







内容参考 公众号“ 源知源为”大佬相关文章总结,自用,链接地址
https://mp.weixin.qq.com/mp/appmsgalbum?__biz=Mzg4ODcxMjIyMA==&action=getalbum&album_id=2859226288341925891&scene=173&from_msgid=2247484174&from_itemidx=1&count=3&nolastread=1#wechat_redirect
C++中的互斥锁
std::mutex (C++11)
std::mutex 是普通的互斥锁,提供三个简单的接口:lock/try_lock/unlock。try_lock() 如果成功获取锁,返回 true,否则返回 flase,不会阻塞地等待。std::mutex 不支持拷贝和移动,并且不支持递归使用。在 Linux 系统下,是对系统 pthread_mutex_t 简单的封装。__gthread_mutex_lock/try_lock/unlock 直接调用 pthread_mutex_lock/try_lock/unlock,没有其他特殊的操作。
std::timed_mutex (c++11)
std::timed_mutex 虽然实现上和 std::mutex 没有关系,但是功能上是对 std::mutex 的拓展,新增 try_lock_for/try_lock_until 两个接口,支持在 lock 时设置 timeout 参数。和 std::mutex 一样,std::timed_mutex 不支持递归使用。
-
try_lock_for 接受一段时间,表示距离超时的间隔
-
try_lock_until 接受一个时间点,表示超时时间
timed_mutex 继承于 __mutex_base 和 __timed_mutex_impl。
std::recursive_mutex (C++11)
std::recursive_mutex 接口和 std::mutex 完全一致,但是调用的系统函数完全不同,因为 std::recursive_mutex 支持递归调用:当调用 lock/try_lock 获取锁后,可以继续调用 lock/try_lock 而不会导致死锁。
std::recursive_mutex 的实现和 std::mutex 类似,首先 __recursive_mutex_base 封装一个 pthread_mutex_t 数据结构(Linux 平台)然后 recursive_mutex 继承 __recursive_mutex_base 类,实现 lock/unlock 接口。使用 recursive_mutex 的地方,可以进行拆解,提供 *_unlock 版本的函数,进而使用 mutex。
std::recursive_timed_mutex(C++11)
std::recursive_timed_mutex 和 std::timed_mutex 实现原理相同,接口也相同:try_lock_for/try_lock_until() 函数可以指定超时时间,不用死等。和 std::timed_mutex 不同的是 std::recursive_timed_mutex 支持递归调用。
std::shared_mutex (C++17)
C++17 提供 std::shared_mutex, 具有两种接口:
-
shared:多个线程可以获取锁
-
exclusive:只能单个线程获取锁
如果一个线程通过 lock/try_lock 获取到了锁,其他线程就不能获取到锁,包括 shared,通常用在读多写少的场景。
在 Linux 平台,默认情况下 (_GLIBCXX_USE_PTHREAD_RWLOCK_T 定义),借助 __shared_mutex_pthread 实现,否则是借助 __shared_mutex_cv 实现。__shared_mutex_pthread 其实就是封装了读写锁 pthread_rwlock_t。
如果不使用 pthread_rwlock_t,C++ 使用的是 __shared_mutex_cv,用 std::mutex 和两个 std::condition_variable 实现。
std::shared_timed_mutex (C++14)
std::shared_timed_mutex 和 std::timed_mutex 相同,lock 时可以设置超时时间。
mutex 辅助类 lock
为了方便使用互斥锁,C++ 标准库提供一系列辅助类。默认情况是构造函数中自动获取 mutex,析构函数中释放锁。另外,为了方便管理互斥锁,定义了三个辅助标志
-
defer_lock_t:不调用 lock
-
try_to_lock_t:调用 try_lock,不阻塞当前线程
-
adopt_lock_t:不调用 lock,认为已经获取锁
std::lock_guard (C++11)
std::lock_guard 封装了一个 mutex,使用 ARII 机制,在构造函数中对 mutex 加锁,在析构函数中释放锁。可以避免出现函数返回,但是忘记释放锁的问题。
std::unique_lock (C++11)
std::unique_lock 是一个比较通用的 mutex 管理类,其实是封装了一个 Mutex,新增加了一个功能:如果获取到锁,析构函数自动释放锁。其他接口都是 Mutex 具有的接口。
std::unique_lock 另外的一个作用是,和 std::condition_variable 结合使用。
std::unique_lock 具有两个成员变量:M_device 和 M_owns。M_device 是一个指针,指向 user 指定的 Mutex 对象,M_owns 是一个 bool 类型变量,表示当前 std::unique_lock 是否获取锁。
std::shared_lock (C++14)
std::shared_lock 和 std::unique_lock 功能相似,如果对应到 std::shared_mutex,则 std::shared_lock 管理 shared 接口,而 unique_lock 管理的是 exclusive 的接口。
std::scoped_lock (C++17)
std::scoped_lock 其实是 std::lock_guard 的拓展:std::lock_guard 只能管理单个 Mutex,而 std::scoped_lock 可以管理多个 Mutex。std::scoped_lock 可以避免死锁:按照相同的顺序 lock 和 unlock。
如果只有一个 Mutex,std::scoped_lock 和 std::lock_guard 就完全相同。
条件变量 condition_variable
std::condition_variable
std::condition_variable 是结合 std::mutex 使用的同步语句,可以阻塞和唤醒一个或者多个修改共享数据的线程。
比如下面的例子,worker 线程一直阻塞,直到 main() 函数填充数据并唤醒 worker 线程。main() 然后等待 worker 线程处理数据。
#include <condition_variable>
#include <iostream>
#include <mutex>
#include <string>
#include <thread>
std::mutex m;
std::condition_variable cv;
std::string data;
bool ready = false;
bool processed = false;
void worker_thread() {
// Wait until main() sends data
std::unique_lock lk(m);
cv.wait(lk, [] { return ready; });
// after the wait, we own the lock.
std::cout << "Worker thread is processing data\n";
data += " after processing";
// Send data back to main()
processed = true;
std::cout << "Worker thread signals data processing completed\n";
// Manual unlocking is done before notifying, to avoid waking up
// the waiting thread only to block again (see notify_one for details)
lk.unlock();
cv.notify_one();
}
int main() {
std::thread worker(worker_thread);
data = "Example data";
// send data to the worker thread
{
std::lock_guard lk(m);
ready = true;
std::cout << "main() signals data ready for processing\n";
}
cv.notify_one();
// wait for the worker
{
std::unique_lock lk(m);
cv.wait(lk, [] { return processed; });
}
std::cout << "Back in main(), data = " << data << '\n';
worker.join();
}
std::condition_variable_any
std::condition_variable_any 是 std::condition_variable 的泛化版本。
std::condition_variable 只能结合 std::unique_lockstd::mutex 使用,而 std::condition_variable_any 可以和任何互斥锁配合使用,即使它不是标准库提供的互斥锁,只要提供 lock/unlock 结构即可。
比如可以结合 std::recursive_mutex 使用。
#include <condition_variable>
#include <iostream>
#include <mutex>
#include <thread>
// This mutex is used for three purposes:
// 1) to synchronize accesses to i
// 2) to synchronize accesses to std::cerr
// 3) for the condition variable cv
std::recursive_mutex cv_m;
std::condition_variable_any cv;
int i = 0;
void waits() {
std::unique_lock<std::recursive_mutex> lk(cv_m);
std::cerr << "Waiting... \n";
cv.wait(lk, [] { return i == 1; });
std::cerr << "...finished waiting. i == 1\n";
}
void signals() {
std::this_thread::sleep_for(std::chrono::seconds(1));
{
std::lock_guard<std::recursive_mutex> lk(cv_m);
std::cerr << "Notifying...\n";
}
cv.notify_all();
std::this_thread::sleep_for(std::chrono::seconds(1));
{
std::lock_guard<std::recursive_mutex> lk(cv_m);
i = 1;
std::cerr << "Notifying again...\n";
}
cv.notify_all();
}
int main() {
std::thread t1(waits), t2(waits), t3(waits), t4(signals);
t1.join();
t2.join();
t3.join();
t4.join();
}
std::call_once() (C++11)
std::call_once() 函数保证 f 只会被调用一次,即使在多线程环境也是如此。
template< class Callable, class... Args >
void call_once( std::once_flag& flag, Callable&& f, Args&&... args );
#include <iostream>
#include <mutex>
#include <thread>
std::once_flag flag1;
void simple_do_once() {
std::call_once(flag1, []() {
std::cout << "Simple example: called once\n"; });
}
int main() {
std::thread st1(simple_do_once);
std::thread st2(simple_do_once);
std::thread st3(simple_do_once);
std::thread st4(simple_do_once);
st1.join();
st2.join();
st3.join();
st4.join();
}
只会有一句打印
Simple example: called once
std::call_once() 有一个 BUG,会一直阻塞调用线程。按照官方说法,如果抛出异常,后续调用可以继续执行。
原子模式 atomic
std::atomic 采用 GCC built-in 函数(函数名带前缀 _atomic)实现,没有暴露太多底层的细节
具体参考大佬文章 C++11 内存一致性模型(Memory Consistency Model)
1、多核多线程程序的问题
1.1、乱序
1.2、双重检查锁单例真的线程安全吗?
2、memory location
3、CPU 架构内存模型
3.1、SC(Sequential Consistency) 一致性
3.2、TSO(Total Store Ordering) 一致性
3.3、弱内存一致性模型(Relaxed/Weak Memory Consistency Model)
3.4、Intel & ARM 内存模型
3.4.1、Intel 内存模型
3.4.2、ARM64 内存模型
4、std::memory_order
4.1、relaxed ordering
4.2、acquire-release ordering
4.3、sequentially constisent ordering
5、LevelDB 跳表 SkipList 内存序分析
__atomic_base
__atomic_base 用于实现整数类型(占用内存 1/2/4/8 个字节)的原子变量。
-
不能赋值
-
默认使用 memory_order_seq_cst
-
使用 built-in 函数实现
std::atomic
如果是数值类型,比如 char/int/long 这样的,无符号和有符号都是,直接继承 __atomic_base。
如果模板参数不是整型,会使用 atomic 的普通定义
如果是其他类型的指针,借助 __atmoic_base 实现。
atomic_thread_fence
如果是非 atomic 类型数据,或者是 memory_order_relaxed 类型的 atomic 操作,可以使用 atomic_thread_fence 来建立多线程之间的同步,也就是 release-acquire 相同的作用。比如
const int num_mailboxes = 32;
std::atomic<int> mailbox_receiver[num_mailboxes];
std::string mailbox_data[num_mailboxes];
// The writer threads update non-atomic shared data
// and then update mailbox_receiver[i] as follows
mailbox_data[i] = ...;
std::atomic_store_explicit(&mailbox_receiver[i], receiver_id,
std::memory_order_release);
// Reader thread needs to check all mailbox[i], but only needs to sync with one
for (int i = 0; i < num_mailboxes; ++i) {
if (std::atomic_load_explicit(&mailbox_receiver[i],
std::memory_order_relaxed) == my_id) {
// synchronize with just one writer
std::atomic_thread_fence(std::memory_order_acquire);
// guaranteed to observe everything done in the writer thread before
// the atomic_store_explicit()
do_work( mailbox_data[i] );
}
}
异步编程future
std::future 封装了一个异步执行的结果,如果异步执行还未完成,std::future 将阻塞直到异步执行完成并且将结果传递给 std::future。
例如下面的例子,std::async() 函数将创建线程异步执行一个任务,返回一个 std::future 类型对象 f1,调用 f1.wait() 后主线程被阻塞,直到异步任务执行完成。
#include <chrono>
#include <future>
#include <iostream>
#include <thread>
int main() {
std::future<int> f1 = std::async(std::launch::async, [] {
for (int i = 0; i < 5; ++i) {
std::this_thread::sleep_for(std::chrono::milliseconds(500));
std::cout << std::this_thread::get_id() << " async sleep ...\n";
}
std::cout << std::this_thread::get_id() << " async return\n";
return 8;
});
std::cout << std::this_thread::get_id() << " Waiting...\n";
f1.wait();
std::cout << std::this_thread::get_id() << " Done! Results are: " << f1.get()
<< std::endl;
}
async 执行结束返回后,f1.wait() 才返回,然后 f1.get() 可以读到 async 异步执行的结果。
future_status :
-
ready 表示已经就绪
-
timeout:wait_for() 或者 wait_until() 超时时返回
-
deferred:表示异步任务时 deferred 类型的
enum class future_status
{
ready,
timeout,
deferred
};
std::future 的实现主要依靠两个类:__future_base::_Result 和 __future_base::_State_base。_Result 封装了异步执行的结果,而 _State_base 是一个基类,代表了一个异步任务状态。接下来就逐一分析这两个类。
__future_base::_Result
_Result 是 __future_base 类内类,继承 __future_base::_Result_base。_M_destroy() 纯虚函数需要继承类实现,用于销毁资源。
_Deleter 类是当作 std::unique_ptr 的资源销毁类,在 unique_ptr 释放资源时,_Deleter 将被调用。
__future_base::_State_base
首先,_State_base 就是 _State_baseV2 的别名。_State_baseV2 具有四个成员变量:
-
_M_result:记录结果
-
_M_status:标记状态 read/not_ready
-
_M_retrieved:标记是否绑定到 future
-
_M_once:call_once 标志
_State_baseV2 是不能被拷贝的,_M_status 在初始化时是 not_ready 状态。_M_result 在 _M_do_set() 函数中被赋值。
std::future
__future_base 只定义了两个接口:_S_allocate_result() 和 _S_task_setter(),而且都是 static 函数。_S_allocate_result() 函数用于申请一个 Result 对象。
_S_task_setter() 函数用于构造一个 _Task_setter 对象。_Task_setter 对象的作用是给 Result 对象赋值:调用 call,将返回的结果赋值给 Result。
__basic_future
__basic_future 拥有一个 State_base 对象,定义了 future 的接口 valid() 和 wait()。wait 相关的函数都是调用 State_base 的接口。
在构造函数中调用 _M_set_retrieved_flag() 函数标记 State 已经绑定到 future 上。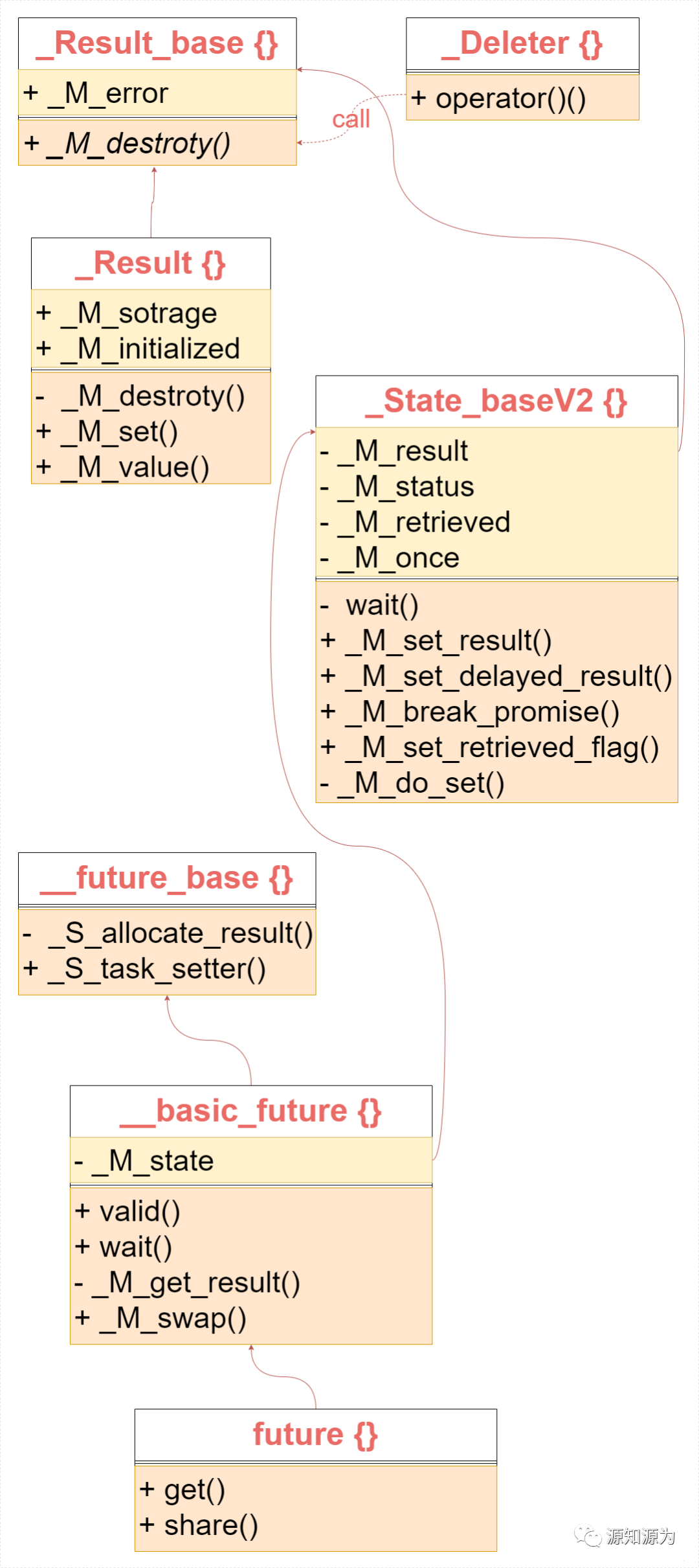
std::shared_future
std::shared_future 和 std::future 基本相同,唯一的差别是 shared_future 可以在多个线程调用,因为 get() 函数没有使用 std::move() 返回结果。shared_future::get() 函数返回的是 Res 引用。
std::promise
使用 std::promise 可以很方便地实现:std::promise 创建一个 std::future 对象,可以异步获取 promise::set_value() 保存的值。当然,set_value() 函数也可以不传入任何值,当作 promise 对 future 发送通知。
比如下面的例子,promise 创建一个 future 后,后台开始计算,然后将结果传递给 future。
#include <chrono>
#include <future>
#include <iostream>
#include <numeric>
#include <thread>
#include <vector>
void accumulate(std::vector<int>::iterator first,
std::vector<int>::iterator last,
std::promise<int> accumulate_promise) {
int sum = std::accumulate(first, last, 0);
accumulate_promise.set_value(sum); // Notify future
}
void do_work(std::promise<void> barrier) {
std::this_thread::sleep_for(std::chrono::seconds(1));
barrier.set_value();
}
int main() {
// Demonstrate using promise<int> to transmit a result between threads.
std::vector<int> numbers = {1, 2, 3, 4, 5, 6};
std::promise<int> accumulate_promise;
std::future<int> accumulate_future = accumulate_promise.get_future();
std::thread work_thread(accumulate, numbers.begin(), numbers.end(),
std::move(accumulate_promise));
// future::get() will wait until the future has a valid result and retrieves
// it. Calling wait() before get() is not needed
// accumulate_future.wait(); // wait for result
std::cout << "result=" << accumulate_future.get() << '\n';
work_thread.join(); // wait for thread completion
// Demonstrate using promise<void> to signal state between threads.
std::promise<void> barrier;
std::future<void> barrier_future = barrier.get_future();
std::thread new_work_thread(do_work, std::move(barrier));
barrier_future.wait();
new_work_thread.join();
}
std::promise 拥有一个 _State_base 成员变量 _M_state,在构造函数中初始化。另外一个 Result 类型的成员变量 _M_storage,是为了实现 break_promise。
std::async()
std::async() 函数提供了创建异步任务的接口。例如下面的例子,创建两个异步任务,返回 std::future 对象 f1 和 f2。另外,我们用到了两个不同的标志:std::launch::async 和 std::launch::deferred。我们可以从结果中看出两者的差异
#include <chrono>
#include <future>
#include <iostream>
#include <thread>
int main() {
// future from an async()
std::future<int> f1 = std::async(std::launch::async, [] {
for (int i = 0; i < 3; ++i) {
std::this_thread::sleep_for(std::chrono::milliseconds(500));
std::cout << std::this_thread::get_id() << " async1 sleep ...\n";
}
std::cout << std::this_thread::get_id() << " async1 return ...\n";
return 8;
});
std::future<int> f2 = std::async(std::launch::deferred, [] {
for (int i = 0; i < 3; ++i) {
std::this_thread::sleep_for(std::chrono::milliseconds(500));
std::cout << std::this_thread::get_id() << " async2 sleep ...\n";
}
std::cout << std::this_thread::get_id() << " async2 return ...\n";
return 8;
});
std::cout << std::this_thread::get_id() << " Waiting...\n";
f1.wait();
std::cout << std::this_thread::get_id()
<< " Done! f1 Results are: " << f1.get() << std::endl;
f2.wait();
std::cout << std::this_thread::get_id()
<< " Done! f2 Results are: " << f2.get() << std::endl;
}
上述程序的输出如下,可以看到 std::launch::async 会创建新的线程执行,而 std::launch::deferred 在原线程中执行。
140166656300864 Waiting…
140166656296704 async1 sleep …
140166656296704 async1 sleep …
140166656296704 async1 sleep …
140166656296704 async1 return …
140166656300864 Done! f1 Results are: 8
140166656300864 async2 sleep …
140166656300864 async2 sleep …
140166656300864 async2 sleep …
140166656300864 async2 return …
140166656300864 Done! f2 Results are: 8
std::async()
std::async() 的实现很简单
如果 policy 标记了 launch::async,就实例化 __future_base::_Async_state_impl 对象
否则实例化 __future_base::_Deferred_state 对象
然后用实例化的 State_status 子类对象构造一个 future 返回。
C++ 多线程详解之异步编程 std::packaged_task
std::packaged_task 将任何可调用对象(比如函数、lambda 表达式等等)封装成一个 task,可以异步执行。执行结果可以使用 std::future 获取。
比如下面的例子,构造一个 std::packaged_task 后,get_future() 函数返回一个 std::future 对象,可以获取 task 异步或者同步执行的结果。
#include <cmath>
#include <functional>
#include <future>
#include <iostream>
#include <thread>
// unique function to avoid disambiguating the std::pow overload set
int f(int x, int y) { return std::pow(x, y); }
void task_lambda() {
std::packaged_task<int(int, int)> task(
[](int a, int b) { return std::pow(a, b); });
std::future<int> result = task.get_future();
task(2, 9);
std::cout << "task_lambda:\t" << result.get() << '\n';
}
void task_bind() {
std::packaged_task<int()> task(std::bind(f, 2, 11));
std::future<int> result = task.get_future();
task();
std::cout << "task_bind:\t" << result.get() << '\n';
}
void task_thread() {
std::packaged_task<int(int, int)> task(f);
std::future<int> result = task.get_future();
std::thread task_td(std::move(task), 2, 10);
task_td.join();
std::cout << "task_thread:\t" << result.get() << '\n';
}
int main() {
task_lambda();
task_bind();
task_thread();
}
std::packaged_task 是如何实现的呢?下面就剖析 STL 源码,分析其实现原理。通过前面的分析,std::future 有一个成员变量,保存 _State_base 的子类对象。std::packaged_task 就拓展了 _State_base 的功能,用于绑定到 std::future,用于传递 task 状态。















 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









