







决策树
文章目录
参考
基本流程
- 图4.2阅读(可同决策树生成——ID3)
- 机器学习实战版:

划分选择
信息增益
- 信息熵:
- 公式4.1纯度证明:见南瓜书4.1证明(拉格朗日乘数法+二阶导数)OK

 ]
]
- 信息增益(互信息,见南瓜书附注1)
- 条件熵与互信息

- 公式4.2:OK
- 第二项的形式推导(统计学习方法P74 算法5.1)


决策树的生成——ID3,及其问题
- 见统计学习方法P76,算法5.2
- 书中大体意思是:
- 每次计算信息增益,并选取最大者当作当前的节点(划分),但当信息增益小于给定阈值,则不划分(如全yes/no就不分了)
- ID3的问题见:参考链接11
增益率
- 信息增益对数值项目较多的属性有所偏好,故此用编号作为候选划分属性的时候信息增益极大,故此提出增益率的概念
- C4.5决策树法(使用信息增益的这种叫ID3),提出来增益率的概念,公式4.3及4.4 ,
- 下图中的Gain_ratio实际上就是信息增益的信息熵
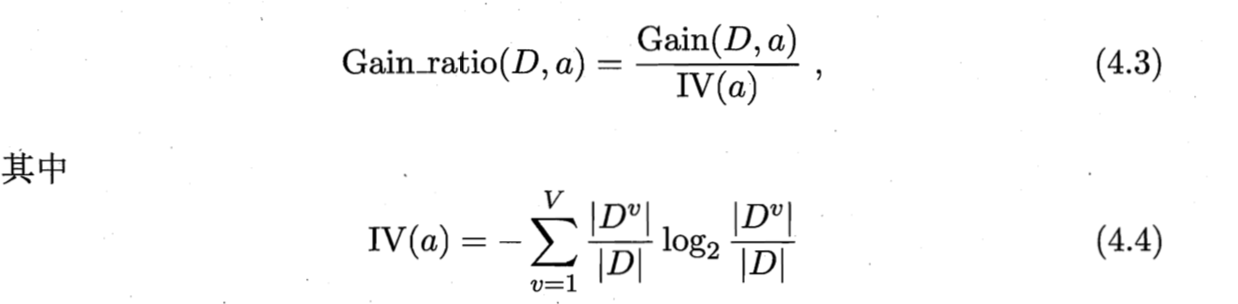
决策树生成 ——C4.5,及其问题
- 见统计学习方法P78,算法5.3
- 具体流程差不多,把比对标准换成增益率
- ID3的问题见:参考链接11
剪枝处理
- 对付过拟合的手段(决策树学习中表现为分支过多,如ID3中编号当作特征的情况),分为预剪枝/后剪枝
- 参考链接:5、6
预剪枝和后剪枝
- 预剪枝这个统计学习方法没有,实际上可以用于C4.5
- 书中采用的是2.2节的性能评估方法
- 预剪枝大致意思是对于某种划分,若划分后的验证集精度大于当前精度,则采用,否则禁止划分(贪心思想,可能导致欠拟合),因为到过拟合之前,可能存在精度先降后升且超过当前值的情况)
- 后剪枝的大致意思其实和预剪枝差不多,对于某棵决策树的某个节点,若剪枝后精度提升则进行剪枝,反之减小以及不变则不剪枝
统计学习方法中的剪枝
- 评价手段
- 统计学习方法P79:5.11-5.14

- 流程:
- 统计学习方法P79 算法5.4
- 计算每个节点的经验熵
- 递归向上回缩(剪掉该节点损失函数更小则剪),直到不能继续为止,得到损失函数最小的子树
CART算法(统计学习方法80)
-
简称:分类与回归树
-
见:参考链接12
-
Gini指数(统计P83,定义5.4;机器P79,4.2.3)
- 可以从下面图中推断出,机器学习中的p‘=(1-p)
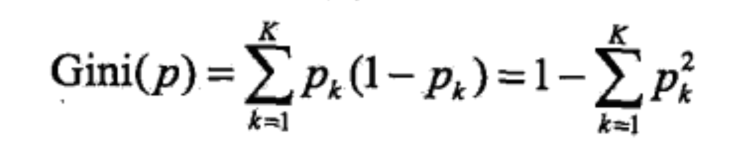
- 对于二分类,可以写成(K=2,且两个式子写出来一样的):
- 对于集合
- 在特征A的条件下,集合D的基尼指数
- 对于5.25,这里指出V必须等于2,因为CART分类输必须是个二叉树
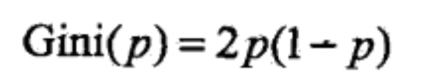



CART回归树
-
首先,我们要明白,什么是回归树,什么是分类树。两者的区别在于样本输出,如果样本输出是离散值,那么这是一颗分类树。如果果样本输出是连续值,那么那么这是一颗回归树。
-
除了概念的不同,CART回归树和CART分类树的建立和预测的区别主要有下面两点:
- 1)连续值的处理方法不同
- 2)决策树建立后做预测的方式不同。
-
对于连续值的处理,我们知道CART分类树采用的是用基尼系数的大小来度量特征的各个划分点的优劣情况。这比较适合分类模型,但是对于回归模型,我们使用了常见的和方差的度量方式,CART回归树的度量目标是,对于任意划分特征A,对应的任意划分点s两边划分成的数据集D1和D2,求出使D1和D2各自集合的均方差最小,同时D1和D2的均方差之和最小所对应的特征和特征值划分点。表达式为:
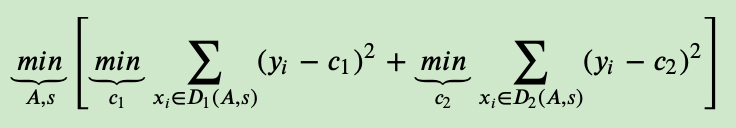
- 其中,c1为D1数据集的样本输出均值,c2为D2数据集的样本输出均值(求和取平均)。
-
回归树的生成:
- 找到一个切分点,使得两边集合方差和最小,重复上述步骤,知道划分为M的区域为止得到决策树
-
CART分类树
- 与上面的生成思想类似(ID3,C4.5),只不过信息增益换成信息率,现在又换成基尼指数
- 另外,南瓜书P23,公式4.6后有CART 决策树生成算法

CART剪枝
- 统计P87,算法5.7

- 可以得到{T1…Tn}个最优子树序列,用交叉验证选最优
- 剪枝算法:


连续与缺失值
连续值处理
- 连续属性的离散化技术,如:二分法
- 公式4.7/4.7,南瓜书
- 参考链接9
缺失值处理
- 参考链接10
多变量决策树
习题
- 4.2:参考链接13















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











