







 本文探讨了数据清洗的关键步骤,包括数据预处理、异常样本处理、采样和缺失值处理,强调了处理数据不平衡问题的多种解决方案。此外,介绍了特征选择的方法,如过滤法、包装法和嵌入法,以及降维技术,如主成分分析(PCA)和线性判别分析(LDA)。特征选择和降维是提升模型效率和性能的重要环节。
本文探讨了数据清洗的关键步骤,包括数据预处理、异常样本处理、采样和缺失值处理,强调了处理数据不平衡问题的多种解决方案。此外,介绍了特征选择的方法,如过滤法、包装法和嵌入法,以及降维技术,如主成分分析(PCA)和线性判别分析(LDA)。特征选择和降维是提升模型效率和性能的重要环节。
数据清洗和特征选择
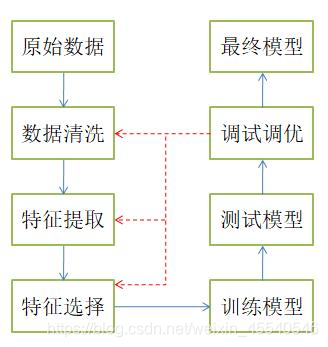
数据清洗
清洗过程
1、数据预处理:
选择数据处理工具: 数据库、Python相应的包;
查看数据的元数据及数据特征;
2、清理异常样本数据:
处理格式或者内容错误的数据;
处理逻辑错误数据:数据去重,去除/替换不合理的值,去除/重构不可靠的字段值;
处理不需要的数据:在进行该过程时,要注意备份原始数据;
处理关联性验证错误的数据:常应用于多数据源合并的过程中。
3、采样:
数据不均衡处理:上采样、下采样、SMOTE算法
样本的权重问题
数据不平衡
在实际应用中,数据的分布往往是不均匀的,会出现"长尾现象",即绝大多数的数据在一个范围/属于一个类别,而在另外一个范围或者类别中,只有很少一部分数据。此时直接采用机器学习效果不会很好,因此需要对数据进行转换操作。

解决方案01
设置损失函数的权重,使得少数类别数据判断错误的损失大于多数类别数据判断错误的损失,即:当我们的少数类别数据预测错误的时候,会产生一个比较大的损失值,从而导致模型参数往让少数类别数据预测准确的方向偏。
可通过设置sklearn中的class_weight参数来设置权重。
解决方案02
下采样/欠采样(under sampling):从多数类中随机抽取样本从而减少多数类别样本数据,使数据达到平衡的方式。
集成下采样/欠采样:采用普通的下采样方式会导致信息丢失,所以一般采用集成学习和下采样结合的方式来解决问题,主要有以下两种方式:
EasyEnsemble**:**采用不放回的数据抽取方式抽取多数类别样本数据,然后将抽取出来的数据和少数类别数据组合训练一个模型;进行多次操作,构建多个模型,然后使用多个模型共同决策/预测。
**BalanceCascade:**利用Boosting增量思想来训练模型;先通过下采样产生训练数据,然后使用Adaboost算法训练一个分类器,使用训练好的分类器对所有的样本数据进行预测,并将预测正确的样本从大众样本中删除;重复迭代上述两操作,直到大众样本数据量等于小众样本数据量。
解决方案03
Edited Nearest Neighbor(ENN):对于多数类别样本数据而言,如果这个样本的大部分k近邻样本都和自身类别不一样,那么就将其删除,然后使用删除后的数据进行模型训练。
Repeated Edited Nearest Neighbor(RENN):重复上述ENN的步骤,直到数据集无法再被删除后,使用此时的数据集进行模型训练。
解决方案04
Tomek Link Removal:如果两个不同的类别,它们的最近邻都是对方,即A的最近邻是B,B的最近邻是A,那么A和B就是Tomek Link。将所有Tom
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









