点是立即数的范围会收到指令段长度的约束。
3.直接寻址
指令中形式地址A是操作数就是真实地址EA。
直接寻址的优点是简单,指令在执行阶段只访问一次主存,不需要专门的计算操作数的过程。缺点是指令中地址码的位数决定了该指令操作数的寻址范围。(指令中地址码的位数可能会小于机器字长)
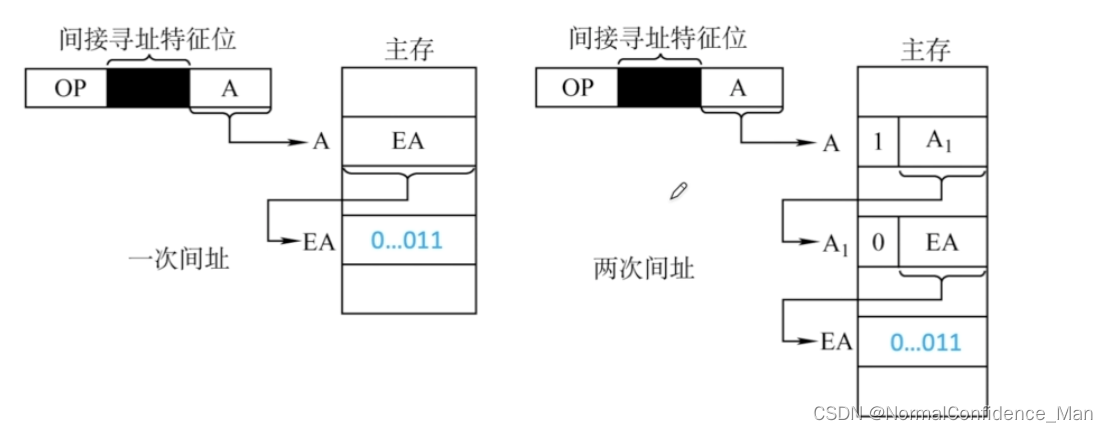
4.间接寻地址
间接寻址的指令的地址字段给出的形式地址不是操作数的真正地址,而是操作数有效地址所在的存储单元的地址,也就是操作数地址的地址。间接寻址可以是一次间接寻址,也可以是多次间接寻址。
优点:间接寻址扩大了指令的寻址范围(有效地址EA的位数大于形式地址A的卫视),并且便于编制程序。
缺点:n次间接寻址需要访问n+1次内存,因此降低了效率
5.寄存器寻址
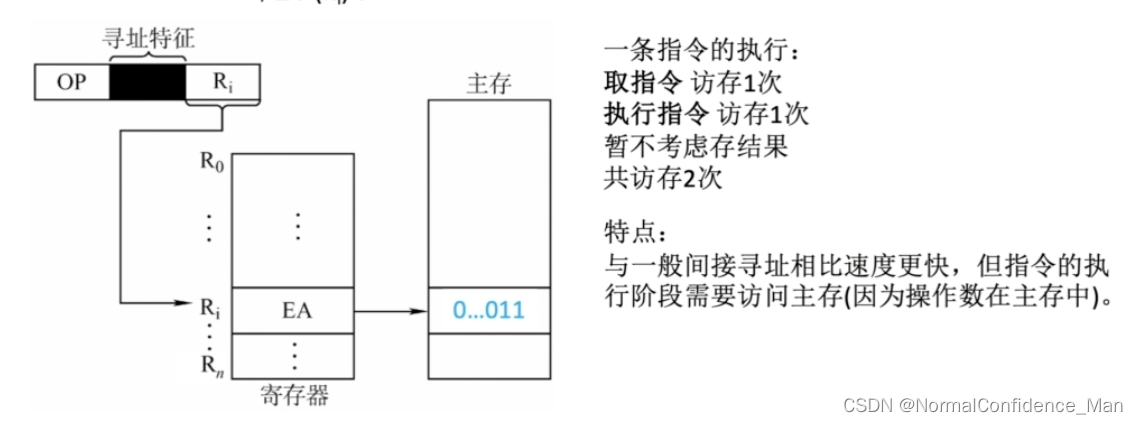
寄存器寻址是指令字中直接给出操作数所在的寄存器编号,就是EA=Ri ,在执行指令的时候不需要访存(取指令需要)。寄存器寻址的优点在于执行期间不需要访问主存,而访问寄存器的速度远快于寄存器,并且寄存器数量少,因此指令中的地址码也比较短,指令长度也短。缺点是寄存器价格昂贵,计算机中的寄存器个数有限。
6.寄存器间接寻址
寄存器间接寻址是指寄存器Ri中给出的不是一个操作数,而是操作数所在的主存单元的地址,即EA=(Ri)
7.相对寻址
相对寻址是把PC的内容加上指令格式中的形式地址A而形成操作数的有效地址。即EA=(PC)+A。其中A是相对于下一条指令地址的位偏移量,因为只要取出了指令,PC就会进行+1操作,PC+1操作是在执行指令前就已经完成了的。
相对寻址的优点是操作数的地址不是固定的,随着PC值的变化而变化,而且指令地址之间相差一个固定值,因此便于程序浮动(一段代码在程序内浮动),广泛用于转移指令。比如将for循环,就会使用到相对寻址会比较方便,因为for循环语句体内的语句的相对顺序是相对固定的。
8.基址寻址
基址寻址指的是将CPU中基址寄存器(BR)(在操作系统中被称为“重定位寄存器”)的内容加上指令格式中形式地址A而形成操作数的有效地址,即EA=(BR)+A,其中基址寄存器既可以采用专用寄存器,又可以采用通用寄存器。
基址寄存器是面向操作系统的,其内容是由操作系统规定,普通程序员无权干预。主要用于解决程序逻辑空间与存储器物理空间的无关性,比如,使得程序中的紧密相连的数组在物理储存器中也是存储在相邻位置。程序运行前,CPU将BR值就改为该程序的起始地址。
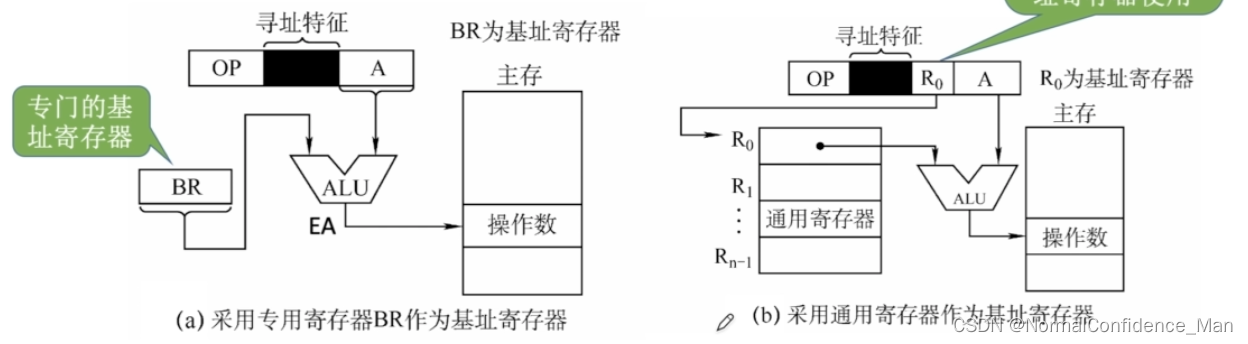
采用通用寄存器作为BR的时候,需要在指令中指出使用的是哪个通用寄存器,若寄存器数量n,则需要
l
o
n
g
2
n
long_2 n
long2n个R0位。
在基址寻址的指令中,对地址码需要给出基址寄存器的地址和地址偏移量两个信息。
在程序执行过程中,基址寄存器内容不变,形式地址内容可变(作为偏移量)。其优点是1.可以扩大寻址范围,2.用户不需要考虑自己的程序处于主存哪个位置,有利于多道程序设计。3.有利于设计浮动程序(这类程序能在整个内存中浮动和移动)
9.变址寻址
变址寻址是指有效地址EA等于指令字中的形式地址A与变址寄存器IX的内容之和。其中IX为变址寄存器,可以将通用或者专用寄存器用作基址寄存器。变址寄存器是面向用户的,这点和基址寻址相反。
在程序执行过程中变址寄存器IX可以由用户改变,是地址中的偏移量,但是形式地址A保持不变,是地址的基地址,这也和基址寻址相反。在对数组的处理中,可以将A设定为数组首地址,不断改变变址寄存器IX的内容从而访问数组。
10.基址和变址复合寻址
基址寻址和变址寻址并不冲突,可以一同使用。假设程序的开头在内存地址100处,然后需要访问数组头位于110处的数组中的0号,3号和7号元素,那么BR将设为100,然后相对地址A设为10,而程序中会将IX分别设为0、3、7,其寻址式子为
E
A
=
(
I
X
)
+
(
(
B
R
)
+
A
)
EA=(IX)+((BR)+A)
EA=(IX)+((BR)+A),式子中的括号表示该地址对应的值,无括号则单纯表示地址。
11.堆栈寻址
堆栈是存储器中一块特定的、按后进先出原则管理的存储区,该存储区中读\写单元的地址是用一个特定存储器给出的,该寄存器称为堆栈指针(SP)。寄存器存储堆栈结构又称为硬堆栈,寄存器堆栈成本较高,不适合做大容量堆栈。而从主存中划出一段区域用来做堆栈式最合适的办法,这种堆栈称为软堆栈。软堆栈成本低,但是需要访存,速度更慢。在使用函数调用的时候,使用到了堆栈寻址
在采用堆栈寻址的计算机中,大部分指令看起来是无操作数的,因为操作数地址都是用了堆栈寻址,因为执行一个指令则会从堆栈中取出一个或者多个操作数作为该指令的操作数。
对于硬堆栈来说,进行一次加法的操作如下:
(
M
s
p
)
→
A
C
C
(M_sp)\to ACC
(Msp)→ACC//栈顶元素赋值给ACC
(
S
P
)
+
1
→
S
P
(SP)+1\to SP
(SP)+1→SP//出栈
(
M
s
p
)
→
X
(M_sp)\to X
(Msp)→X//栈顶元素赋值给X
(
S
P
)
+
1
→
X
(SP)+1\to X
(SP)+1→X
(
A
C
C
)
+
(
X
)
→
Y
(ACC)+(X)\to Y
(ACC)+(X)→Y
(
S
P
)
−
1
→
S
P
(SP)-1\to SP
(SP)−1→SP//入栈
(
Y
)
→
M
s
p
(Y)\to M_sp
(Y)→Msp
4.3 CISC和RISC的基本概念
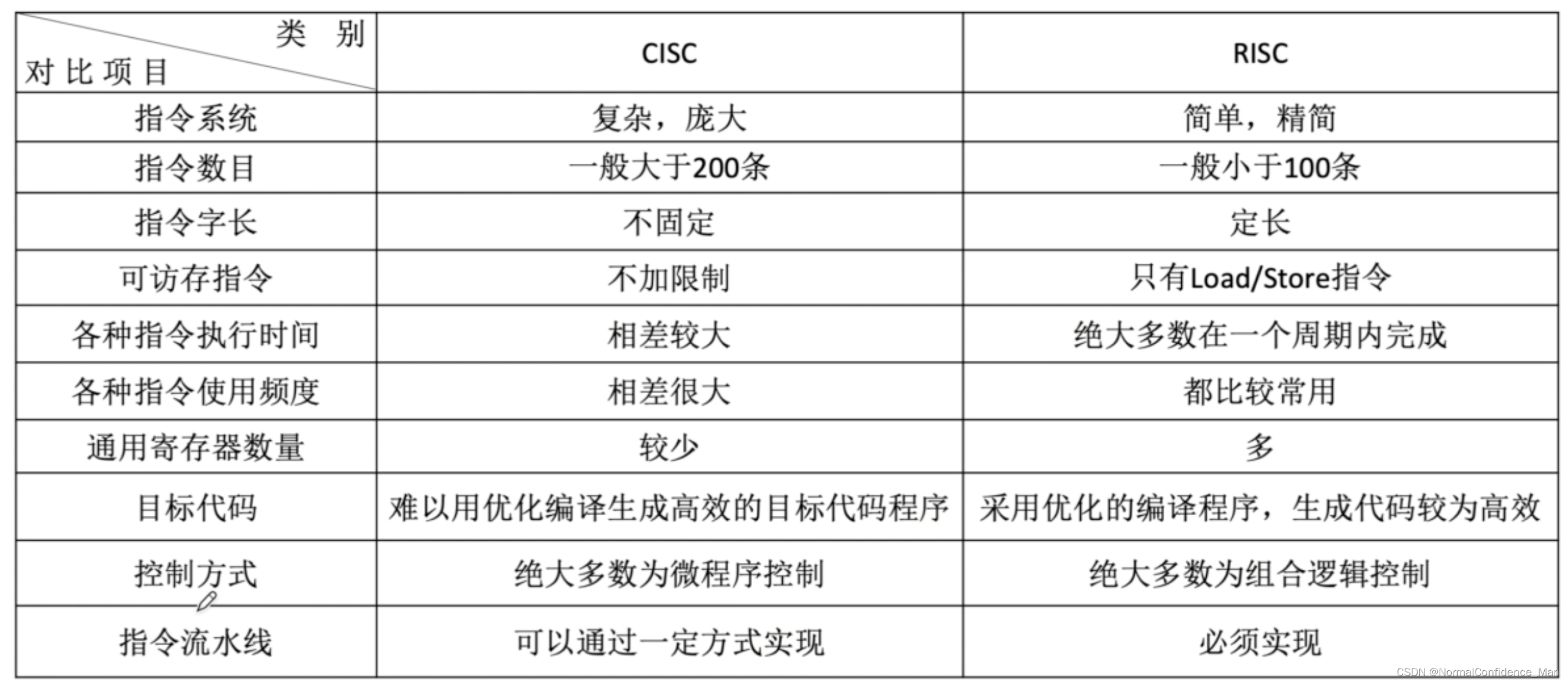
指令系统向着完全不同的两个方向发展:一个是增强原有指令的功能,设置更为复杂的新指令实现软件功能硬件化,这类机器称为复杂指令系统计算机(CISC),典型的是x86架构的计算机,这使得一条指令完成复杂的基本功能;
而RISC减少指令种类简化指令功能,提高指令执行速度,一条指令完成一个基本动作,多条指令组合完成一个复杂的基本功能,电路设计较为简单,功耗低,并且由于指令周期都相近,可以很好的使用流水线技术和并发技术。这类计算机被称为精简指令集系统计算机(RISC)
在CISC中,有些复杂指令使用纯硬件实现非常困难,因此采用了存储程序的设计思想,由一个较为通用的电路配合存储部件完成复杂的指令。
扩展资料:
https://blog.csdn.net/gongxsh00/article/details/81048671
https://zhuanlan.zhihu.com/p/343652303


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









