







前言
记录一个工具的使用,AI+爬虫:ScraperGraphAI,简单的配置之后,可以有效地爬取目标地址的信息
代码仓库:https://github.com/ScrapeGraphAI/Scrapegraph-ai
主要代码:scrapegraphai
官方demo地址:https://scrapegraph-ai-web-dashboard.streamlit.app/
一、介绍
1、官方示意图
简单的调用,极致的享受
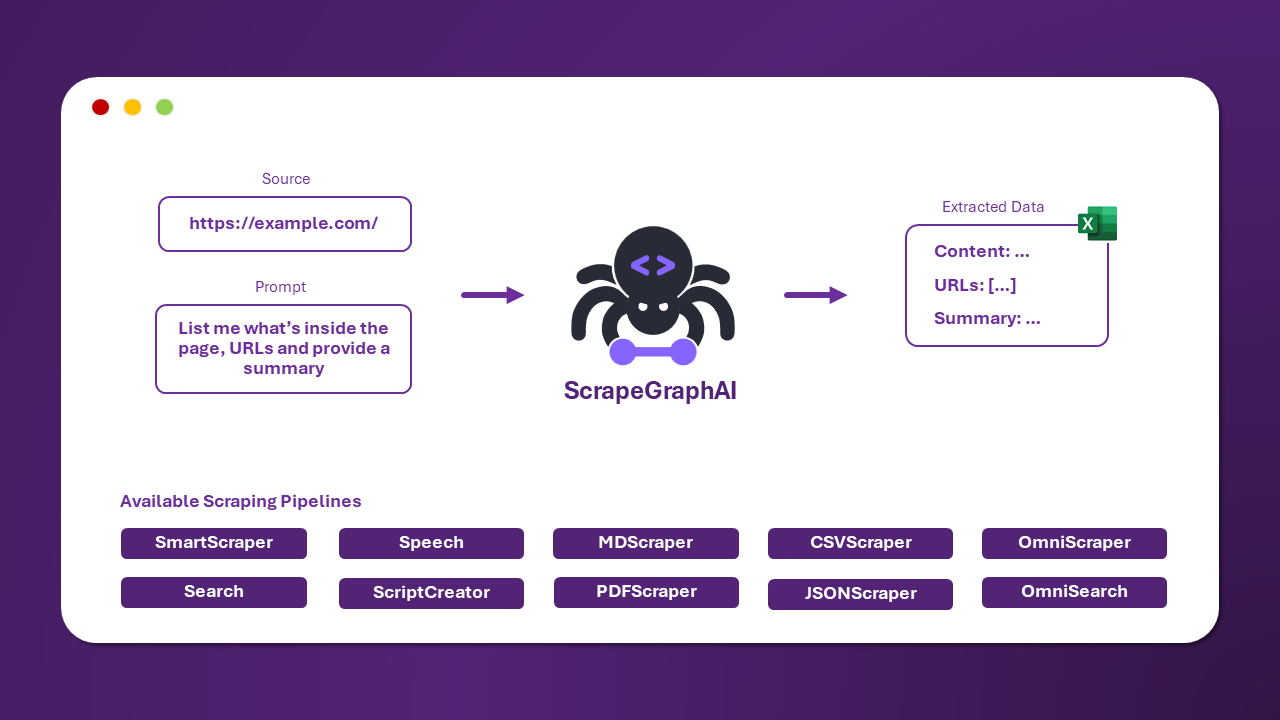
2、运行逻辑

支持本地模型与线上模型,SmartScraperGraph是一个代表一个默认抓取管道的类。它使用直接的图形实现,其中每个节点都有自己的功能,从从网站检索html到根据查询提取相关信息并生成连贯的答案。
3、官方示例
安装
pip install scrapegraphai
playwright install
简单爬取一个页面
from scrapegraphai.graphs import SmartScraperGraph
OPENAI_API_KEY = "YOUR API KEY"
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "gpt-3.5-turbo",
},
"verbose": True,
"headless": True,
}
# ************************************************
# Create the SmartScraperGraph instance and run it
# ************************************************
smart_scraper_graph = SmartScraperGraph(
prompt="List me all the projects with their description",
# also accepts a string with the already downloaded HTML code
source="https://perinim.github.io/projects/",
config=graph_config,
)
result = smart_scraper_graph.run()
output = json.dumps(result, indent=2)
line_list = output.split("\n") # Sort of line replacing "\n" with a new line
for line in line_list:
print(line)
输入搜索内容,查询线上内容

from scrapegraphai.graphs import SearchGraph
# Define the configuration for the graph
graph_config = {
"llm": {
"api_key": '',
"model": "gpt-3.5-turbo",
"temperature": 0,
},
}
# Create the SearchGraph instance
search_graph = SearchGraph(
prompt="List me all the European countries.",
config=graph_config
)
result = search_graph.run()
print(result)
#输出: {'European_countries': ['Austria', 'Belgium', 'Bulgaria', 'Croatia', 'Republic of Cyprus', 'Czech Republic', 'Denmark', 'Estonia', 'Finland', 'France', 'Germany', 'Greece', 'Hungary', 'Ireland', 'Italy', 'Latvia', 'Lithuania', 'Luxembourg', 'Malta', 'Netherlands', 'Poland', 'Portugal', 'Romania', 'Slovakia', 'Slovenia', 'Spain', 'Sweden', 'Russia', 'United Kingdom', 'Ukraine', 'Belarus', 'Switzerland', 'Serbia', 'Norway', 'Moldova', 'Bosnia and Herzegovina', 'Albania', 'North Macedonia', 'Montenegro', 'Iceland', 'Andorra', 'Liechtenstein', 'Monaco', 'San Marino', 'Holy See']}
生成音频内容

from scrapegraphai.graphs import SpeechGraph
# Define the configuration for the graph
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "gpt-3.5-turbo",
},
"tts_model": {
"api_key": OPENAI_API_KEY,
"model": "tts-1",
"voice": "alloy"
},
"output_path": "website_summary.mp3",
}
# Create the SpeechGraph instance
speech_graph = SpeechGraph(
prompt="Create a summary of the website",
source="https://perinim.github.io/projects/",
config=graph_config,
)
result = speech_graph.run()
answer = result.get("answer", "No answer found")
output = json.dumps(answer, indent=2)
line_list = output.split("\n") # Sort of line replacing "\n" with a new line
for line in line_list:
print(line)
from IPython.display import Audio
wn = Audio("website_summary.mp3", autoplay=True)
display(wn)
客制化查询graph
依照官方文档,如果要克制化自己的graph,需要按需实现节点类,即*Node,并且保证其可用
基础graph有上方介绍的三个graph
基础节点类:FetchNode, ParseNode, RAGNode, GenerateAnswerNode
根据节点类的名称就可以看出他们的具体分工,从指定数据源抓取信息、解析信息、生成自然语言回答、生成任务获取答案
示例代码:
from langchain_openai import OpenAIEmbeddings
from scrapegraphai.models import OpenAI
from scrapegraphai.graphs import BaseGraph
from scrapegraphai.nodes import FetchNode, ParseNode, RAGNode, GenerateAnswerNode
# Define the configuration for the graph
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "gpt-3.5-turbo",
"temperature": 0,
"streaming": True
},
}
llm_model = OpenAI(graph_config["llm"])
embedder = OpenAIEmbeddings(api_key=llm_model.openai_api_key)
# define the nodes for the graph
fetch_node = FetchNode(
input="url | local_dir",
output=["doc", "link_urls", "img_urls"],
node_config={
"verbose": True,
"headless": True,
}
)
parse_node = ParseNode(
input="doc",
output=["parsed_doc"],
node_config={
"chunk_size": 4096,
"verbose": True,
}
)
rag_node = RAGNode(
input="user_prompt & (parsed_doc | doc)",
output=["relevant_chunks"],
node_config={
"llm_model": llm_model,
"embedder_model": embedder,
"verbose": True,
}
)
generate_answer_node = GenerateAnswerNode(
input="user_prompt & (relevant_chunks | parsed_doc | doc)",
output=["answer"],
node_config={
"llm_model": llm_model,
"verbose": True,
}
)
# create the graph by defining the nodes and their connections
graph = BaseGraph(
nodes=[
fetch_node,
parse_node,
rag_node,
generate_answer_node,
],
edges=[
(fetch_node, parse_node),
(parse_node, rag_node),
(rag_node, generate_answer_node)
],
entry_point=fetch_node
)
以娇简单的graph:SmartScraperGraph为例
SmartScraperGraph继承官方基础类AbstractGraph
内部重写了方法 self._create_graph(),具体的设置代码可以参考这里scrapergraphai/graphs/smart_scrper_graph.py
def _create_graph(self) -> BaseGraph:
"""
Creates the graph of nodes representing the workflow for web scraping.
Returns:
BaseGraph: A graph instance representing the web scraping workflow.
"""
fetch_node = FetchNode(
input="url| local_dir",
output=["doc", "link_urls", "img_urls"],
node_config={
"llm_model": self.llm_model,
"force": self.config.get("force", False),
"cut": self.config.get("cut", True),
"loader_kwargs": self.config.get("loader_kwargs", {}),
}
)
parse_node = ParseNode(
input="doc",
output=["parsed_doc"],
node_config={
"chunk_size": self.model_token
}
)
generate_answer_node = GenerateAnswerNode(
input="user_prompt & (relevant_chunks | parsed_doc | doc)",
output=["answer"],
node_config={
"llm_model": self.llm_model,
"additional_info": self.config.get("additional_info"),
"schema": self.schema,
}
)
return BaseGraph(
nodes=[
fetch_node,
parse_node,
generate_answer_node,
],
edges=[
(fetch_node, parse_node),
(parse_node, generate_answer_node)
],
entry_point=fetch_node,
graph_name=self.__class__.__name__
)
二、实际使用
1.使用背景
老大:我这里有个网站,我们也找了个框架AutoCrawler,你去看看这个框架能不能实现AI爬虫,不行的话就换一个
我:好的,我先研究一下这个框架
研究半天发现,这是个科研模型,写论文用的。在开源仓库里翻滚了几圈,发现源代码缺失了还。。。。
我:老大,这个框架用不了,文件少了好多,我又另找了一个,你瞅瞅。
老大:好,就用你找的这个
2.具体代码
使用的LLM:open AI
代码如下(示例):
@app.route('/api/v0/get_content', methods=['GET'])
def get_content():
question = flask.request.args.get('question')
source = flask.request.args.get('source')
data = test(source, question)
return json.dumps(data, indent=2)
def test(source, question):
graph_config = {
"llm": {
"api_key": "",
"model": "gpt-3.5-turbo"
},
"verbose": True,
"headless": False
}
smart_scraper_graph = MySmartScraperGraph(
prompt=question,
source=source,
config=graph_config
)
result = smart_scraper_graph.run()
return result
介绍
从上面可以看到,我写了个示例,其中的graph我敲了一个MySmartScraperGraph,原因是需求要爬取的网站是一个加载超级缓慢的网站,在代码包里面的FetchNode中,他的加载逻辑是使用Playwright导航至指定URL,并等待直至页面DOM内容加载完成,但不包括如图片、样式表等其他资源的加载。虽然这通常比等待整个页面加载更快,但是遇到这种加载慢的网站根本抓不出来所有有用的页面信息,辛亏我不需要考虑速度,我只需要考虑内容。
这(FetchNode)其中,加载页面的部分是
loader = ChromiumLoader([source], headless=self.headless, **loader_kwargs)
document = loader.load()
async def ascrape_playwright(self, url: str) -> str:
"""
Asynchronously scrape the content of a given URL using Playwright's async API.
Args:
url (str): The URL to scrape.
Returns:
str: The scraped HTML content or an error message if an exception occurs.
"""
from playwright.async_api import async_playwright
from undetected_playwright import Malenia
logger.info("Starting scraping...")
results = ""
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=self.headless, proxy=self.proxy, **self.browser_config
)
try:
context = await browser.new_context()
await Malenia.apply_stealth(context)
page = await context.new_page()
await page.goto(url, wait_until="domcontentloaded") # 就是这里的设置
await page.wait_for_load_state(self.load_state)
results = await page.content() # Simply get the HTML content
logger.info("Content scraped")
except Exception as e:
results = f"Error: {e}"
await browser.close()
return results
我的做法是,改写这部分的逻辑,将其设置改为
await page.goto(url, wait_until="load")
后来发现也无法加载完毕,索性直接让其sleep了5s
新增:哈哈哈哈哈,我个呆子,人家有等待方法
await page.wait_for_timeout(20000)
所以我只能一路继承重写(也不是只能,实际上是我只想到了这一个方法)
先是重定义ascrape_playwright,也就是ChromiumLoader
# -*- coding: utf-8 -*-
"""
Custom ChromiumLoader Module
"""
import asyncio
from typing import Iterator
from langchain_core.documents import Document
from scrapegraphai.utils import get_logger
from scrapegraphai.docloaders.chromium import ChromiumLoader
logger = get_logger("web-loader")
class MyChromiumLoader(ChromiumLoader):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
async def ascrape_playwright(self, url: str) -> str:
from playwright.async_api import async_playwright
from undetected_playwright import Malenia
print("Starting scraping...")
results = ""
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=self.headless, proxy=self.proxy, **self.browser_config
)
try:
context = await browser.new_context()
await Malenia.apply_stealth(context)
page = await context.new_page()
# --------------------update-----------------------------
await page.goto(url, wait_until="load")
# --------------------update-----------------------------
await page.wait_for_load_state(self.load_state)
# time.sleep(5)
await page.wait_for_timeout(5000) # 毫秒级:等待5秒
# --------------------update-----------------------------
results = await page.content() # Simply get the HTML content
print("Content scraped")
except Exception as e:
results = f"Error: {e}"
await browser.close()
return results
def lazy_load(self) -> Iterator[Document]:
scraping_fn = getattr(self, f"ascrape_{self.backend}")
for url in self.urls:
fun_ = scraping_fn(url)
html_content = asyncio.run(fun_)
metadata = {"source": url}
yield Document(page_content=html_content, metadata=metadata)
然后重写继承使用它的节点类 FetchNode
# -*- coding: utf-8 -*-
""""
Custom FetchNode Module
"""
import json
import pandas as pd
import requests
from langchain_community.document_loaders import PyPDFLoader
from langchain_core.documents import Document
from scrapegraphai.nodes import FetchNode
from scrapegraphai.utils.cleanup_html import cleanup_html
from scrapegraphai.utils.convert_to_md import convert_to_md
from custom_class.chromium import MyChromiumLoader
class MyFetchNode(FetchNode):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def execute(self, state):
**********
else:
self.logger.info(f"--- (Fetching HTML from: {source}) ---")
loader_kwargs = {}
if self.node_config is not None:
loader_kwargs = self.node_config.get("loader_kwargs", {})
# ------------------------------------------MyChromiumLoader------------------------------------------------------
loader = MyChromiumLoader([source], headless=self.headless, **loader_kwargs)
document = loader.load()
# ------------------------------------------MyChromiumLoader------------------------------------------------------
if not document or not document[0].page_content.strip():
raise ValueError("No HTML body content found in the document fetched by ChromiumLoader.")
parsed_content = document[0].page_content
if (not self.script_creator) or (self.force and not self.script_creator and not self.openai_md_enabled):
parsed_content = convert_to_md(document[0].page_content, source)
compressed_document = [
Document(page_content=parsed_content, metadata={"source": "html file"})
]
state.update(
{
self.output[0]: compressed_document,
}
)
return state
然后是牵扯使用FetchNode的BaseGraph
# -*- coding: utf-8 -*-
"""
Custom BaseGraph Module
"""
import time
from langchain_community.callbacks import get_openai_callback
from typing import Tuple
from scrapegraphai.graphs import BaseGraph
from scrapegraphai.telemetry import log_graph_execution
class MyBaseGraph(BaseGraph):
def __init__(self, nodes: list, edges: list, entry_point: str, use_burr: bool = False, burr_config: dict = None,
graph_name: str = "Custom"):
super().__init__(nodes, edges, entry_point, use_burr, burr_config, graph_name)
def _execute_standard(self, initial_state: dict) -> Tuple[dict, list]:
current_node_name = self.entry_point
state = initial_state
total_exec_time = 0.0
exec_info = []
cb_total = {
"total_tokens": 0,
"prompt_tokens": 0,
"completion_tokens": 0,
"successful_requests": 0,
"total_cost_USD": 0.0,
}
start_time = time.time()
error_node = None
source_type = None
llm_model = None
embedder_model = None
source = []
prompt = None
schema = None
while current_node_name:
curr_time = time.time()
current_node = next(node for node in self.nodes if node.node_name == current_node_name)
# check if there is a "source" key in the node config
# ------------------------------update----------------------------
if current_node.__class__.__name__ in ["FetchNode", "MyFetchNode"]:
# ------------------------------update----------------------------
# get the second key name of the state dictionary
source_type = list(state.keys())[1]
if state.get("user_prompt", None):
prompt = state["user_prompt"] if type(state["user_prompt"]) == str else None
# quick fix for local_dir source type
if source_type == "local_dir":
source_type = "html_dir"
elif source_type == "url":
if type(state[source_type]) == list:
# iterate through the list of urls and see if they are strings
for url in state[source_type]:
if type(url) == str:
source.append(url)
elif type(state[source_type]) == str:
source.append(state[source_type])
******
最后就是SmartScraperGraph
class MySmartScraperGraph(SmartScraperGraph):
def __init__(self, prompt: str, source: str, config: dict, schema: Optional[BaseModel] = None):
super().__init__(prompt, source, config, schema)
def _create_graph(self) -> MyBaseGraph:
fetch_node = MyFetchNode(
input="url| local_dir",
output=["doc", "link_urls", "img_urls"],
node_config={
"llm_model": self.llm_model,
"force": self.config.get("force", False),
"cut": self.config.get("cut", True),
"loader_kwargs": self.config.get("loader_kwargs", {}),
}
)
parse_node = ParseNode(
input="doc",
output=["parsed_doc"],
node_config={
"chunk_size": self.model_token
}
)
generate_answer_node = GenerateAnswerNode(
input="user_prompt & (relevant_chunks | parsed_doc | doc)",
output=["answer"],
node_config={
"llm_model": self.llm_model,
"additional_info": self.config.get("additional_info"),
"schema": self.schema,
}
)
return MyBaseGraph(
nodes=[
fetch_node,
parse_node,
generate_answer_node,
],
edges=[
(fetch_node, parse_node),
(parse_node, generate_answer_node)
],
entry_point=fetch_node,
graph_name=self.__class__.__name__
)
最后就是一开始的调用了
总结
这只是对SmartScraperGraphAi的一个基础功能的简单使用记录,还有很多其他的功能,比如多页面的信息抓取,这个得慢慢看了,但是我现在实现了这个需求,我先摸一会。
日常想念女朋友















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









