







文章目录
相关文章:
1. 降维
假设你在使用一组数据来预测房价,你的数据包含以下特征:
-
房子面积
-
房间数量
-
附近学校排名
-
社区安全
但是可以看出,1、2 在于描述房子的大小,而 3、4 在描述周边环境。因此我们可以用两个新的特征来预测房价:1. 房子大小;2. 周边环境,我们称之为潜在变量。现在可能我们有很多可测量的特征,但或许只有少量的潜在特征,其中包含大部分的信息。
在本文中,我们主要讨论的是如何将维度降低,降低维度的方法有两种:1.特征选择,2. 特征提取。
特征选择指的是从已有变量中选择较少的变量,如用“房子面积”来描述“房子大小”,用“社区安全”来描述“周边环境”,如逐步回归,在 Sklearn 中用 SelectKBest 选择K个最合适的特征,或用 SelectPercentile 选取前百分比的特征。
特征提取则是对同一类的变量进行融合,假设现在有很多特征可以使用,但只有一分布特征在驱动这个数据模式。因此我们希望找出一个组合特征(omposite feature,又称为主成分 principle component),从而将一大堆特征缩减至几个特征。如将“房子面积”和“房间数量”融合为“房子大小”,将“附近学校排名”和“社会安全”融合为“周边环境”,这就是降维,将维数从 4 降到了 2。
主成分分析(Principal Component Analysis, PCA)是最常用的一种降维方法,除此之外还有增量主成分分析(IPCA)、核主成分分析(KPCA)、局部线性嵌入(LLE)、多维缩放(SDA)、等度量映射(Isomap)、t-分布随机近邻嵌入(t-SNE)和线性判别(LDA)。[1]
2. PCA
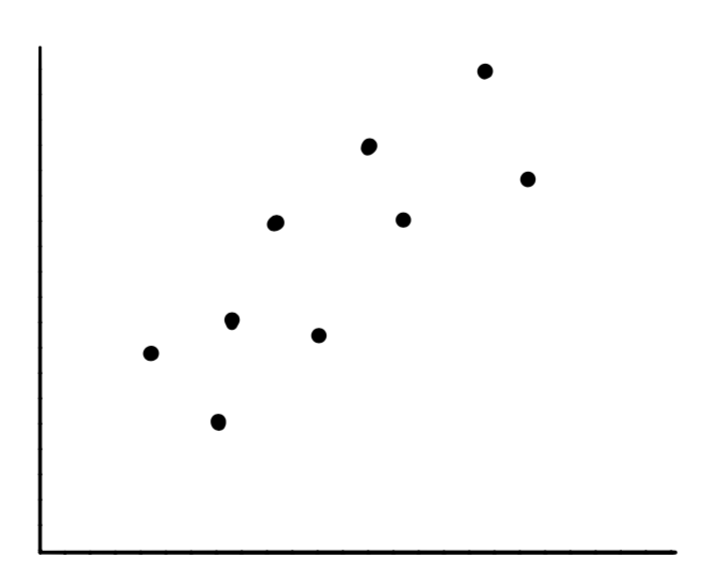
假设下面是房子面积和房间数量的散点图,X 轴为房子面积,Y 轴为房间数量:
首先我们可以画出他们的主成分,如下所示:
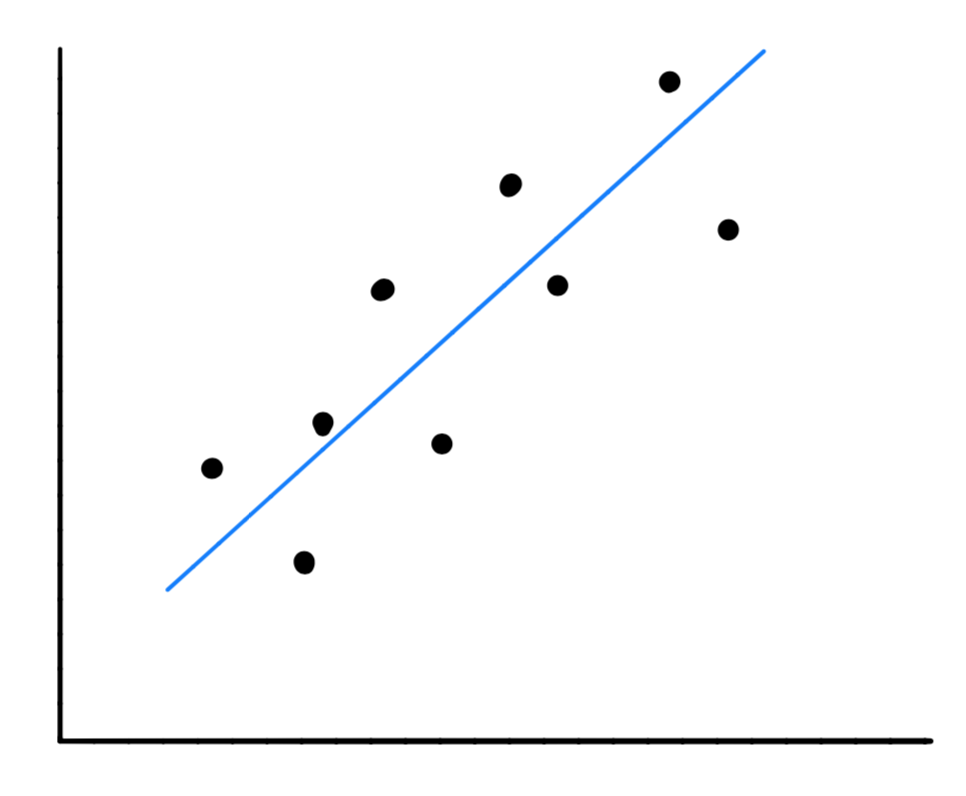
这看起来像个回归问题,但并不是这样的。在回归中,我们的目的是预测与输入值对应的输出值,在这里,我们并不是要预测任何值,而是算出数据的大致方向,使得我们的数据能够在尽量少地损失信息的同时映射在该方向上。
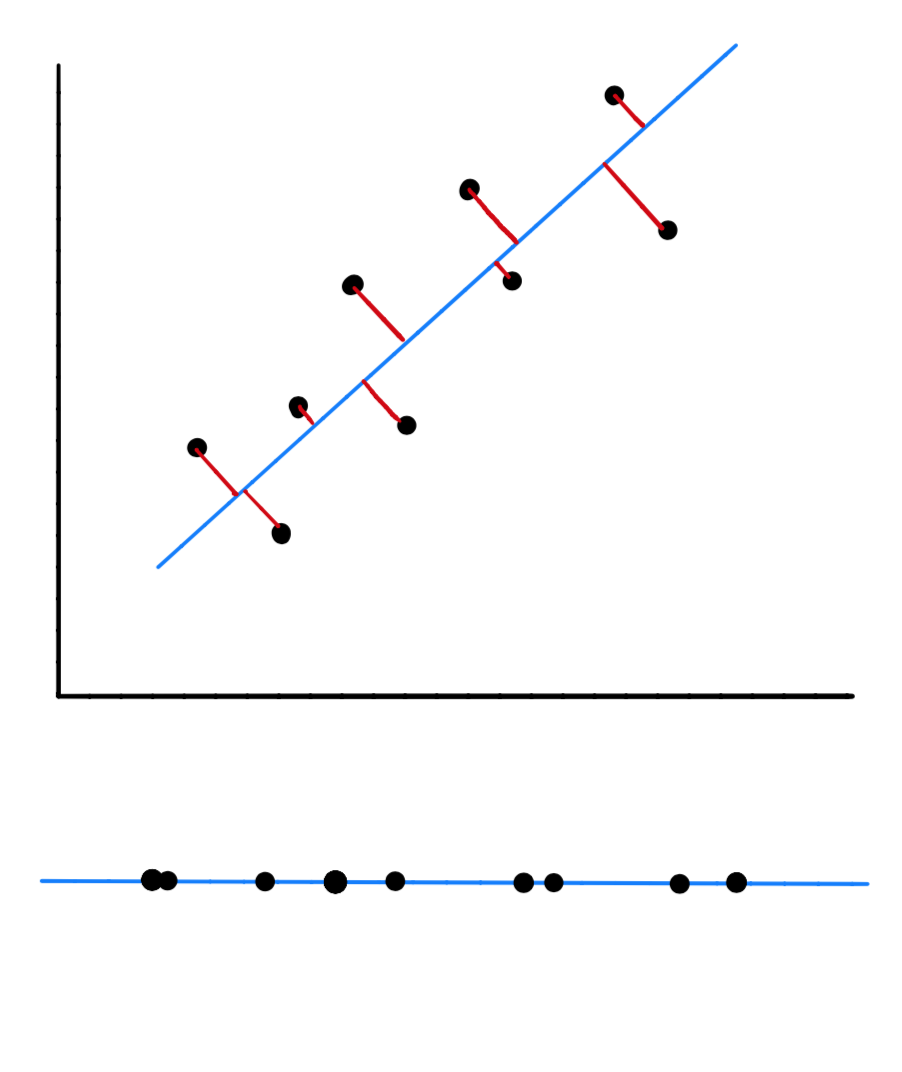
当我们找到了数据的主成分后,也就是向量的方向后,我们可以对数据进行一个映射,如下所示,我们的原始数据是二维的,但是,当我们把映射到主成分上之后,它就变成一维数据了。
下面,我将介绍如何确定主成分。
2.1 最大化方差和最小化损失
对于我们的数据,可以用一个椭圆,这个椭圆可以用两个参数来表示:短轴的距离和长轴的距离,可以看到,在长轴上,数据更加的分散,即方差更大。我们要做的就是找到方差最大的方向。
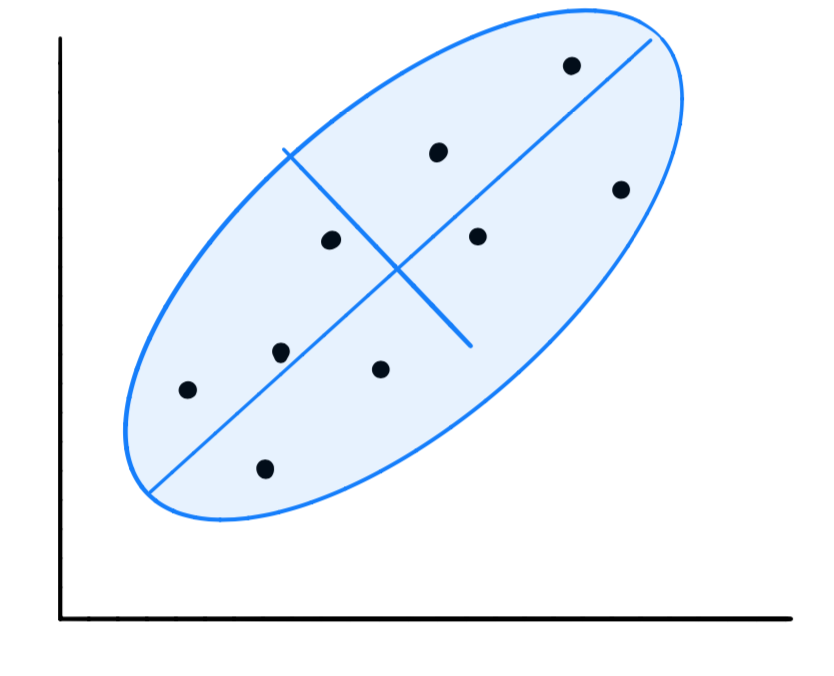
为什么我们要找出具有最大方差的方向呢。换而言之,当我们在进行映射时,为什么要将所有数据点映射到方差最大的方向上呢?这是因为当我们沿着方差最大的方向进行映射时,它能够在最大程度上保留原有数据中所含信息。
当我们对数据进行映射时,就会造成信息损失,信息的损失量就等于某个特定的点与它在这条线上的新位置之间的距离:
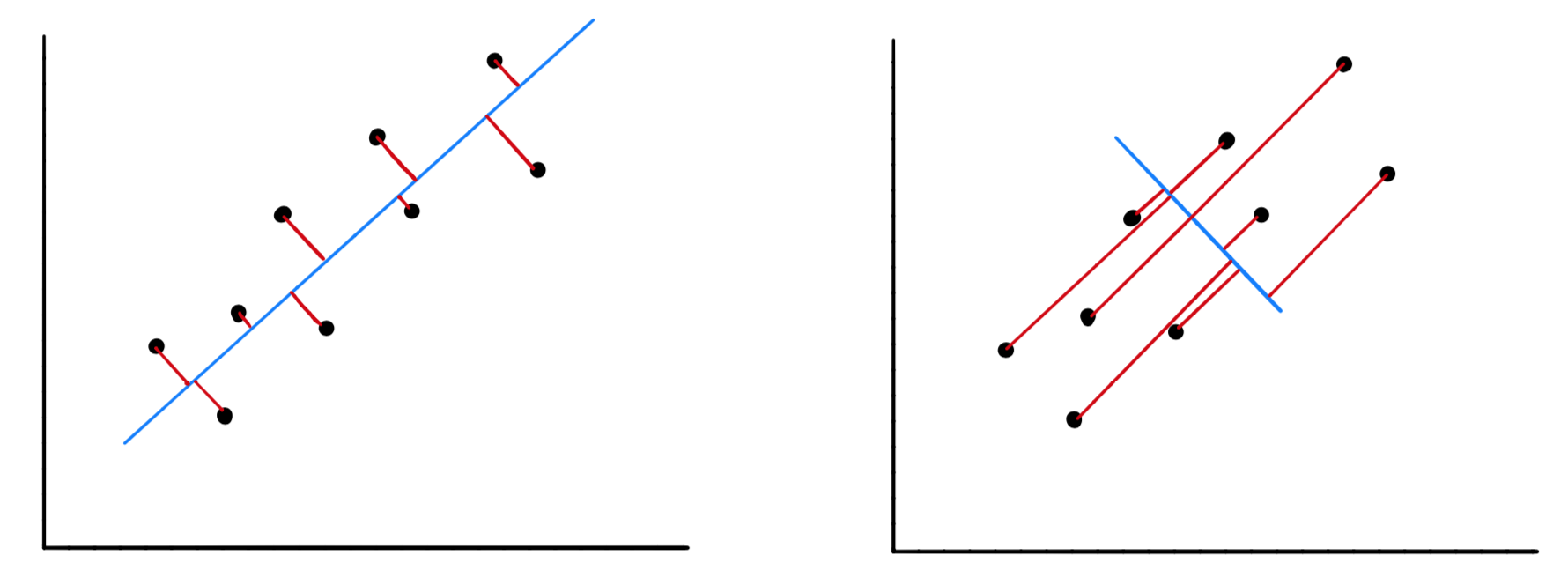
可以看到,对于图 5 的右图而言,此时数据在该方向上映射的方差最小,但信息损失也就最大。因此当我们将方差最大化的同时,实际上是将点与其在该线上的投影之间的距离最小化,即最小化信息损失。
2.2 坐标轴旋转
PCA 实际上是先对坐标轴进行旋转,通过计算数据映射在每个方向上的后的方差,选取前 K 个方差最大的特征。
3. PCA 推导
3.1 PCA 算法推导
假设输入样本为 Z = { Z 1 , Z 2 , . . . , Z m } Z=\{Z_1,Z_2,...,Z_m\} Z={ Z1,Z2,...,Zm},我们要通过 PCA 从 m m m 维降至 k k k 维,首先对样本进行中心化,即对每个属性减去其对应的均值:
X = { Z 1 − Z 1 ˉ , Z 2 − Z 2 ˉ , . . . , Z m − Z m ˉ } = { X 1 , X 2 , . . . , X m } (1) \begin{aligned} X & = \{Z_1-\bar{Z_1}, Z_2-\bar{Z_2}, ...,Z_m-\bar{Z_m} \} \\ & = \{X_1,X_2,...,X_m\}\\ \end{aligned}\tag{1} X={ Z1−Z1ˉ,Z2−Z2ˉ,...,Zm−
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









