






PSPNet模型简介
PSPNet(Pyramid Scene Parsing Network)是一种用于图像语义分割的深度学习架构。核心思想是利用金字塔池化(Pyramid Pooling Module)模块,通过使用不同尺度的池化核对输入特征图进行池化操作,有效地获取多尺度的上下文信息。所以网络能够更全面地理解图像中的语义信息,从而提高语义分割的准确性和鲁棒性。
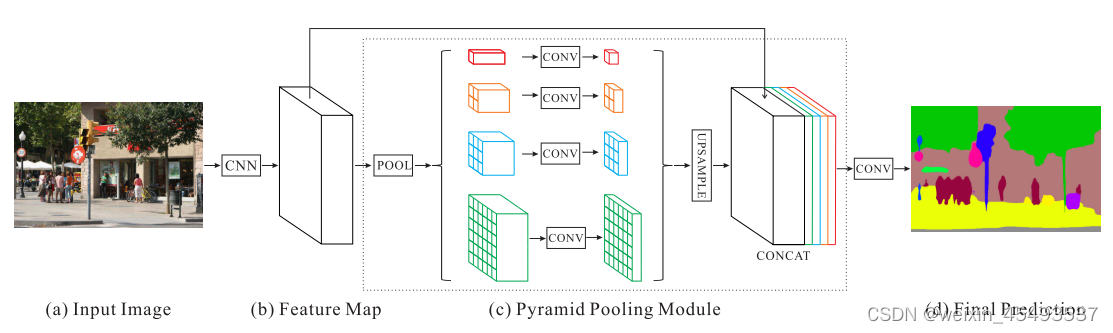
给定一个输入图像(a),我们首先使用CNN(特征提取网络)得到最后一个卷积层(b)的特征图,然后使用金字塔池化获取不同尺度的子区域表示,将不同的子区域表示通过上采样转变到统一大小,然后合并形成最终的特征表示,©中同时携带局部和全局上下文信息。最后,将表示送入卷积层,得到最终的逐像素预测(d)。
Pyramid Pooling Module介绍
金字塔池化模块融合了四种不同尺度的特征。最粗糙的级别以红色表示,进行全局平均池化以生成单个输出。其他的金字塔池化将特征图分离成不同的子区域,每个子区域内做平均池化操作。金字塔池化模块中不同级别的输出包含不同尺寸的特征图。每个金字池化之后使用1×1卷积层来减少上下文表示的维度至原始维度的1/N。这种处理方式可以在减少维度同时保持全局特征的重要信息。然后通过双线性插值直接上采样到输入特征图大小。最后,不同级别的特征被合并起来作为最终的金字塔池化全局特征。
金字塔的层级数量和每个层级的大小是可以修改的。这种结构通过采用步长内可变的池化核(nn.AdaptiveAvgPool2d())来形成不同的子区域。所以多阶段池化核应保持合理的表示差距。论文中金字塔池化模块是一个四级模块,具有1×1、2×2、3×3和6×6的不同子区域大小。
PSPNet网络结构实现
特征提取网络介绍
Bag of Tricks for Image Classification with Convolutional Neural Networks
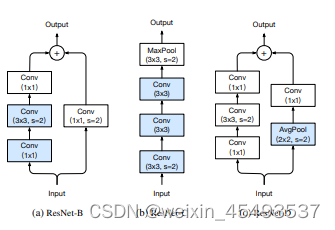
论文采用的是resnet系列作为特征提取网络,这里以resnet50为例子来进行讲解。resnet有很多改进版本,resnet50-d,因为这个版本在stem部分使用3个33卷积代替了1个77卷积,在BasicBlock中残差部分使用平均池化来下采样操作,主要是这个版本可以下载到预训练模型,在做语义分割任务中,预训练模型的重要性就不用我多说。
import torch
import torch.nn as nn
import torch.utils.checkpoint as cp
from mmcv.cnn import build_norm_layer, build_conv_layer, build_activation_layer, ConvModule, constant_init
from drop import DropPath
from mmcv.utils.parrots_wrapper import _BatchNorm
import math
eps = 1.0e-5
class BasicBlock(nn.Module):
"""BasicBlock for ResNet.
Args:
in_channels (int): Input channels of this block.
out_channels (int): Output channels of this block.
expansion (int): The ratio of ``out_channels/mid_channels`` where
``mid_channels`` is the output channels of conv1. This is a
reserved argument in BasicBlock and should always be 1. Default: 1.
stride (int): stride of the block. Default: 1
dilation (int): dilation of convolution. Default: 1
downsample (nn.Module, optional): downsample operation on identity
branch. Default: None.
style (str): `pytorch` or `caffe`. It is unused and reserved for
unified API with Bottleneck.
with_cp (bool): Use checkpoint or not. Using checkpoint will save some
memory while slowing down the training speed.
conv_cfg (dict, optional): dictionary to construct and config conv
layer. Default: None
norm_cfg (dict): dictionary to construct and config norm layer.
Default: dict(type='BN')
"""
def __init__(self,
in_channels,
out_channels,
expansion=1,
stride=1,
dilation=1,
downsample=None,
style='pytorch',
with_cp=False,
conv_cfg=None,
norm_cfg=dict(type='BN'),
drop_path_rate=0.0,
act_cfg=dict(type='ReLU', inplace=True),
init_cfg=None):
super(BasicBlock, self).__init__(init_cfg=init_cfg)
self.in_channels = in_channels
self.out_channels = out_channels
self.expansion = expansion
assert self.expansion == 1
assert out_channels % expansion == 0
self.mid_channels = out_channels // expansion
self.stride = stride
self.dilation = dilation
self.style = style
self.with_cp = with_cp
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.norm1_name, norm1 = build_norm_layer(
norm_cfg, self.mid_channels, postfix=1)
self.norm2_name, norm2 = build_norm_layer(
norm_cfg, out_channels, postfix=2)
self.conv1 = build_conv_layer(
conv_cfg,
in_channels,
self.mid_channels,
3,
stride=stride,
padding=dilation,
dilation=dilation,
bias=False)
self.add_module(self.norm1_name, norm1)
self.conv2 = build_conv_layer(
conv_cfg,
self.mid_channels,
out_channels,
3,
padding=1,
bias=False)
self.add_module(self.norm2_name, norm2)
self.relu = build_activation_layer(act_cfg)
self.downsample = downsample
self.drop_path = DropPath(drop_prob=drop_path_rate
) if drop_path_rate > eps else nn.Identity()
@property
def norm1(self):
return getattr(self, self.norm1_name)
@property
def norm2(self):
return getattr(self, self.norm2_name)
def forward(self, x):
def _inner_forward(x):
identity = x
out = self.conv1(x)
out = self.norm1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.norm2(out)
if self.downsample is not None:
identity = self.downsample(x)
out = self.drop_path(out)
out += identity
return out
if self.with_cp and x.requires_grad:
out = cp.checkpoint(_inner_forward, x)
else:
out = _inner_forward(x)
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""Bottleneck block for ResNet.
Args:
in_channels (int): Input channels of this block.
out_channels (int): Output channels of this block.
expansion (int): The ratio of ``out_channels/mid_channels`` where
``mid_channels`` is the input/output channels of conv2. Default: 4.
stride (int): stride of the block. Default: 1
dilation (int): dilation of convolution. Default: 1
downsample (nn.Module, optional): downsample operation on identity
branch. Default: None.
style (str): ``"pytorch"`` or ``"caffe"``. If set to "pytorch", the
stride-two layer is the 3x3 conv layer, otherwise the stride-two
layer is the first 1x1 conv layer. Default: "pytorch".
with_cp (bool): Use checkpoint or not. Using checkpoint will save some
memory while slowing down the training speed.
conv_cfg (dict, optional): dictionary to construct and config conv
layer. Default: None
norm_cfg (dict): dictionary to construct and config norm layer.
Default: dict(type='BN')
"""
def __init__(self,
in_channels,
out_channels,
expansion=4,
stride=1,
dilation=1,
downsample=None,
style='pytorch',
with_cp=False,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU', inplace=True),
drop_path_rate=0.0,
):
super(Bottleneck, self).__init__()
assert style in ['pytorch', 'caffe']
self.in_channels = in_channels
self.out_channels = out_channels
self.expansion = expansion
assert out_channels % expansion == 0
self.mid_channels = out_channels // expansion
self.stride = stride
self.dilation = dilation
self.style = style
self.with_cp = with_cp
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
if self.style == 'pytorch':
self.conv1_stride = 1
self.conv2_stride = stride
else:
self.conv1_stride = stride
self.conv2_stride = 1
self.norm1_name, norm1 = build_norm_layer(
norm_cfg, self.mid_channels, postfix=1)
self.norm2_name, norm2 = build_norm_layer(
norm_cfg, self.mid_channels, postfix=2)
self.norm3_name, norm3 = build_norm_layer(
norm_cfg, out_channels, postfix=3)
self.conv1 = build_conv_layer(
conv_cfg,
in_channels,
self.mid_channels,
kernel_size=1,
stride=self.conv1_stride,
bias=False)
self.add_module(self.norm1_name, norm1)
self.conv2 = build_conv_layer(
conv_cfg,
self.mid_channels,
self.mid_channels,
kernel_size=3,
stride=self.conv2_stride,
padding=dilation,
dilation=dilation,
bias=False)
self.add_module(self.norm2_name, norm2)
self.conv3 = build_conv_layer(
conv_cfg,
self.mid_channels,
out_channels,
kernel_size=1,
bias=False)
self.add_module(self.norm3_name, norm3)
self.relu = build_activation_layer(act_cfg)
self.downsample = downsample
self.drop_path = DropPath(drop_prob=drop_path_rate
) if drop_path_rate > eps else nn.Identity()
@property
def norm1(self):
return getattr(self, self.norm1_name)
@property
def norm2(self):
return getattr(self, self.norm2_name)
@property
def norm3(self):
return getattr(self, self.norm3_name)
def forward(self, x):
def _inner_forward(x):
identity = x
out = self.conv1(x)
out = self.norm1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.norm2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.norm3(out)
if self.downsample is not None:
identity = self.downsample(x)
out = self.drop_path(out)
out += identity
return out
if self.with_cp and x.requires_grad:
out = cp.checkpoint(_inner_forward, x)
else:
out = _inner_forward(x)
out = self.relu(out)
return out
def get_expansion(block, expansion=None):
"""Get the expansion of a residual block.
The block expansion will be obtained by the following order:
1. If ``expansion`` is given, just return it.
2. If ``block`` has the attribute ``expansion``, then return
``block.expansion``.
3. Return the default value according the the block type:
1 for ``BasicBlock`` and 4 for ``Bottleneck``.
Args:
block (class): The block class.
expansion (int | None): The given expansion ratio.
Returns:
int: The expansion of the block.
"""
if isinstance(expansion, int):
assert expansion > 0
elif expansion is None:
if hasattr(block, 'expansion'):
expansion = block.expansion
elif issubclass(block, BasicBlock):
expansion = 1
elif issubclass(block, Bottleneck):
expansion = 4
else:
raise TypeError(f'expansion is not specified for {block.__name__}')
else:
raise TypeError('expansion must be an integer or None')
return expansion
class ResLayer(nn.Sequential):
"""ResLayer to build ResNet style backbone.
Args:
block (nn.Module): Residual block used to build ResLayer.
num_blocks (int): Number of blocks.
in_channels (int): Input channels of this block.
out_channels (int): Output channels of this block.
expansion (int, optional): The expansion for BasicBlock/Bottleneck.
If not specified, it will firstly be obtained via
``block.expansion``. If the block has no attribute "expansion",
the following default values will be used: 1 for BasicBlock and
4 for Bottleneck. Default: None.
stride (int): stride of the first block. Default: 1.
avg_down (bool): Use AvgPool instead of stride conv when
downsampling in the bottleneck. Default: False
conv_cfg (dict, optional): dictionary to construct and config conv
layer. Default: None
norm_cfg (dict): dictionary to construct and config norm layer.
Default: dict(type='BN')
drop_path_rate (float or list): stochastic depth rate.
Default: 0.
"""
def __init__(self,
block,
num_blocks,
in_channels,
out_channels,
expansion=None,
stride=1,
avg_down=False,
conv_cfg=None,
norm_cfg=dict(type='BN'),
drop_path_rate=0.0,
**kwargs):
self.block = block
self.expansion = get_expansion(block, expansion)
if isinstance(drop_path_rate, float):
drop_path_rate = [drop_path_rate] * num_blocks
assert len(drop_path_rate
) == num_blocks, 'Please check the length of drop_path_rate'
downsample = None
if stride != 1 or in_channels != out_channels:
downsample = []
conv_stride = stride
if avg_down and stride != 1:
conv_stride = 1
downsample.append(
nn.AvgPool2d(
kernel_size=stride,
stride=stride,
ceil_mode=True,
count_include_pad=False))
downsample.extend([
build_conv_layer(
conv_cfg,
in_channels,
out_channels,
kernel_size=1,
stride=conv_stride,
bias=False),
build_norm_layer(norm_cfg, out_channels)[1]
])
downsample = nn.Sequential(*downsample)
layers = []
layers.append(
block(
in_channels=in_channels,
out_channels=out_channels,
expansion=self.expansion,
stride=stride,
downsample=downsample,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
drop_path_rate=drop_path_rate[0],
**kwargs))
in_channels = out_channels
for i in range(1, num_blocks):
layers.append(
block(
in_channels=in_channels,
out_channels=out_channels,
expansion=self.expansion,
stride=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
drop_path_rate=drop_path_rate[i],
**kwargs))
super(ResLayer, self).__init__(*layers)
class ResNet(nn.Module):
"""ResNet backbone.
Please refer to the `paper <https://arxiv.org/abs/1512.03385>`__ for
details.
Args:
depth (int): Network depth, from {18, 34, 50, 101, 152}.
in_channels (int): Number of input image channels. Default: 3.
stem_channels (int): Output channels of the stem layer. Default: 64.
base_channels (int): Middle channels of the first stage. Default: 64.
num_stages (int): Stages of the network. Default: 4.
strides (Sequence[int]): Strides of the first block of each stage.
Default: ``(1, 2, 2, 2)``.
dilations (Sequence[int]): Dilation of each stage.
Default: ``(1, 1, 1, 1)``.
out_indices (Sequence[int]): Output from which stages.
Default: ``(3, )``.
style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
layer is the 3x3 conv layer, otherwise the stride-two layer is
the first 1x1 conv layer.
deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
Default: False.
avg_down (bool): Use AvgPool instead of stride conv when
downsampling in the bottleneck. Default: False.
frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
-1 means not freezing any parameters. Default: -1.
conv_cfg (dict | None): The config dict for conv layers. Default: None.
norm_cfg (dict): The config dict for norm layers.
norm_eval (bool): Whether to set norm layers to eval mode, namely,
freeze running stats (mean and var). Note: Effect on Batch Norm
and its variants only. Default: False.
with_cp (bool): Use checkpoint or not. Using checkpoint will save some
memory while slowing down the training speed. Default: False.
zero_init_residual (bool): Whether to use zero init for last norm layer
in resblocks to let them behave as identity. Default: True.
Example:
from mmpretrain.models import ResNet
import torch
self = ResNet(depth=18)
self.eval()
inputs = torch.rand(1, 3, 32, 32)
level_outputs = self.forward(inputs)
for level_out in level_outputs:
... print(tuple(level_out.shape))
(1, 64, 8, 8)
(1, 128, 4, 4)
(1, 256, 2, 2)
(1, 512, 1, 1)
"""
arch_settings = {
18: (BasicBlock, (2, 2, 2, 2)),
34: (BasicBlock, (3, 4, 6, 3)),
50: (Bottleneck, (3, 4, 6, 3)),
101: (Bottleneck, (3, 4, 23, 3)),
152: (Bottleneck, (3, 8, 36, 3))
}
def __init__(self,
depth,
in_channels=3,
stem_channels=64,
base_channels=64,
expansion=None,
num_stages=4,
strides=(1, 2, 2, 2),
dilations=(1, 1, 1, 1),
out_indices=(3, ),
style='pytorch',
deep_stem=False,
avg_down=False,
frozen_stages=4,
conv_cfg=None,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=False,
with_cp=False,
zero_init_residual=True,
drop_path_rate=0.0):
super(ResNet, self).__init__()
if depth not in self.arch_settings:
raise KeyError(f'invalid depth {depth} for resnet')
self.depth = depth
self.stem_channels = stem_channels
self.base_channels = base_channels
self.num_stages = num_stages
assert num_stages >= 1 and num_stages <= 4
self.strides = strides
self.dilations = dilations
assert len(strides) == len(dilations) == num_stages
self.out_indices = out_indices
assert max(out_indices) < num_stages
self.style = style
self.deep_stem = deep_stem
self.avg_down = avg_down
self.frozen_stages = frozen_stages
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.with_cp = with_cp
self.norm_eval = norm_eval
self.zero_init_residual = zero_init_residual
self.block, stage_blocks = self.arch_settings[depth]
self.stage_blocks = stage_blocks[:num_stages]
self.expansion = get_expansion(self.block, expansion)
self._make_stem_layer(in_channels, stem_channels)
self.res_layers = []
_in_channels = stem_channels
_out_channels = base_channels * self.expansion
# stochastic depth decay rule
total_depth = sum(stage_blocks)
dpr = [
x.item() for x in torch.linspace(0, drop_path_rate, total_depth)
]
for i, num_blocks in enumerate(self.stage_blocks):
stride = strides[i]
dilation = dilations[i]
res_layer = self.make_res_layer(
block=self.block,
num_blocks=num_blocks,
in_channels=_in_channels,
out_channels=_out_channels,
expansion=self.expansion,
stride=stride,
dilation=dilation,
style=self.style,
avg_down=self.avg_down,
with_cp=with_cp,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
drop_path_rate=dpr[:num_blocks])
_in_channels = _out_channels
_out_channels *= 2
dpr = dpr[num_blocks:]
layer_name = f'layer{i + 1}'
self.add_module(layer_name, res_layer)
self.res_layers.append(layer_name)
self._freeze_stages()
self.feat_dim = res_layer[-1].out_channels
def make_res_layer(self, **kwargs):
return ResLayer(**kwargs)
@property
def norm1(self):
return getattr(self, self.norm1_name)
def _make_stem_layer(self, in_channels, stem_channels):
if self.deep_stem:
self.stem = nn.Sequential(
ConvModule(
in_channels,
stem_channels // 2,
kernel_size=3,
stride=2,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
inplace=True),
ConvModule(
stem_channels // 2,
stem_channels // 2,
kernel_size=3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
inplace=True),
ConvModule(
stem_channels // 2,
stem_channels,
kernel_size=3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
inplace=True))
else:
self.conv1 = build_conv_layer(
self.conv_cfg,
in_channels,
stem_channels,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.norm1_name, norm1 = build_norm_layer(
self.norm_cfg, stem_channels, postfix=1)
self.add_module(self.norm1_name, norm1)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
def _freeze_stages(self):
if self.frozen_stages >= 0:
if self.deep_stem:
self.stem.eval()
for param in self.stem.parameters():
param.requires_grad = False
else:
self.norm1.eval()
for m in [self.conv1, self.norm1]:
for param in m.parameters():
param.requires_grad = False
for i in range(1, self.frozen_stages + 1):
m = getattr(self, f'layer{i}')
m.eval()
for param in m.parameters():
param.requires_grad = False
def init_weights(self):
super(ResNet, self).init_weights()
if (isinstance(self.init_cfg, dict)
and self.init_cfg['type'] == 'Pretrained'):
# Suppress zero_init_residual if use pretrained model.
return
if self.zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
constant_init(m.norm3, 0)
elif isinstance(m, BasicBlock):
constant_init(m.norm2, 0)
def forward(self, x):
if self.deep_stem:
x = self.stem(x)
else:
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
x = self.maxpool(x)
outs = []
for i, layer_name in enumerate(self.res_layers):
res_layer = getattr(self, layer_name)
x = res_layer(x)
if i in self.out_indices:
outs.append(x)
return tuple(outs)
def train(self, mode=True):
super(ResNet, self).train(mode)
self._freeze_stages()
if mode and self.norm_eval:
for m in self.modules():
# trick: eval have effect on BatchNorm only
if isinstance(m, _BatchNorm):
m.eval()
def get_layer_depth(self, param_name: str, prefix: str = ''):
"""Get the layer id to set the different learning rates for ResNet.
ResNet stages:
50 : [3, 4, 6, 3]
101 : [3, 4, 23, 3]
152 : [3, 8, 36, 3]
200 : [3, 24, 36, 3]
eca269d: [3, 30, 48, 8]
Args:
param_name (str): The name of the parameter.
prefix (str): The prefix for the parameter.
Defaults to an empty string.
Returns:
Tuple[int, int]: The layer-wise depth and the num of layers.
"""
depths = self.stage_blocks
if depths[1] == 4 and depths[2] == 6:
blk2, blk3 = 2, 3
elif depths[1] == 4 and depths[2] == 23:
blk2, blk3 = 2, 3
elif depths[1] == 8 and depths[2] == 36:
blk2, blk3 = 4, 4
elif depths[1] == 24 and depths[2] == 36:
blk2, blk3 = 4, 4
elif depths[1] == 30 and depths[2] == 48:
blk2, blk3 = 5, 6
else:
raise NotImplementedError
N2, N3 = math.ceil(depths[1] / blk2 -
1e-5), math.ceil(depths[2] / blk3 - 1e-5)
N = 2 + N2 + N3 # r50: 2 + 2 + 2 = 6
max_layer_id = N + 1 # r50: 2 + 2 + 2 + 1(like head) = 7
if not param_name.startswith(prefix):
# For subsequent module like head
return max_layer_id, max_layer_id + 1
if param_name.startswith('backbone.layer'):
stage_id = int(param_name.split('.')[1][5:])
block_id = int(param_name.split('.')[2])
if stage_id == 1:
layer_id = 1
elif stage_id == 2:
layer_id = 2 + block_id // blk2 # r50: 2, 3
elif stage_id == 3:
layer_id = 2 + N2 + block_id // blk3 # r50: 4, 5
else: # stage_id == 4
layer_id = N # r50: 6
return layer_id, max_layer_id + 1
else:
return 0, max_layer_id + 1
class ResNetV1c(ResNet):
"""ResNetV1c backbone.
This variant is described in `Bag of Tricks.
<https://arxiv.org/pdf/1812.01187.pdf>`_.
Compared with default ResNet(ResNetV1b), ResNetV1c replaces the 7x7 conv
in the input stem with three 3x3 convs.
"""
def __init__(self, **kwargs):
super(ResNetV1c, self).__init__(
deep_stem=True, avg_down=False, **kwargs)
Bottleneck模块
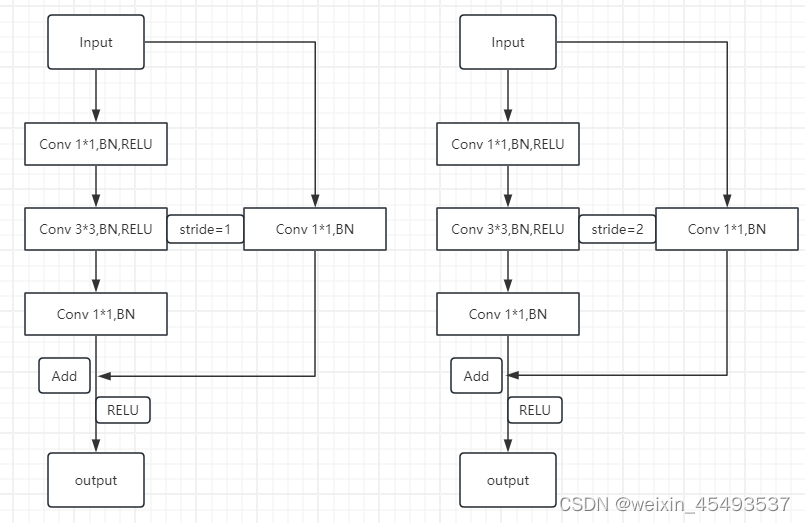
resnet50最主要的结构是Bottleneck模块,bottleneck结构图我画在下面,resnet50结构由多个layer构成,layer由多个Bottleneck模块堆叠构成,Bottleneck模块分成stride=1和stride=2。stride=1,左右两边通道数不相等时,1x1卷积会起到调整通道数的作用,当两边通道数相等时,残差就是恒等结构,不改变特征图大小。stride=2,图像下采样,残差块为了和左边对其,也需要使用1x1卷积改变通道数和下采样改变特征图大小。
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
PSPNet网络结构构建
PSPNet会将特征提取网络后两个layer(layer3,layer4)变成膨胀卷积(Dilated convolution),膨胀卷积也被称为空洞卷积或扩张卷积,它在传统卷积的基础上引入了膨胀率(dilation rate)的概念,通过在卷积核中引入间隔,实现了增大感受野的目的。传统卷积的感受野是通过卷积核的大小确定的,而膨胀卷积通过在卷积核的元素之间插入空洞,扩大了感受野,但同时减少了参数数量。这种操作可以在保持参数较少的情况下,有效地扩展卷积核的感受野,使网络能够更好地捕捉图像中的全局信息。膨胀卷积常用于语义分割任务中,以更好地处理大尺寸的输入数据。它在一定程度上缓解了卷积神经网络在处理全局信息时的局限性,提高了网络的性能。
代码中将layer3和layer4变成膨胀卷积,所以到layer2之后,特征图大小就不再改变。所以代码使用了3次下采样,当然也可以实现4次下采样,这样会减少更多的内存占用。(实现就是将layer3转变成膨胀卷积的代码注销一下)
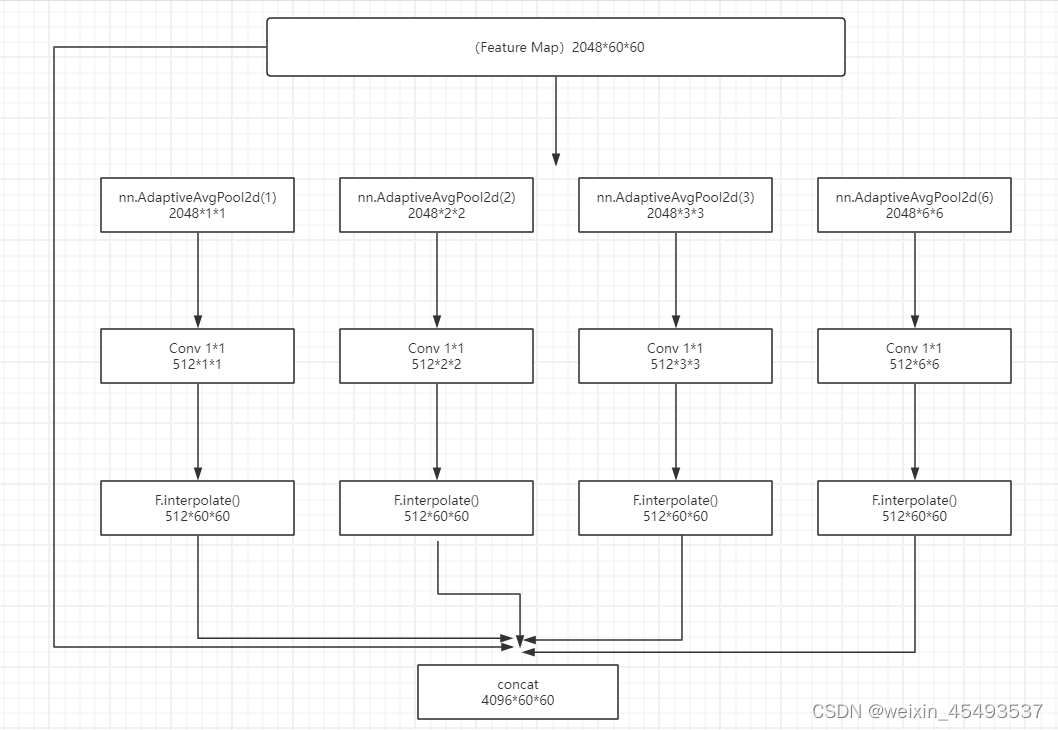
class PPM(nn.Module):
def __init__(self, in_dim, reduction_dim, bins):
super(PPM, self).__init__()
self.features = []
for bin in bins:
self.features.append(nn.Sequential(
nn.AdaptiveAvgPool2d(bin),
nn.Conv2d(in_dim, reduction_dim, kernel_size=1, bias=False),
nn.BatchNorm2d(reduction_dim),
nn.ReLU(inplace=True)
))
self.features = nn.ModuleList(self.features)
def forward(self, x):
x_size = x.size()
out = [x]
for f in self.features:
out.append(F.interpolate(f(x), x_size[2:], mode='bilinear', align_corners=True))
return torch.cat(out, 1)
PSPNet整体结构代码
import torch
from torch import nn
import torch.nn.functional as F
from model.resnetv1 import ResNetV1c
import os
class PPM(nn.Module):
def __init__(self, in_dim, reduction_dim, bins):
super(PPM, self).__init__()
self.features = []
for bin in bins:
self.features.append(nn.Sequential(
nn.AdaptiveAvgPool2d(bin),
nn.Conv2d(in_dim, reduction_dim, kernel_size=1, bias=False),
nn.BatchNorm2d(reduction_dim),
nn.ReLU(inplace=True)
))
self.features = nn.ModuleList(self.features)
def forward(self, x):
x_size = x.size()
out = [x]
for f in self.features:
out.append(F.interpolate(f(x), x_size[2:], mode='bilinear', align_corners=True))
return torch.cat(out, 1)
class PSPNet(nn.Module):
def __init__(self, layers=50, bins=(1, 2, 3, 6), dropout=0.1, classes=21, zoom_factor=8, use_ppm=True,
criterion=nn.CrossEntropyLoss(ignore_index=255), pretrained=True, deep_base=False):
super(PSPNet, self).__init__()
assert layers in [50, 101, 152]
assert 2048 % len(bins) == 0
assert classes > 1
assert zoom_factor in [1, 2, 4, 8]
self.zoom_factor = zoom_factor
self.use_ppm = use_ppm
self.criterion = criterion
weight_path_list = ["resnetv1c50_8xb32_in1k_20220214-3343eccd.pth",
"resnetv1d101_b32x8_imagenet_20210531-6e13bcd3.pth",
"resnetv1d152_b32x8_imagenet_20210531-278cf22a.pth"]
if layers == 50:
weight_path = os.path.join("/home/luocheng/CustomPSPNet/model/checkpoint", weight_path_list[0])
self.resnet = ResNetV1c(depth=50, pretrained=True, weight_path=weight_path)
elif layers == 101:
weight_path = os.path.join("./checkpoint", weight_path_list[1])
self.resnet = ResNetV1c(depth=101, pretrained=True, weight_path=weight_path)
else:
weight_path = os.path.join("./checkpoint", weight_path_list[2])
self.resnet = ResNetV1c(depth=152, pretrained=True, weight_path=weight_path)
for n, m in self.resnet.backbone.layer3.named_modules():
if 'conv2' in n:
m.dilation, m.padding, m.stride = (2, 2), (2, 2), (1, 1)
elif 'downsample.0' in n:
m.stride = (1, 1)
for n, m in self.resnet.backbone.layer4.named_modules():
if 'conv2' in n:
m.dilation, m.padding, m.stride = (4, 4), (4, 4), (1, 1)
elif 'downsample.0' in n:
m.stride = (1, 1)
fea_dim = self.resnet.feat_dim
if use_ppm:
self.ppm = PPM(fea_dim, int(fea_dim/len(bins)), bins)
fea_dim *= 2
self.cls = nn.Sequential(
nn.Conv2d(fea_dim, 512, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout2d(p=dropout),
nn.Conv2d(512, classes, kernel_size=1)
)
if self.training:
self.aux = nn.Sequential(
nn.Conv2d(1024, 256, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout2d(p=dropout),
nn.Conv2d(256, classes, kernel_size=1)
)
def forward(self, x):
x_size = x.size()[-2:]
x_tmp, x = self.resnet(x)
if self.use_ppm:
x = self.ppm(x)
x = self.cls(x)
x = F.interpolate(x, size=x_size, mode='bilinear', align_corners=True)
if self.training:
aux = self.aux(x_tmp)
aux = F.interpolate(aux, size=x_size, mode='bilinear', align_corners=True)
return x, aux
else:
return x
Pyramid Pooling Module实现
PPM模块将特征图划分为不同大小的子区域(bins),bin 分为 {1 × 1, 2 ×2, 3 × 3, 6 × 6}等不同大小。论文中还论证了在全局平均池化之后(平均池化和最大池化也是作者通过实验验证得出的)需要通过一个1*1的卷积来减小通道数为原来的1/N,这样效果更好。
后期我会将整体可以实际使用的代码上传到github上!!!!!!














 5546
5546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









