









信息熵的概述
看过很多博客,发现大多文章只是对信息熵做了一些大致的介绍,如:信息熵代表一个随机变量的不确定性程度;也可理解为一个随机变量其值域用信息量编码后的最小码长数学期望。
但是对于信息熵的公式为何这样,网上没有找到相关的推导过程。针对这个问题,从信息熵代表一个随机变量其值域用信息量编码后的最小码长数学期望这一物理意义入手,本文使用最优化的方法,对信息熵公式进行了推导。过程中难免存在数学上的严谨性问题,欢迎各位指正。
随机变量分为离散型和连续型两种,本文仅对离散型变量进行讨论,关于连续型,其原理也是大同小异。
离散型随机变量的信息熵公式
设离散型随机变量X的值域为
{
x
1
,
x
2
,
.
.
.
,
x
i
,
.
.
.
x
n
}
\{x_1,x_2,...,x_i,...x_n\}
{x1,x2,...,xi,...xn},其取值为
x
i
x_i
xi时的概率为
p
i
p_i
pi,则其信息熵为:
H
(
X
)
=
∑
i
=
1
n
p
i
log
b
1
p
i
H\left(X\right)=\sum_{i=1}^{n}p_i \log_b \frac{1}{p_i}
H(X)=i=1∑npilogbpi1
上面公式中,常取b=2,主要是因为计算机编码中常用二进制编码,所以本文也是采用b=2进行讨论。下面谈谈对这个公式的理解。
信息熵公式理解
我们不妨先思考一个问题:假设离散型随机变量X的所有状态为
{
x
1
,
x
2
,
.
.
.
,
x
i
,
.
.
.
x
n
}
\{x_1,x_2,...,x_i,...x_n\}
{x1,x2,...,xi,...xn},当状态为
x
i
x_i
xi时的概率为
p
i
p_i
pi,那么使用二进制进行编码,设每个状态
x
i
x_i
xi的最终编码长度为
l
i
l_i
li,那么
l
i
l_i
li分别是多长,才能使得最终的平均编码长度最小(即前面说的码长期望值最小),也即使得下面公式最小:
L
=
p
1
l
1
+
p
2
l
2
+
.
.
.
+
p
n
l
n
L=p_1l_1+p_2l_2+...+p_nl_n
L=p1l1+p2l2+...+pnln
实际上解决了上面的问题后,最终会发现
L
m
i
n
=
H
(
X
)
L_{min}=H\left(X\right)
Lmin=H(X),即最小的码长期望值,实际上就是随机变量X的信息熵。
编码的约束条件
首先,针对上面的求最小化问题,我们仅仅是将其要优化的目标函数写出来而已,现在需要将此优化问题的条件补全,呈现出完整的最优化方程进行求解。
我们要使平均码长最小,当然会想到使得每个
l
i
l_i
li最小(最好都等于1),那么这个平均长度自然最小。但是对应状态数大于2的随机变量X来说,这显然不可能,因为如果每个状态的编码长度为1(即编码是0或1),那么最多可以表示2个状态,其余状态无法表示。所以在编码长度方面,存在着一定的限制条件,此即为我们要找的最优化方程的限制条件。下面讨论一下关于编码的限制条件:
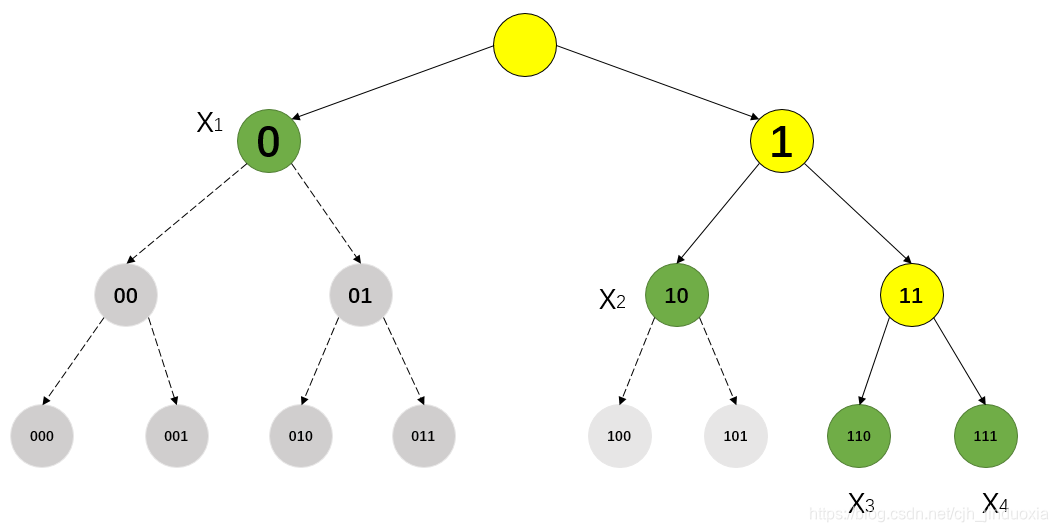
- 假设用二进制表示随机变量X(X的所有状态为 { x 1 , x 2 , x 3 , x 4 } \{x_1,x_2,x_3,x_4\} {x1,x2,x3,x4}),其编码长度不要求相同。如上图所示,假设可用的码长最长为3,所以上图中最多能代表的状态数为 2 3 = 8 2^3=8 23=8,现在只要编码4个状态,所以可以个状态的码长均为2(用00,01,10,11分别代表4个状态),也可以使用如上图所示的编码(图中黄色节点表示该节点还未被编码,绿色节点表示该节点已经被用于编码,灰色节点表示不能再被用于编码),当然也可以用其他的编码方式。但是无论如何进行编码,都要符合这个条件:母节点的编码被使用后,其下面所有的字节点编码均不能再使用,不然会导致编码重复,无法实现编码的单一性。如:用编码0来代表 x 1 x_1 x1,则0下面的字节点 00 , 01 , . . . , 011 00,01,...,011 00,01,...,011均不能为其他状态使用(比如,假设有3个状态其编码分别为0,1,01,则在使用中,如果出现01编码,无法判断它是代表的哪个状态,其有可能是01单个状态,也有可能是0、1两个一前一后的状态。)
- 现假设最长的编码长度为
l
X
l_X
lX,则理论上可以编码表示
2
l
X
2^{l_X}
2lX个可能状态,但是对于编码为0的状态,显然它一个状态就占用了人家
2
l
X
−
1
2^{l_X-1}
2lX−1种可能状态的坑。显然,对于某一状态
x
i
x_i
xi,其编码长度为
l
x
i
l_{x_i}
lxi,则就这一个状态就占用了一共
2
l
X
−
l
x
i
2^{l_X-l_{x_i}}
2lX−lxi种可能状态的坑。前面说过,最长的编码长度为
l
X
l_X
lX,则理论上只有
2
l
X
2^{l_X}
2lX种可能状态坑,而且各个状态的坑之间不能有重叠(不然无法保证单一性,最后无法辨别,前面1中有说),所以就有下面这个约束条件:
∑ i = 1 n 2 l X − l x i ≤ 2 l X ⟹ 1 2 l 1 + 1 2 l 2 + . . . + 1 2 l n ≤ 1 \sum_{i=1}^{n}2^{l_X-l_{x_i}} \leq 2^{l_X} \Longrightarrow \frac{1}{2^{l_1}}+\frac{1}{2^{l_2}}+...+\frac{1}{2^{l_n}} \leq 1 i=1∑n2lX−lxi≤2lX⟹2l11+2l21+...+2ln1≤1
信息熵公式的推导
经过前面的介绍,我们现在可以将上面提到的最小编码期望值问题,表示成一个最优化方程的求解问题了。
问题描述: 对于随机变量X,其所有的可能状态为
{
x
1
,
x
2
,
.
.
.
,
x
n
}
\left\{x_1,x_2,...,x_n\right\}
{x1,x2,...,xn},各个状态出现的概率分别为
{
p
1
,
p
2
,
.
.
.
,
p
n
}
\left\{p_1,p_2,...,p_n\right\}
{p1,p2,...,pn},现假设每个状态的编码长度为
{
l
1
,
l
2
,
.
.
.
,
l
n
}
\left\{l_1,l_2,...,l_n\right\}
{l1,l2,...,ln},其中
l
i
∈
Z
+
l_i \in Z^+
li∈Z+,求最短的平均编码长度,于是可以列出以下最优化式子:
{
m
i
n
p
1
l
1
+
p
2
l
2
+
.
.
.
+
p
n
l
n
s
.
t
.
1
2
l
1
+
1
2
l
2
+
.
.
.
+
1
2
l
n
≤
1
l
i
≥
0
a
n
d
l
i
∈
Z
+
,
1
≤
i
≤
n
\begin{cases} min & p_1l_1+p_2l_2+...+p_nl_n\\ s.t. & \frac{1}{2^{l_1}}+\frac{1}{2^{l_2}}+...+\frac{1}{2^{l_n}} \leq 1 \\ & l_i \geq 0\ and\ l_i \in Z^+,\ \ 1\leq i \leq n \end{cases}
⎩⎪⎨⎪⎧mins.t.p1l1+p2l2+...+pnln2l11+2l21+...+2ln1≤1li≥0 and li∈Z+, 1≤i≤n
显然,平常的编码长度只能是整数问题,所以上面的式子是整数优化问题。但是对于更一般的问题,可以不局限于码长是整数,所以这里将码长为整数这一限制去除,得到下面的优化方程:
{
m
i
n
p
1
l
1
+
p
2
l
2
+
.
.
.
+
p
n
l
n
s
.
t
.
1
2
l
1
+
1
2
l
2
+
.
.
.
+
1
2
l
n
≤
1
l
i
≥
0
,
1
≤
i
≤
n
\begin{cases} min & p_1l_1+p_2l_2+...+p_nl_n\\ s.t. & \frac{1}{2^{l_1}}+\frac{1}{2^{l_2}}+...+\frac{1}{2^{l_n}} \leq 1 \\ & l_i \geq 0,\ \ 1\leq i \leq n \end{cases}
⎩⎪⎨⎪⎧mins.t.p1l1+p2l2+...+pnln2l11+2l21+...+2ln1≤1li≥0, 1≤i≤n
不妨令
l
i
′
=
−
l
i
l^{'}_i=-l_i
li′=−li,则可以化简为
{
m
i
n
−
(
p
1
l
1
′
+
p
2
l
1
′
+
.
.
.
+
p
n
l
1
′
)
s
.
t
.
2
l
1
′
+
2
l
2
′
+
.
.
.
+
2
l
n
′
≤
1
l
i
′
≤
0
,
1
≤
i
≤
n
\begin{cases} min & -\left(p_1l^{'}_1+p_2l^{'}_1+...+p_nl^{'}_1\right)\\ s.t. & 2^{l^{'}_1}+2^{l^{'}_2}+...+2^{l^{'}_n} \leq 1 \\ & l^{'}_i \leq 0,\ \ 1\leq i \leq n \end{cases}
⎩⎪⎪⎨⎪⎪⎧mins.t.−(p1l1′+p2l1′+...+pnl1′)2l1′+2l2′+...+2ln′≤1li′≤0, 1≤i≤n
再令
I
i
=
2
l
i
′
I_i=2^{l^{'}_i}
Ii=2li′,可得:
{
m
i
n
−
(
p
1
log
2
I
1
+
p
2
log
2
I
2
+
.
.
.
p
n
log
2
I
n
)
s
.
t
.
I
1
+
I
2
+
.
.
.
+
I
n
≤
1
0
≤
I
i
,
1
≤
i
≤
n
\begin{cases} min & -\left(p_1\log_2I_1+p_2\log_2I_2+...p_n\log_2I_n\right)\\ s.t. & I_1+I_2+...+I_n\leq1\\ & 0\leq I_i,\ \ 1\leq i \leq n \end{cases}
⎩⎪⎨⎪⎧mins.t.−(p1log2I1+p2log2I2+...pnlog2In)I1+I2+...+In≤10≤Ii, 1≤i≤n
现在假设设取到最优解
{
I
1
′
,
I
2
′
,
.
.
.
,
I
n
′
}
\left\{I^{'}_1,I^{'}_2,...,I^{'}_n\right\}
{I1′,I2′,...,In′}时,上式约束条件的等号不成立,即:
I
1
′
+
I
2
′
+
.
.
.
+
I
n
′
<
1
I^{'}_1+I^{'}_2+...+I^{'}_n<1
I1′+I2′+...+In′<1,也即有:
I
1
′
+
I
2
′
+
.
.
.
+
I
n
′
+
I
x
′
=
1
,
w
h
i
l
e
I
x
′
>
0
I^{'}_1+I^{'}_2+...+I^{'}_n+I^{'}_x=1,while\ I^{'}_x>0
I1′+I2′+...+In′+Ix′=1,while Ix′>0,则可知
{
I
1
′
,
I
2
′
,
.
.
.
I
i
′
′
,
.
.
.
,
I
n
′
}
,
w
h
i
l
e
I
i
′
′
=
I
i
′
+
I
x
\left\{I^{'}_1,I^{'}_2,...I^{''}_i,...,I^{'}_n\right\},while\ I^{''}_i=I^{'}_i+I_x
{I1′,I2′,...Ii′′,...,In′},while Ii′′=Ii′+Ix,也是其中的一个解,而且显然该解比原先的解更好(使得目标函数更小)。由此可知,当取得最优解时,上式中的约束条件
I
1
+
I
2
+
.
.
.
+
I
n
≤
1
I_1+I_2+...+I_n\leq1
I1+I2+...+In≤1 一定等号成立,现将其代入表达式可以求解得到最优解。
将
I
1
+
I
2
+
.
.
.
+
I
n
=
1
⟹
I
n
=
1
−
∑
i
=
1
n
−
1
I
i
I_1+I_2+...+I_n=1 \Longrightarrow I_n=1-\sum_{i=1}^{n-1}I_i
I1+I2+...+In=1⟹In=1−∑i=1n−1Ii代入原最优化式子中,有:
{
m
i
n
−
[
p
1
log
2
I
1
+
p
2
log
2
I
2
+
.
.
.
+
p
n
−
1
log
2
I
n
−
1
+
p
n
log
2
(
1
−
∑
i
=
1
n
−
1
I
i
)
]
s
.
t
0
≤
I
i
≤
1
,
1
≤
i
≤
n
−
1
\begin{cases} min & -\left[p_1\log_2I_1+p_2\log_2I_2+...+p_{n-1}\log_2I_{n-1}+p_n\log_2\left({1-\sum_{i=1}^{n-1}I_i}\right)\right]\\ s.t & 0\leq I_i \leq 1,\ \ 1\leq i \leq n-1 \end{cases}
{mins.t−[p1log2I1+p2log2I2+...+pn−1log2In−1+pnlog2(1−∑i=1n−1Ii)]0≤Ii≤1, 1≤i≤n−1
当取最小值时,对
I
1
,
I
2
,
.
.
.
,
I
n
−
1
I_1,I_2,...,I_{n-1}
I1,I2,...,In−1求偏导则均为0,有:
{
p
1
I
1
ln
2
−
p
n
(
1
−
∑
i
=
1
n
−
1
I
i
)
ln
2
=
0
.
.
.
p
n
−
1
I
n
−
1
ln
2
−
p
n
(
1
−
∑
i
=
1
n
−
1
I
i
)
ln
2
=
0
\begin{cases} \frac{p_1}{I_1\ln 2}-\frac{p_n}{\left({1-\sum_{i=1}^{n-1}I_i}\right)\ln 2}=0 \\ ... \\ \frac{p_{n-1}}{I_{n-1}\ln 2}-\frac{p_n}{\left({1-\sum_{i=1}^{n-1}I_i}\right)\ln 2}=0 \end{cases}
⎩⎪⎪⎨⎪⎪⎧I1ln2p1−(1−∑i=1n−1Ii)ln2pn=0...In−1ln2pn−1−(1−∑i=1n−1Ii)ln2pn=0
经过化简可得:
{
p
1
(
1
−
I
1
−
.
.
.
−
I
n
−
1
)
=
p
1
I
n
=
p
n
I
1
⟹
I
1
p
1
=
I
n
p
n
.
.
.
p
n
−
1
(
1
−
I
1
−
.
.
.
−
I
n
−
1
)
=
p
n
−
1
I
n
=
p
n
I
n
−
1
⟹
I
n
−
1
p
n
−
1
=
I
n
p
n
\begin{cases} p_1\left(1-I_1-...-I_{n-1}\right)=p_1I_n=p_nI_1 \Longrightarrow \frac{I_1}{p_1}=\frac{I_n}{p_n}\\ ...\\ p_{n-1}\left(1-I_1-...-I_{n-1}\right)=p_{n-1}I_n=p_nI_{n-1} \Longrightarrow \frac{I_{n-1}}{p_{n-1}}=\frac{I_n}{p_n} \end{cases}
⎩⎪⎨⎪⎧p1(1−I1−...−In−1)=p1In=pnI1⟹p1I1=pnIn...pn−1(1−I1−...−In−1)=pn−1In=pnIn−1⟹pn−1In−1=pnIn
⟹
I
1
p
1
=
I
2
p
2
=
.
.
.
=
I
n
−
1
p
n
−
1
=
I
n
p
n
,
w
h
i
l
e
∑
i
=
1
n
I
i
=
∑
i
=
1
n
p
i
=
1
\Longrightarrow \frac{I_1}{p_1} = \frac{I_2}{p_2} = ... = \frac{I_{n-1}}{p_{n-1}} = \frac{I_n}{p_n} ,while \ \sum_{i=1}^{n}I_i=\sum_{i=1}^{n}p_i=1
⟹p1I1=p2I2=...=pn−1In−1=pnIn,while i=1∑nIi=i=1∑npi=1
即最优解为:
I
1
=
p
1
,
I
2
=
p
2
,
.
.
.
,
I
n
=
p
n
I_1=p_1,I_2=p_2,...,I_n=p_n
I1=p1,I2=p2,...,In=pn,也即
l
1
=
−
log
2
I
1
=
−
log
2
p
1
,
l
2
=
−
log
2
I
2
=
−
log
2
p
2
,
.
.
.
,
l
n
=
−
log
2
I
n
=
−
log
2
p
n
l_1=-\log_2I_1=-\log_2p_1, l_2=-\log_2I_2=-\log_2p_2,...,l_n=-\log_2I_n=-\log_2p_n
l1=−log2I1=−log2p1,l2=−log2I2=−log2p2,...,ln=−log2In=−log2pn。
代入原式,则最短的平均编码长度为:
H
(
X
)
=
∑
i
=
1
n
p
i
log
2
1
p
i
H\left(X\right)=\sum_{i=1}^{n}p_i \log_2 \frac{1}{p_i}
H(X)=∑i=1npilog2pi1,此式和信息熵的公式完全相同,上面的推导便也可看成是信息熵的一种推导过程。
最后,对于信息熵的物理意义,我们可以这样进行理解:对于一个随机变量X,其各个状态出现的概率不同,我们要对其进行编码,所求得的最短平均编码长度便为信息熵。















 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









