






Task03:EM算法(2天)
理论部分
- 相关概念
- 极大似然估计法
- 贝叶斯估计方法
- EM基本原理
- E步
- M步
- 推导、证明
- 高斯混合分布
练习部分
- 算法实现
EM算法是机器学习十大算法之一,它很简单,但是也同样很有深度,简单是因为它就分两步求解问题,
E步:求期望(expectation)
M步:求极大(maximization)
假设我们有一个样本集{x(1),…,x(m)},包含m个独立的样本。但每个样本i对应的类别z(i)是未知的(相当于聚类),也即隐含变量。故我们需要估计概率模型p(x,z)的参数θ,但是由于里面包含隐含变量z,所以很难用最大似然求解,但如果z知道了,那我们就很容易求解了。
对于参数估计,我们本质上还是想获得一个使似然函数最大化的那个参数θ,现在与最大似然不同的只是似然函数式中多了一个未知的变量z,见下式(1)。也就是说我们的目标是找到适合的θ和z让L(θ)最大。那我们也许会想,你就是多了一个未知的变量而已啊,我也可以分别对未知的θ和z分别求偏导,再令其等于0,求解出来不也一样吗?

本质上我们是需要最大化(1)式(对(1)式,我们回忆下联合概率密度下某个变量的边缘概率密度函数的求解,注意这里z也是随机变量。对每一个样本i的所有可能类别z求等式右边的联合概率密度函数和,也就得到等式左边为随机变量x的边缘概率密度),也就是似然函数,但是可以看到里面有“和的对数”,求导后形式会非常复杂(自己可以想象下log(f1(x)+ f2(x)+ f3(x)+…)复合函数的求导),所以很难求解得到未知参数z和θ。那OK,我们可否对(1)式做一些改变呢?我们看(2)式,(2)式只是分子分母同乘以一个相等的函数,还是有“和的对数”啊,还是求解不了,那为什么要这么做呢?咱们先不管,看(3)式,发现(3)式变成了“对数的和”,那这样求导就容易了。我们注意点,还发现等号变成了不等号,为什么能这么变呢?这就是Jensen不等式的大显神威的地方。
->此处省略jensen不等式的介绍
EM算法(Expectation-maximization):
期望最大算法是一种从不完全数据或有数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。
EM的算法流程:
初始化分布参数θ;
重复以下步骤直到收敛:
E步骤:根据参数初始值或上一次迭代的模型参数来计算出隐性变量的后验概率,其实就是隐性变量的期望。作为隐藏变量的现估计值:
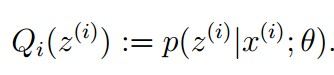
M步骤:将似然函数最大化以获得新的参数值:
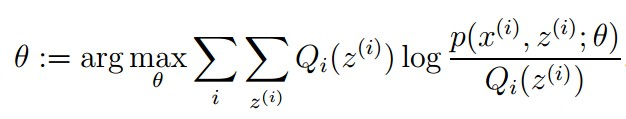
这个不断的迭代,就可以得到使似然函数L(θ)最大化的参数θ了。那就得回答刚才的第二个问题了,它会收敛吗。
感性的说,因为下界不断提高,所以极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。理性分析的话,就会得到下面的东西:

主要参考博客:
原文链接:https://blog.csdn.net/zouxy09/article/details/8537620















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









