







 TCP中的紧急数据(UrgentData)用于标记重要数据,当URG标志位为1时,UrgentPointer指示数据中的紧急字节。然而,RFC793与RFC1122在紧急数据定义上存在争议,导致实现中通常认为紧急数据仅1个字节。接收方紧急数据以紧急提交模式提交,直接传递给应用层,而发送方紧急数据处理不采用“插队”方式,可能存在紧急数据被后续数据替代的问题。PUSH标志则可以由用户或TCP设置,推动数据尽快提交。紧急数据和PUSH标志在TCP中的行为和使用场景有所不同。
TCP中的紧急数据(UrgentData)用于标记重要数据,当URG标志位为1时,UrgentPointer指示数据中的紧急字节。然而,RFC793与RFC1122在紧急数据定义上存在争议,导致实现中通常认为紧急数据仅1个字节。接收方紧急数据以紧急提交模式提交,直接传递给应用层,而发送方紧急数据处理不采用“插队”方式,可能存在紧急数据被后续数据替代的问题。PUSH标志则可以由用户或TCP设置,推动数据尽快提交。紧急数据和PUSH标志在TCP中的行为和使用场景有所不同。
1 Urgent(紧急数据)
紧急数据(Urgent Data),TCP 有时候也简称 Urgent。Urgent 在 TCP 里面的定义是什么,如下图5-97所示:
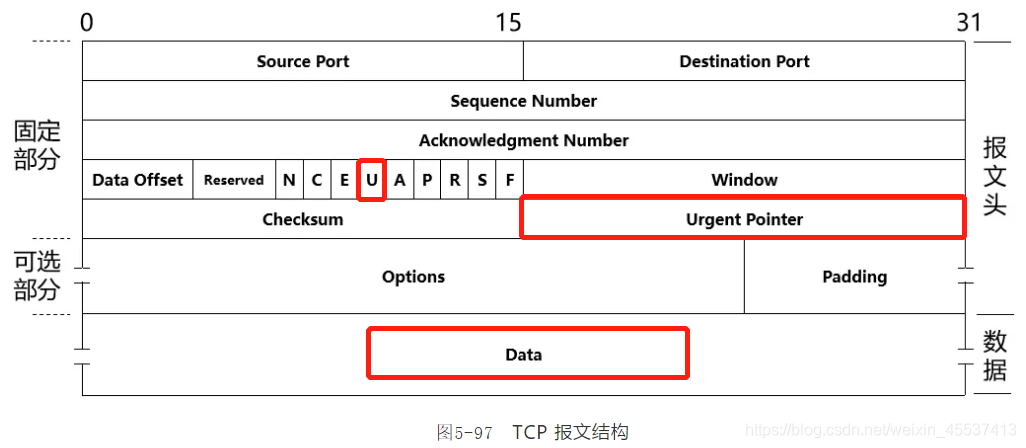
Urgent 在 TCP 中的定义,对应上图5-97中的3个字段:
- (1)Urgent 标签,简称 URG,也就是上图5-97中的“U”,占位1个 bit。当 URG = 1 时,后面的两个字段才有意义。也就是说,URG = 1 时,这3个字段才能联合表达 TCP 的 Urgent 的含义,否则 TCP 认为 It’s not Urgent(不紧急)!
- (2)Urgent Pointer,占位 16 bits,它是一个无符号整数,指示数据字段(图5-97中的 Data)中哪个(些)数据是紧急数据。当然,只有 URG = 1 时,Urgent Window 这个字段才有意义。
- (3)Data,TCP 报文中所包含的数据部分。当 URG = 1 时,这部分数据中有1个(或多个)字节的数据代表是紧急数据,而这个(些)紧急数据由 Urgent Pointer 指定。
紧急数据的分歧对于RFC793和RFC1122都说法不一,如下图所示:
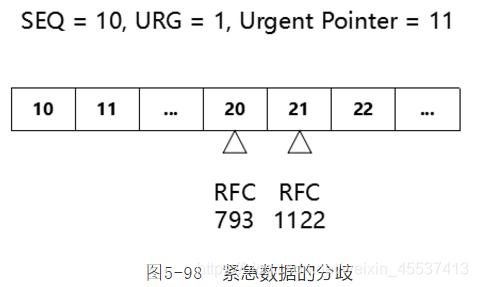
如上图所示,RFC1122认为:紧急数据序列号=SEQ+Urgent Pointer,RFC793则认为:紧急数据序列号=SEQ+Urgent Pointer-1。实际上 RFC 793 是错误的,RFC 1122 是正确的,它对 RFC 793 做了修订。无论是 RFC 793 还是 RFC 1122 都认为两点:(1)紧急数据不止1个字节;(2)紧急数据的最后一个字节由 Urgent Pointer 指定(如前文所述:RFC 793 的指定方法有点问题,RFC 1122 对其做了修正)。但是,TCP 的数据结构(报文头)中,只有1个字段 Urgent Pointer 指定了紧急数据的结尾,却再也没有其他字段以能指定紧急数据的起始位置或者长度(通过长度能间接推导出起始位置)。
面对这种模糊,一般有两种方案:
- 第1种方案是认为该报文中,从第1个字节开始,到 Urgent Pointer 结束,这段数据通通都是紧急数据;
- 第2种方案则不再纠结,根本不在意 RFC 是这么说的,就是认为紧急数据只有1个字节;
业界普遍采用第2种方案,比如著名的 Linux 就是采用第2种方案。本文遵从 Linux,也采用第2种方案。下面我们对 Urgent 的定义做一个简单的总结吧:
- (1)URG = 1,紧急数据才有意义,否则报文中的数据没有紧急数据;
- (2)紧急数据只有1个字节。当 URG = 1 时,紧急数据位于报文中的数据的序号 = SEQ + Urgent Pointer。
1.1 紧急数据在接收方的行为
紧急数据在接收方的行为,指的是 TCP 接收方收到包含紧急数据的报文后,它该如何将这个报文中的数据提交给应用层,如图5-101所示:
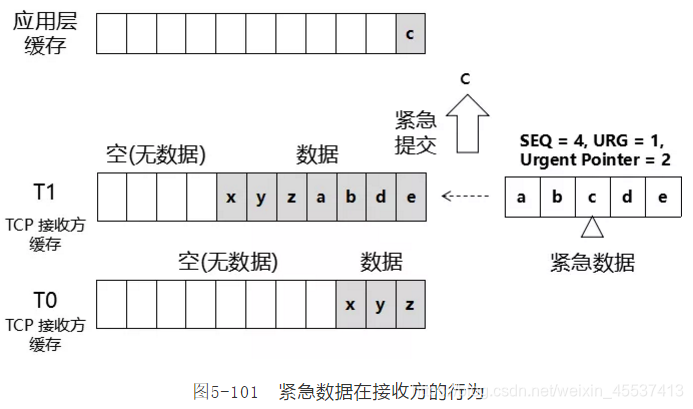
上图5-101中,我们假设 TCP 采用满泻提交模式(即使采用直流提交模式,TCP 对于紧急数据的提交方式也是一样的)。
T0时刻,接收方缓存中有数据“xyz”。T1时刻,接收方收到了“abcde”,其中“c”是紧急数据。此时接收方处理紧急数据的方案是:
- (1)抢在其他所有数据之前(抢在本次接收的普通数据“abde”之前,也抢在已经存入接收缓存的普通数据“xyz”之前),提交给应用层
- (2)而且是在第一时间提交,毫无停顿。
- (3)更进一步,紧急数据(“c”)根本不会经过接收方缓存,而是直接提交给应用层。
- (4)在紧急提交了紧急数据以后,对于本次接收的其他非紧急数据(“abde”),接收方按照正常流程处理:或者是满泻提交、或者是直流提交。
我们将(1)~(3)步骤所描述的提交方式称为紧急提交模式。
1.2 紧急数据在发送方的行为
在 TCP 的官方表达中,其把紧急数据称为带外数据(out-of-band,OOB),但是实际上TCP 的数据发送,根本就没有什么所谓的带外数据发送。带外数据指的是发送采用与普通数据不一样的(逻辑)通道。而 TCP 发送紧急数据与普通数据,采用的是同一个通道。
紧急数据在 TCP 的接收方的提交模式用大白话说,就是“插队”。而在发送方时,紧急数据则不是按“插队”的方式来进行发送处理的,而是按部就班的进行处理。抽象地讲,紧急数据的应用场景是:如果发送客户端程序由于一些原因需要取消已经写入服务器的请求,那么它就需要向服务器紧急发送一个标识取消的请求。使用紧急数据的实际程序例子有telnet、rlogin、ftp 等命令。前两个程序(telnet和rlogin)会将中止字符作为紧急数据发送到远程端。这会允许远程端冲洗所有未处理的输入,并且丢弃所有未发送的终端输出。这会快速中断一个向客户端屏幕发送大量数据的运行进程。ftp命令也会使用紧急数据来中断一个文件的传输。
之前介绍PUSH标签时说过其标签既可以由用户打上,也可以由TCP端打上。而URG 标签,只能由用户主动打上。也就是说,紧急数据只能由用户标识,TCP 不会自动标识某个数据是紧急数据。假设用户调用 TCP 接口发送一串字符:SEND(“abcdefgh”,URG = 1)。根据前文描述我们知道,TCP 的具体实现(比如 linux)仅仅认为紧急数据只有1个字节,所以用户如果调用了上述接口,TCP 会认为只有最后1个字符“h”是紧急数据。考虑一个极端一点的情况,假设滑动窗口的大小等于3,那么 TCP 会将“abcdefgh”分割成3个报文发送。这3个报文的 URG 标签即 Urgent Pointer如下图:

由上图可以看到,前两个报文的URG标签都被打上了,而且 Urgent Pointer 指向了未来。只有报文3算是真正完成了紧急数据的发送。出现这种每次都有URG标签得报文的原因,在于RFC定义了紧急数据的结尾,但没有定义紧急数据的开始/长度,使得TCP的实现者无所适从,要么认为其中一个字节为紧急数据,要么认为从第一个字节到 Urgent Pointer 所指定的字节这个区间全是紧急数据。TCP 的这种问题,忍一忍也能过去:得罪了 RFC,那就不伺候了,就认为只有1个字节是紧急数据;多发了几个无关的紧急报文(图5-104所描述的情形),那就多发了,唉咋地咋地。但是,TCP 还可能将紧急数据给发错了。如下图:
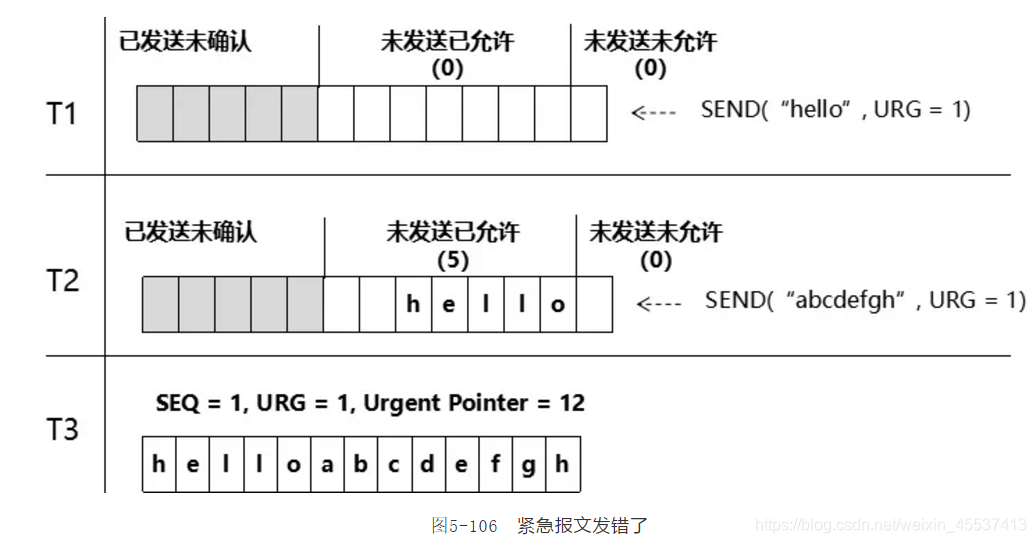
TCP 实际上是接纳了两个紧急数据发送的任务,t1与t2时刻都在攒大包,在 T3 时刻却用1个报文给发出去了,正如上图5-106所示,这个报文的 SEQ = 1、URG = 1、Urgent Pointer = 12,也就是说仅仅是“h”是紧急数据,而“o”变成了普通数据(非紧急数据)。也就是 TCP 在紧急数据发送层面的一个问题:如果上一个紧急数据还没发送,有可能会被下一个紧急数据给“冲刷/替代”掉_——而且用户并不知道他的紧急数据何时能被正确发送,何时会被“冲刷/替代”。
总结一下Urgent 有多少让人迷惑的点吧:
- (1)Urgent Pointer 关于紧急数据的指示,RFC 793 定义错了,RFC 1122 给纠正了过来,但是这中间经历了8年,混乱的种子就此埋下;
- (2)RFC 一方面信誓旦旦地说“紧急数据是一串数据”,但是它只定义了紧急数据的结尾指示(Urgent Pointer),却没有定义紧急数据的起始位置,造成了具体实现者无所适从,最后绝大部分实现者只能选择“紧急数据其实就是1个字节”;
- (3)TCP 所发送的报文中,可能是 URG = 1,但是该报文并不包含紧急数据;
- (4)如果上一个紧急数据还没发送,有可能会被下一个紧急数据给“冲刷/替代”掉——而且用户并不知道他的紧急数据何时能被正确发送,何时会被“冲刷/替代”;
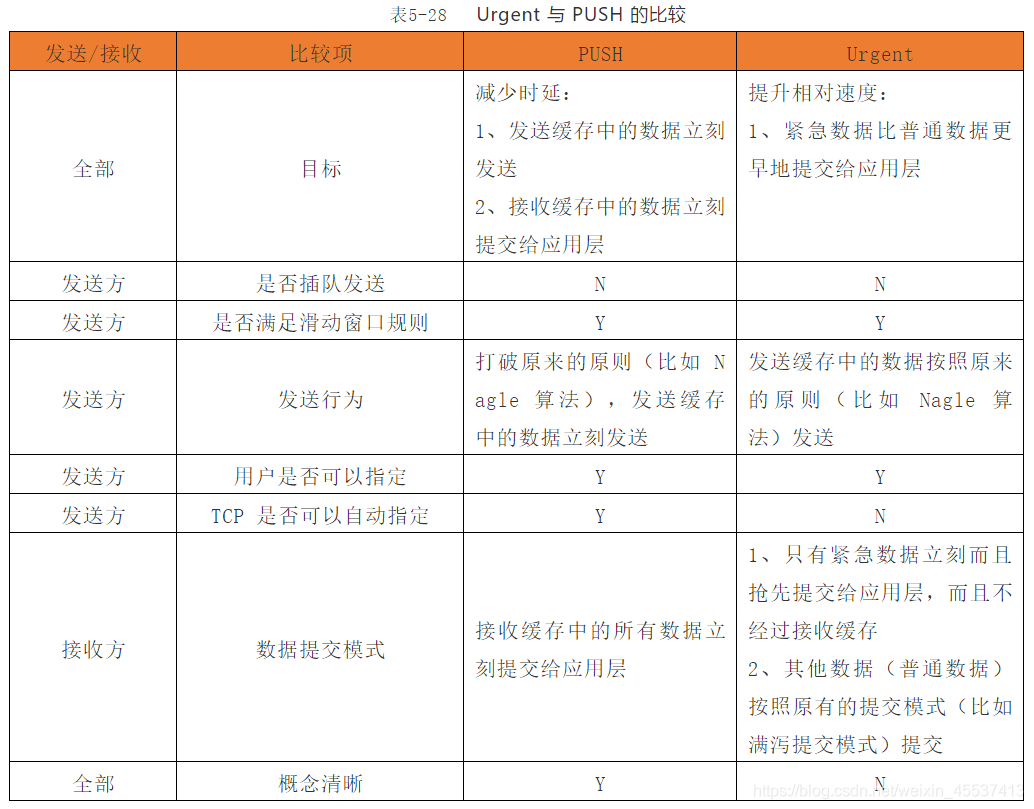
1.3 Urgent 与 PUSH 的比较
通过一张表来表达:

















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









