









文章目录
相关文章:
1. 信息熵 Information Entropy
信息是个很抽象的概念。人们常常说信息很多,或者信息较少,但却很难说清楚信息到底有多少。比如一本五十万字的中文书到底有多少信息量。直到1948年,香农提出了“信息熵”的概念,才解决了对信息的量化度量问题。
信息熵这个词是香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述不确定性。
- 随机变量 x x x的信息熵计算公式: H ( x ) = − ∑ i = 1 n P ( x i ) l o g 2 ( P i ) H(x)= -\sum_{i=1}^nP(x_i)log_2(P_i) H(x)=−∑i=1nP(xi)log2(Pi)
- 信息熵越大,则表示不确定性越高。
- 在文本中,当不同的词汇越多时,其信息熵越大,直观上来说就是所包含的信息越多
熵:在物理的热力学中,用熵来表示分子状态混乱程度。当一个物体温度越高时,其内部粒子活动越剧烈,也越混乱。因此混乱程度越高,熵越大。
1.1 信息熵公式推导
- 计算取出结果与原顺序相同的概率:
P ( x i ) = P ( x 1 ) × P ( x 2 ) × . . . × P ( x n ) (1) P(x_i)=P(x_1)\times P(x_2) \times...\times P(x_n)\tag{1} P(xi)=P(x1)×P(x2)×...×P(xn)(1)
- 将概率公式取以2为底的对数变换,得到信息量 I ( x i ) I(x_i) I(xi)的公式:
I ( x i ) = l o g 2 ( 1 P ( x i ) ) = − l o g 2 ( P ( x i ) ) (2) I(x_i)=log_2(\frac{1}{P(x_i)})=-log_2(P(x_i))\tag{2} I(xi)=log2(P(xi)1)=−log2(P(xi))(2)
- 随机变量 x x x的信息熵计算公式::
H ( x ) = E [ I ( x i ) ] = − E [ l o g 2 ( P ( x i ) ) ] = − ∑ i = 1 n P ( x i ) l o g 2 ( P i ) (3) H(x)=E[I(x_i)]=-E[log_2(P(x_i))]= -\sum_{i=1}^nP(x_i)log_2(P_i)\tag{3} H(x)=E[I(xi)]=−E[log2(P(xi))]=−i=1∑nP(xi)log2(Pi)(3)
对于样本集合 D D D来说,随机变量 x x x是样本的类别,即假设样本有 k k k个类别,样本总数为 D D D,则类别 i i i的概率是 c i D \frac{c_i}{D} Dci。
因此样本集合
D
D
D的经验熵为:
H
(
D
)
=
−
∑
i
=
1
k
∣
c
i
∣
∣
D
∣
l
o
g
2
(
∣
c
i
∣
∣
D
∣
)
(4)
H(D)=-\sum_{i=1}^k \frac{|c_i|}{|D|}log_2(\frac{|c_i|}{|D|}) \tag{4}
H(D)=−i=1∑k∣D∣∣ci∣log2(∣D∣∣ci∣)(4)
例1:假设有四个球,从中随机放回地抽出四个球,下面计算各个事件的信息熵:
1.红红红红,则事件
x
x
x的信息熵:
H ( x ) = − ∑ i = 1 4 P ( x i ) l o g 2 ( P i ) = [ 1 × l o g 2 ( 1 ) + 1 × l o g 2 ( 1 ) + 1 × l o g 2 ( 1 ) + 1 × l o g 2 ( 1 ) ] = 0 H(x)=-\sum_{i=1}^4P(x_i)log_2(P_i) =[1 \times log_2(1)+1 \times log_2(1)+1 \times log_2(1)+1 \times log_2(1)]=0 H(x)=−∑i=14P(xi)log2(Pi)=[1×log2(1)+1×log2(1)+1×log2(1)+1×log2(1)]=0
2.红红红蓝,则事件
y
y
y的信息熵:
H ( y ) = − ∑ i = 1 4 P ( y i ) l o g 2 ( P i ) = [ 0.75 × l o g 2 ( 0.75 ) + 0.75 × l o g 2 ( 0.75 ) + 0.75 × l o g 2 ( 0.75 ) + 0.25 × l o g 2 ( 0.25 ) ] = 1.4338 H(y)=-\sum_{i=1}^4P(y_i)log_2(P_i) =[0.75 \times log_2(0.75)+0.75 \times log_2(0.75)+0.75 \times log_2(0.75)+0.25 \times log_2(0.25)]=1.4338 H(y)=−∑i=14P(yi)log2(Pi)=[0.75×log2(0.75)+0.75×log2(0.75)+0.75×log2(0.75)+0.25×log2(0.25)]=1.4338
3.红红蓝蓝,则事件
z
z
z的信息熵:
H ( z ) = − ∑ i = 1 4 P ( z i ) l o g 2 ( P i ) = [ 0.5 × l o g 2 ( 0.5 ) + 0.5 × l o g 2 ( 0.5 ) + 0.5 × l o g 2 ( 0.5 ) + 0.5 × l o g 2 ( 0.5 ) ] = 2 H(z)=-\sum_{i=1}^4P(z_i)log_2(P_i) =[0.5 \times log_2(0.5)+0.5 \times log_2(0.5)+0.5 \times log_2(0.5)+0.5 \times log_2(0.5)]=2 H(z)=−∑i=14P(zi)log2(Pi)=[0.5×log2(0.5)+0.5×log2(0.5)+0.5×log2(0.5)+0.5×log2(0.5)]=2
由上面三个例子可以看出,当混乱程度越高时,信息熵越大。
关于各类熵的定义及推导,可参考这篇文章。
2. 信息增益 Information Gain
信息增益:
对于待划分的数据集
D
D
D,其信息熵大小是固定的,但是划分后子代熵之和是不定的。子代熵越小说明使用此特征划分得到的子集不确定性越小(纯度越高),因此父代与子代的信息熵之差(信息增益)越大,说明使用当前特征划分数据集
D
D
D时,其纯度上升的更快[1]。
与决策树关系:
我们在构建最优的决策树时总希望能够快速到达村度更高的集合,这一点可以参考优化算法中的梯度下降(每一步沿着负梯度方法最小化损失函数使函数值快速减小)同理,在决策树构建的过程中我们总是希望集合往最快到达纯度更高的子集合方向发展,因此我们总是选择使得信息增益最大的特征来划分当前数据集 D D D。
使用特征
A
A
A划分数据集
D
D
D,计算划分前后各个数据集的信息熵,并计算信息增益:
g ( D , A ) = H ( D ) − H ( D ∣ A ) (5) g(D,A)=H(D)-H(D|A) \tag{5} g(D,A)=H(D)−H(D∣A)(5)
其中,假设特征 A A A将数据集 D D D划分为 n n n个子代,则 H ( D ∣ A ) H(D|A) H(D∣A)为划分后子代的平均信息熵:
H ( D ∣ A ) = ∑ i = 1 n P ( A i ) H ( A i ) (6) H(D|A)= \sum_{i=1}^nP(A_i)H(A_i) \tag{6} H(D∣A)=i=1∑nP(Ai)H(Ai)(6)
例2:假设我们在调查性别与活跃度哪一个对用户流失影响越大。[2]
样本如下:
| Gender | Activation | is_lost |
|---|---|---|
| M | H | 0 |
| F | M | 0 |
| M | L | 1 |
| F | H | 0 |
| M | H | 0 |
| M | M | 0 |
| M | M | 1 |
| F | M | 0 |
| F | L | 1 |
| F | M | 0 |
| F | H | 0 |
| M | L | 1 |
| F | L | 0 |
| M | H | 0 |
| M | H | 0 |
按性别分类:
| \ | Lost | No-lost | Sum |
|---|---|---|---|
| Whole | 5 | 10 | 15 |
| Male | 3 | 5 | 8 |
| Female | 2 | 5 | 7 |
整体熵:
E ( S ) = − [ 5 15 l o g 2 ( 5 15 ) + 10 15 l o g 2 ( 10 15 ) ] = 0.9182 E(S)=-[\frac{5}{15}log_2(\frac{5}{15})+\frac{10}{15}log_2(\frac{10}{15})]=0.9182 E(S)=−[155log2(155)+1510log2(1510)]=0.9182
性别熵:
E ( g 1 ) = − [ 3 8 l o g 2 ( 3 8 ) + 5 8 l o g 2 ( 5 8 ) ] = 0.0.9543 E(g_1)=-[\frac{3}{8}log_2(\frac{3}{8})+\frac{5}{8}log_2(\frac{5}{8})]=0.0.9543 E(g1)=−[83log2(83)+85log2(85)]=0.0.9543
E ( g 2 ) = − [ 2 7 l o g 2 ( 2 7 ) + 2 7 l o g 2 ( 2 7 ) ] = 0.8631 E(g_2)=-[\frac{2}{7}log_2(\frac{2}{7})+\frac{2}{7}log_2(\frac{2}{7})]=0.8631 E(g2)=−[72log2(72)+72log2(72)]=0.8631
性别信息增益:
g
(
S
∣
g
)
=
E
(
S
)
−
8
15
E
(
g
1
)
−
7
15
E
(
g
2
)
=
0.0064
g(S|g)=E(S)-\frac{8}{15}E(g_1)-\frac{7}{15}E(g_2)=0.0064
g(S∣g)=E(S)−158E(g1)−157E(g2)=0.0064
按活跃度分类
| \ | Lost | No-lost | Sum |
|---|---|---|---|
| Whole | 5 | 10 | 15 |
| Hight | 0 | 6 | 6 |
| Mid | 1 | 4 | 5 |
| Low | 4 | 0 | 4 |
活跃度熵:
E ( a 1 ) = 0 E(a_1)=0 E(a1)=0
E ( a 2 ) = 0.7219 E(a_2)=0.7219 E(a2)=0.7219
E ( a 2 ) = 0 E(a_2)=0 E(a2)=0
活跃度信息增益:
g
(
S
∣
a
)
=
E
(
S
)
−
6
15
E
(
a
1
)
−
5
15
E
(
a
2
)
−
4
15
E
(
a
3
)
=
0.0064
g(S|a)=E(S)-\frac{6}{15}E(a_1)-\frac{5}{15}E(a_2)-\frac{4}{15}E(a_3)=0.0064
g(S∣a)=E(S)−156E(a1)−155E(a2)−154E(a3)=0.0064
活跃度信息增益比性别信息增益大,也就是说,活跃度对用户流失的影响比性别大。
2.1 信息增益最大化
2.1.1 利用离散特征进行分类
- 计算父代熵
- 计算子代熵
- 计算信息增益,按信息增益较大的进行分类
- 如果分类后结果不理想,可将其分类作为父代继续进行分类
例3:仍以上面的例子为例,之前,我们已经计算出了活跃度对于用户流失的影响较大,当用户的活跃度为Hight时,用户流失为0,当用户活跃度为Low时,用户全部流失,因此可以得到:
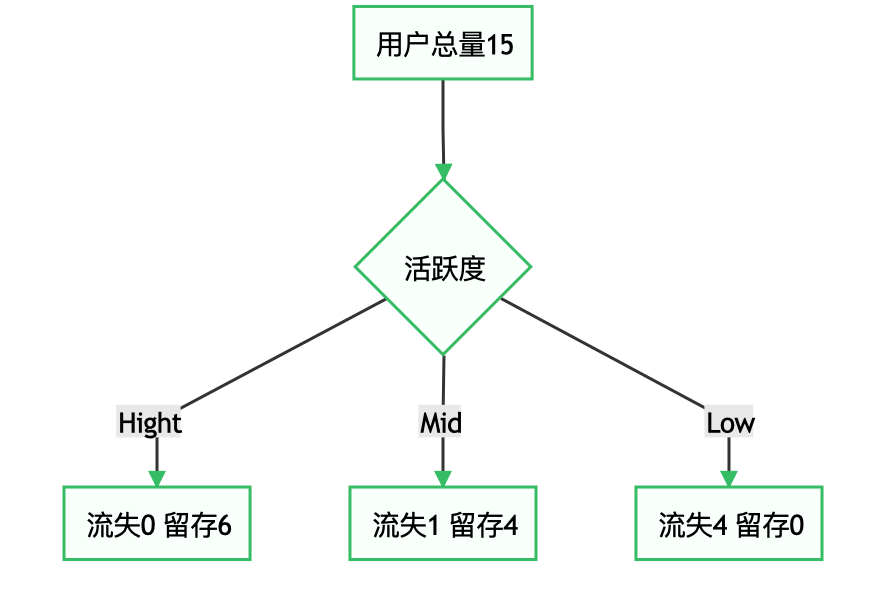
可以看到,Hight和Low组的信息熵为0,纯度已达到最高;但是Mid组纯度未达到最高,因此以Mid组的数据作为父代,重复例2的过程,由于例2数据只有两个特征,因此只能尝试使用性别分类;若例2数据有2个以上特征,则此时可以重复例2过程,计算其余特征的信息增益,并选取信息增益最大的特征作为分类依据。由此也可以看出,离散特征决策树的最大深度不超过其特征数(连续特征决策树的特征可多次使用)。
下面尝试使用性别分组,Mid组的样本:
| Gender | Activation | is_lost |
|---|---|---|
| F | M | 0 |
| M | M | 0 |
| M | M | 1 |
| F | M | 0 |
| F | M | 0 |
对Mid组使用性别分类后的结果:
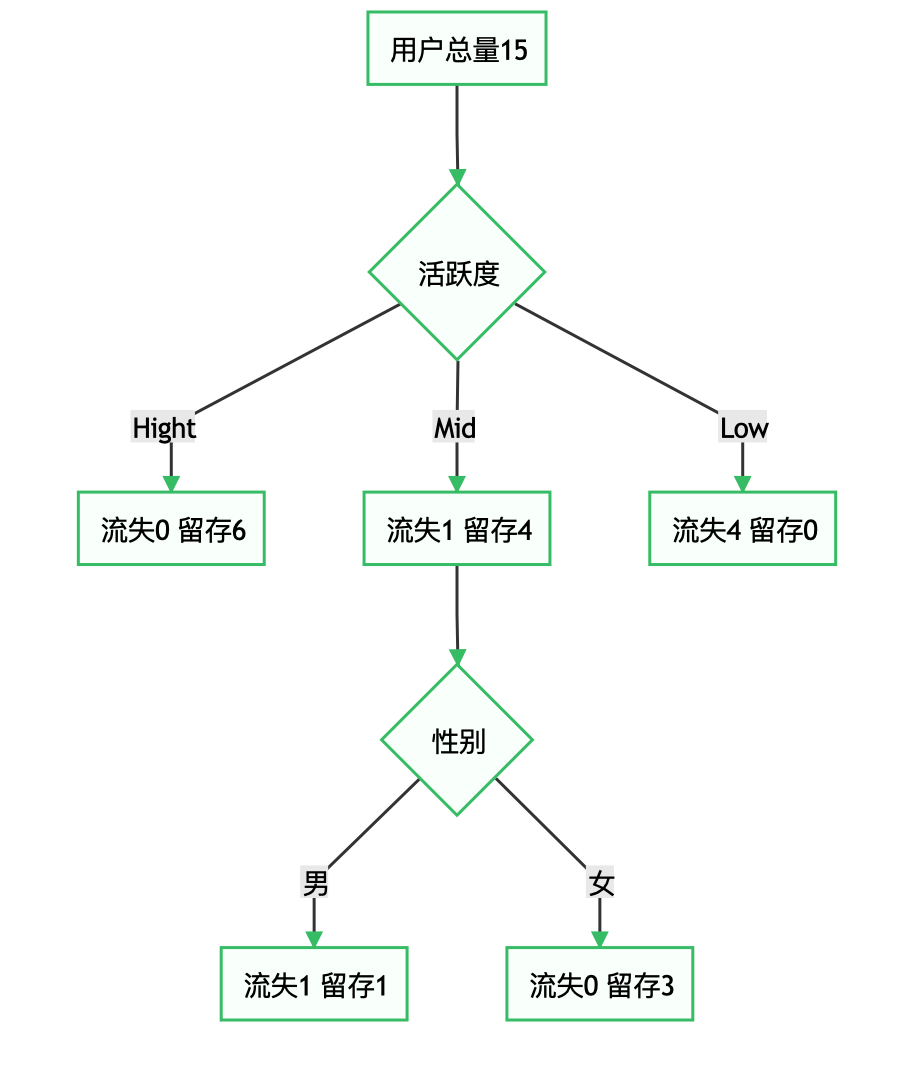
2.1.2 利用连续特征进行分类
2.1.2.1 二分法
因为连续特征属性的可取值数目不再有限,因此不能像前面处理离散属性一样枚举离散属性来对节点进行划分,因此需要对连续属性离散化。
常用的离散化策略是二分法:
给定训练集 D D D和连续属性 a a a,假定 a a a在 D D D上出现了 n n n个不同的取值,先把这些值从小到达排序,记为 { a 1 , a 2 , . . . , a n } \{a^1,a^2,...,a^n\} {a1,a2,...,an},基于划分点 t t t可以将 D D D分为子集 D t − D_t^- Dt−和 D t + D_t^+ Dt+,其中 D t − D_t^- Dt−是包含那些属性 a a a上取值不大于 t t t的样本, D t + D_t^+ Dt+则包含哪些在属性 a a a上取值大于 t t t的样本。显然,对相邻的属性取值 a i a^i ai与 a i + 1 a^{i+1} ai+1来说, t t t在区间 [ a i , a i + 1 ) [a^i,a^{i+1}) [ai,ai+1)中取任意值所产生的划分结果相同。因此,对连续属性 a a a,我们可考虑包含 n − 1 n-1 n−1个元素的候选划分点集合:
T a = { a i + a i + 1 2 } ( 1 ≤ i ≤ n − 1 ) (7) T_a=\{ \frac{a^i+a^{i+1}}{2} \} \quad (1 \leq i \leq n-1) \tag{7} Ta={2ai+ai+1}(1≤i≤n−1)(7)
即把区间 [ a i , a i + 1 ) [a^i,a^{i+1}) [ai,ai+1)的中位点 a i + a i + 1 2 \frac{a^i+a^{i+1}}{2} 2ai+ai+1作为候选划分点,然后就可以像前面处理离散属性值那样来考虑这些划分点,并选择最后的划分点进行样本集合的划分,使用的公式如下:
g ( D , a ) = max t ∈ T a g ( D , a , t ) = max t ∈ T a { E ( D ) − ∑ λ ∈ ( − , + ) ∣ D t λ ∣ ∣ D ∣ l o g 2 ( ∣ D t λ ∣ ∣ D ∣ ) } (8) g(D,a)=\max \limits_{t\in T_a}g(D,a,t) =\max \limits_{t\in T_a} \{E(D)-\sum_{\lambda \in(-,+)} \frac{|D_t^\lambda|}{|D|}log_2(\frac{|D_t^\lambda|}{|D|})\} \tag{8} g(D,a)=t∈Tamaxg(D,a,t)=t∈Tamax{E(D)−λ∈(−,+)∑∣D∣∣Dtλ∣log2(∣D∣∣Dtλ∣)}(8)
其中
g
(
D
,
a
,
t
)
g(D,a,t)
g(D,a,t)是样本集
D
D
D基于划分点
t
t
t二分后的信息增益。
划分的时候,选择使
g
(
D
,
a
,
t
)
g(D,a,t)
g(D,a,t)最大的划分点。[3]
2.1.2.2 信息熵、信息增益及二分法的Python实现
例4:下面以周志华《机器学习》—西瓜数据集3.0 为例,计算特征“密度”的最佳划分点以及其信息增益,数据如下:
import pandas as pd
import numpy as np
df = pd.read_csv("Data/Watermelon_Data.txt")
df['好瓜'] = df['好瓜'].map({'是':1, '否':0})
df
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.460 | 1 |
| 1 | 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 1 |
| 2 | 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 1 |
| 3 | 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.608 | 0.318 | 1 |
| 4 | 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.556 | 0.215 | 1 |
| 5 | 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.403 | 0.237 | 1 |
| 6 | 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 0.481 | 0.149 | 1 |
| 7 | 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 0.437 | 0.211 | 1 |
| 8 | 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.666 | 0.091 | 0 |
| 9 | 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 0.243 | 0.267 | 0 |
| 10 | 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 0.245 | 0.057 | 0 |
| 11 | 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 0.343 | 0.099 | 0 |
| 12 | 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0.639 | 0.161 | 0 |
| 13 | 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 0.657 | 0.198 | 0 |
| 14 | 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.360 | 0.370 | 0 |
| 15 | 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0.593 | 0.042 | 0 |
| 16 | 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.719 | 0.103 | 0 |
- 以数据集中的
“密度”为例,决策树开始学习时,根节点包含的17个训练样本在属性上取值均不同。我们把“密度”这些值从小到大排序:
Density_arr = df['密度'].sort_values()
f = lambda x: round(x,3) # 保留三位小数
Density_arr = Density_arr.apply(f)
print(Density_arr.tolist())
[0.243, 0.245, 0.343, 0.36, 0.403, 0.437, 0.481, 0.556, 0.593, 0.608, 0.634, 0.639, 0.657, 0.666, 0.697, 0.719, 0.774]
- 根据公式(7)计算分割点 T a T_a Ta:
T_midu = (Density_arr+Density_arr.shift(-1))/2
T_midu = T_midu[:-1].apply(f) # 二分法获得的(n-1)个分割点
T_midu.index=np.arange(len(T_midu))
print(T_midu.tolist())
[0.244, 0.294, 0.352, 0.382, 0.42, 0.459, 0.518, 0.575, 0.601, 0.621, 0.637, 0.648, 0.661, 0.681, 0.708, 0.746]
- 计算父代信息熵(Ent_D)
# 以西瓜质量划分集合
def divide_arr(arr):
arr = df['好瓜'].iloc[arr.index.values.tolist()]
arr_len = len(arr)
Left_len = sum(arr == 1)
Right_len = arr_len - Left_len
return arr_len, Left_len, Right_len
# 计算集合信息熵
def entropy(arr):
arr_len, Left_len, Right_len = divide_arr(arr)
L_frac = Left_len/arr_len
R_frac = Right_len/arr_len
if L_frac==0:
Ent = -(R_frac*np.log2(R_frac))
elif R_frac==0:
Ent = -(L_frac*np.log2(L_frac))
else:
Ent = -(L_frac*np.log2(L_frac) + R_frac*np.log2(R_frac))
Ent = round(Ent,3)
return Ent
Ent_D = entropy(Density_arr)
Ent_D
0.998
- 利用第2步获得的分割点,计算(n-1)种分法对应的子代信息熵(gen_entropy_arr):
# 利用分割点二分父代
def binary(arr, node):
arr_L = arr[arr<=node]
arr_L.name = 'arr_L'
arr_R = arr[arr>node]
arr_R.name = 'arr_R'
return arr_L, arr_R
# 计算子代熵
def gen_entropy(arr, node):
arr_L, arr_R = binary(arr, node)
len_L = len(arr_L)
len_R = len(arr_R)
len_D = len_L + len_R
Ent_gen = len_L/len_D*entropy(arr_L) + len_R/len_D*entropy(arr_R)
Ent_gen = round(Ent_gen,3)
return Ent_gen
gen_entropy_arr = pd.Series(np.empty(len(T_midu)))
for i, cut in enumerate(T_midu):
gen_entropy_arr.iloc[i] = gen_entropy(Density_arr, cut)
- 计算各类分法的信息增益:
df2 = pd.concat([T_midu, gen_entropy_arr], axis=1)
df2.columns=['划分点','子集熵']
df2['信息增益'] = Ent_D - df2['子集熵']
df2
| 划分点 | 子集熵 | 信息增益 | |
|---|---|---|---|
| 0 | 0.244 | 0.941 | 0.057 |
| 1 | 0.294 | 0.880 | 0.118 |
| 2 | 0.352 | 0.811 | 0.187 |
| 3 | 0.382 | 0.735 | 0.263 |
| 4 | 0.420 | 0.904 | 0.094 |
| 5 | 0.459 | 0.967 | 0.031 |
| 6 | 0.518 | 0.994 | 0.004 |
| 7 | 0.575 | 0.995 | 0.003 |
| 8 | 0.601 | 0.995 | 0.003 |
| 9 | 0.621 | 0.994 | 0.004 |
| 10 | 0.637 | 0.967 | 0.031 |
| 11 | 0.648 | 0.991 | 0.007 |
| 12 | 0.661 | 0.997 | 0.001 |
| 13 | 0.681 | 0.973 | 0.025 |
| 14 | 0.708 | 0.997 | 0.001 |
| 15 | 0.746 | 0.931 | 0.067 |
- 因此信息增益最大值为0.263,对应划分点为0.382,如下所示:
print(df2.iloc[df2['信息增益'].idxmax()])
划分点 0.382
子集熵 0.735
信息增益 0.263
Name: 3, dtype: float64
继续对其他的特征进行以上步骤,可以得到其他特征的信息增益,因此该连续特征的决策树的第一个分割点为信息增益最大的特征所对应的分割点。
下面是本数据集中各特征的信息增益值:[4]
g ( D ∣ 色 泽 ) = 0.109 g ( D ∣ 根 蒂 ) = 0.143 g(D|色泽)=0.109 \quad g(D|根蒂)=0.143 g(D∣色泽)=0.109g(D∣根蒂)=0.143
g ( D ∣ 敲 声 ) = 0.141 g ( D ∣ 纹 理 ) = 0.381 g(D|敲声)=0.141 \quad g(D|纹理)=0.381 g(D∣敲声)=0.141g(D∣纹理)=0.381
g ( D ∣ 脐 部 ) = 0.289 g ( D ∣ 触 感 ) = 0.006 g(D|脐部)=0.289 \quad g(D|触感)=0.006 g(D∣脐部)=0.289g(D∣触感)=0.006
g ( D ∣ 密 度 ) = 0.262 g ( D ∣ 含 糖 率 ) = 0.349 g(D|密度)=0.262 \quad g(D|含糖率)=0.349 g(D∣密度)=0.262g(D∣含糖率)=0.349
由此可见,“纹理”的信息增益量值最大,因此”纹理“被选作根节点划分属性。只要重复以上过程,就能构造出一颗决策树:
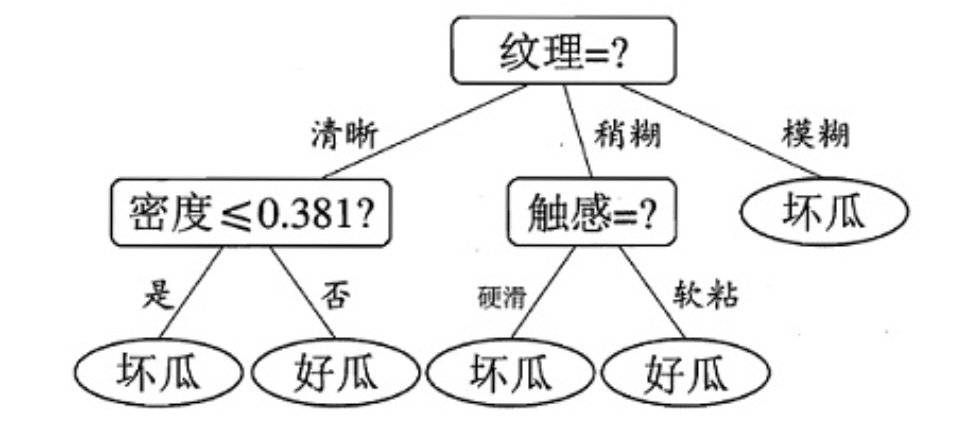
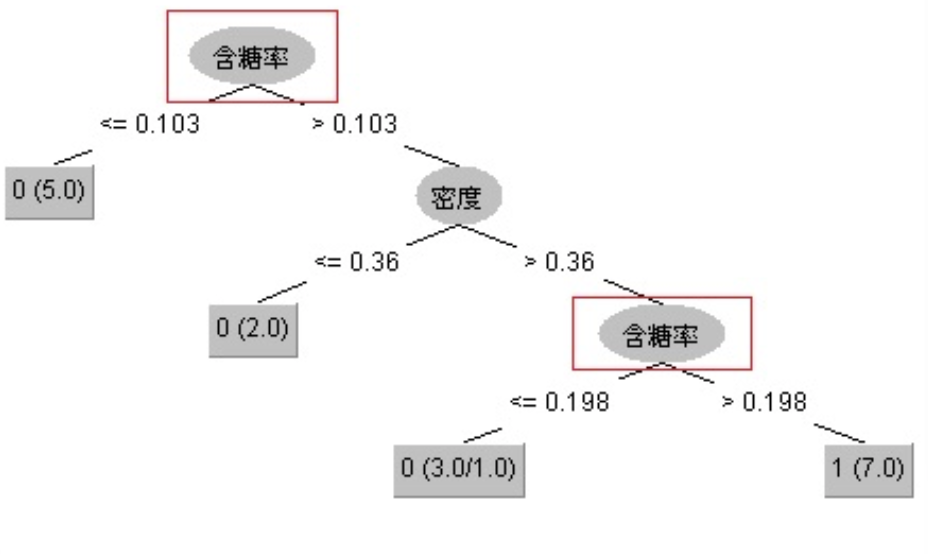
需要注意的是:与离散属性不同,若当前节点划分属性为连续属性,该属性还可以作为其后代节点的划分属性。如下图的一颗决策树,“含糖率”这个属性在根节点用了一次,后代节点也用了一次,只是两次划分点取值不同。
参考资料
[1] Tomcater321.决策树–信息增益,信息增益比,Geni指数的理解
[EB/OL].https://blog.csdn.net/Tomcater321/article/details/80699044, 2018-06-14.
[2] It_BeeCoder.机器学习中信息增益的计算方法 [EB/OL].https://blog.csdn.net/it_beecoder/article/details/79554388, 2018-03-14.
[3] 天泽28.决策树(decision tree)(三)——连续值处理 [EB/OL].https://blog.csdn.net/u012328159/article/details/79396893, 2018-02-28.
[4] 天泽28.决策树(decision tree)(一)——构造决策树方法 [EB/OL].https://blog.csdn.net/u012328159/article/details/70184415, 2017-04-18.















 1376
1376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









