







1. 在所有其他参数保持不变的情况下,更改超参数num_hiddens的值,并查看此超参数的变化对结果有何影响。确定此超参数的最佳值。
通过改变隐藏层的数量,导致就是函数拟合复杂度下降,隐藏层过多可能导致过拟合,而过少导致欠拟合。
我们将层数改为128可得:
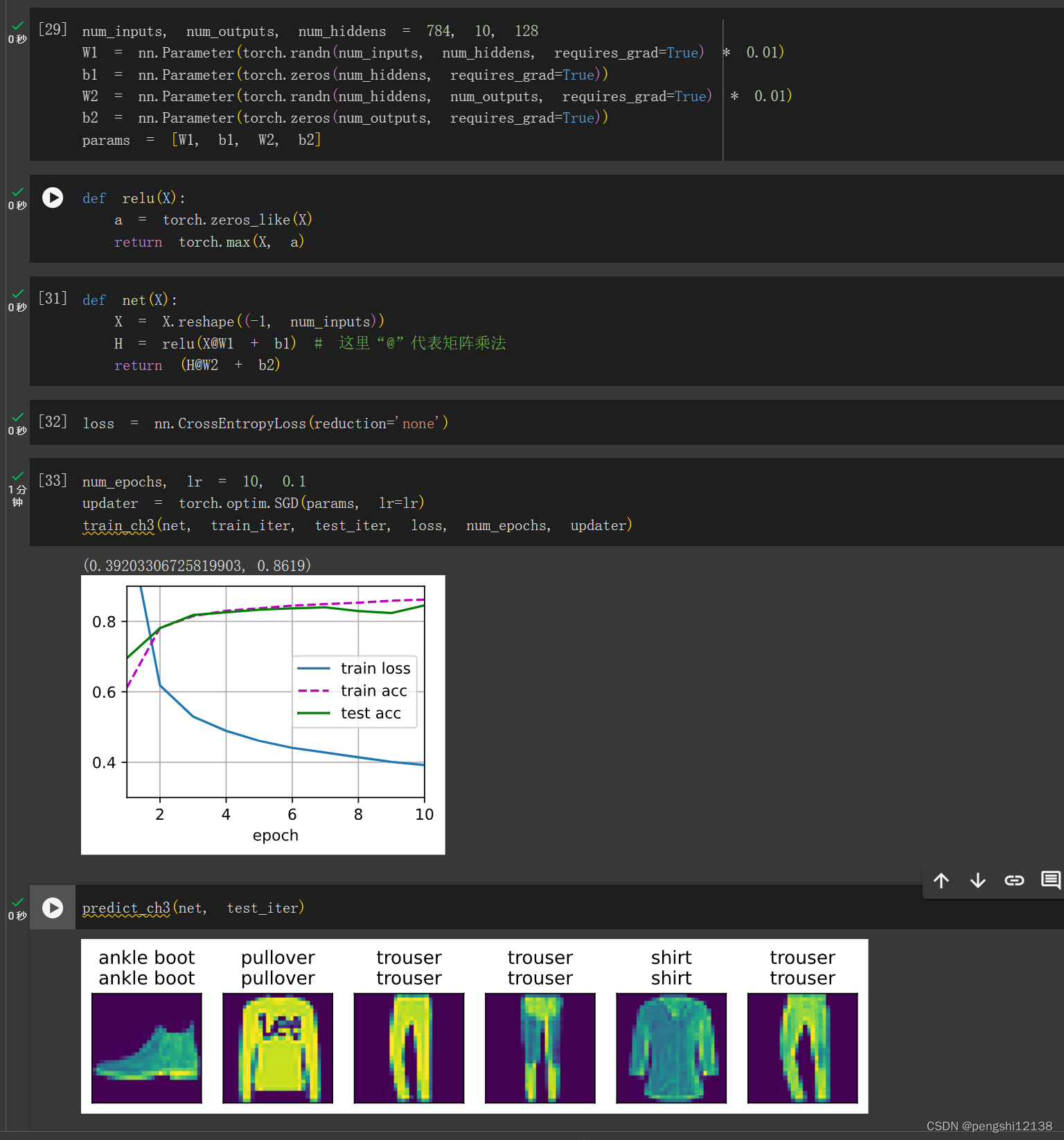
2. 尝试添加更多的隐藏层,并查看它对结果有何影响。
过拟合,导致测试机精确度下降。
3. 改变学习速率会如何影响结果?保持模型架构和其他超参数(包括轮数)不变,学习率设置为多少会带来最好的结果?
过高的学习率导致,梯度跨度过大,使得降低不到对应的驻点。
过低的学习率导致训练缓慢,需要增加epoch。
在训练轮数不变的情况下,我们可以通过for 设置不同的学习率找出最合适的学习率。一般来说设置为0.01或者0.1足以
4. 通过对所有超参数(学习率、轮数、隐藏层数、每层的隐藏单元数)进行联合优化,可以得到的最佳结果是什么?
跑了一次学习率lr=0.01的情况:
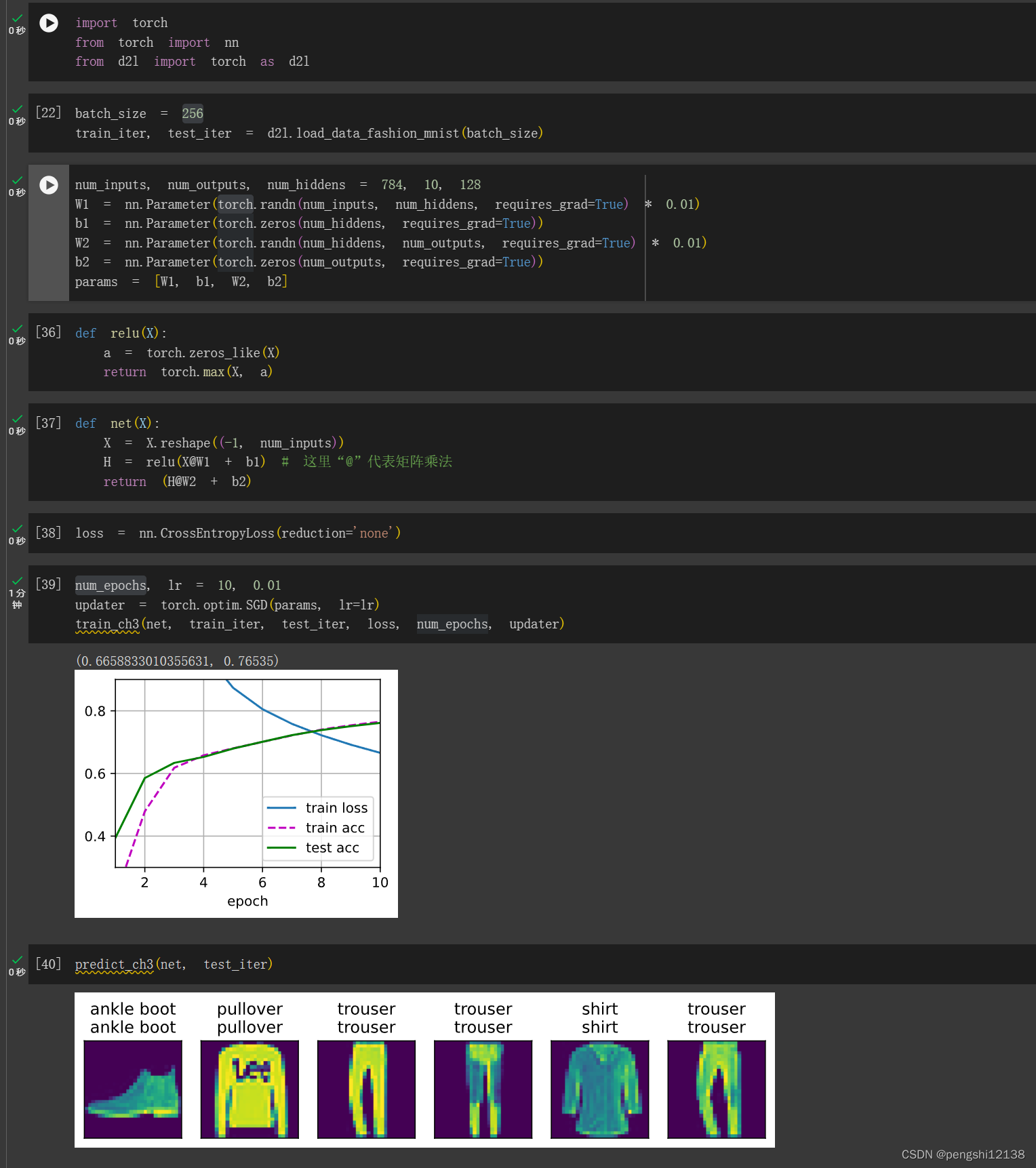
需要大量的训练,但是目前我训练结果是学习率lr=0.1、轮数是num_epochs=10,隐藏层数为1,隐藏层数单元num_hiddens=128。
5. 描述为什么涉及多个超参数更具挑战性。
因为组合的情况更多,当层数越多时,训练时间也更多,这玩意就是炼丹了,看你自己的GPU还有时间、运气。
6. 如果想要构建多个超参数的搜索方法,请想出一个聪明的策略。
套用for 循环暴力破解,时间上肯定慢的要死,我们可以先固定其他变量,挑选一个变量寻找最优解,以此类推对所有的超参数这样使用,但是这种做法肯定不是最优的,只是能够较好的找出比较好的超参数。
由于学校穷逼所以没有闲置GPU服务器,所有的模型只能在colab上进行运行,其中遇到了d2l的版本对应问题,所以对于d2l.train_ch3跑不起来,只能使用自写进行替代如下:
import torch.nn
from d2l import torch as d2l
from IPython import display
class Accumulator:
"""
在n个变量上累加
"""
def __init__(self, n):
self.data = [0.0] * n # 创建一个长度为 n 的列表,初始化所有元素为0.0。
def add(self, *args): # 累加
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self): # 重置累加器的状态,将所有元素重置为0.0
self.data = [0.0] * len(self.data)
def __getitem__(self, idx): # 获取所有数据
return self.data[idx]
def accuracy(y_hat, y):
"""
计算正确的数量
:param y_hat:
:param y:
:return:
"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1) # 在每行中找到最大值的索引,以确定每个样本的预测类别
cmp = y_hat.type(y.dtype 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2144
2144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











