






一些符号:
θ
t
\theta _{t}
θt:模型参数:时间步长
▽
L
(
θ
t
)
\bigtriangledown L(\theta _{t})
▽L(θt)或者
g
t
g _{t}
gt:
θ
t
\theta _{t}
θt的梯度,用于计算
θ
t
+
1
\theta _{t+1}
θt+1
m
t
+
1
m_{t+1}
mt+1:动量从0到t累积,用于计算
θ
t
+
1
\theta _{t+1}
θt+1,记录前面时刻的梯度
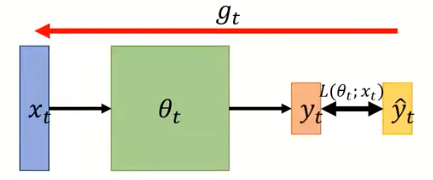
如上图所示:
x
t
x_{t}
xt:输入
θ
t
\theta _{t}
θt:时刻t的模型参数
y
t
y_{t}
yt:输出
y
^
t
\hat{y}_{t}^{}
y^t:输出对应的标签
L
(
θ
t
;
x
t
)
L(\theta _{t};x_{t})
L(θt;xt):输出值与标签所得出的损失值
优化的意义:
找到θ,使得
s
u
m
x
L
(
θ
;
x
)
sum_{x}L(\theta;x)
sumxL(θ;x)取得最小
几个常见的优化算法:
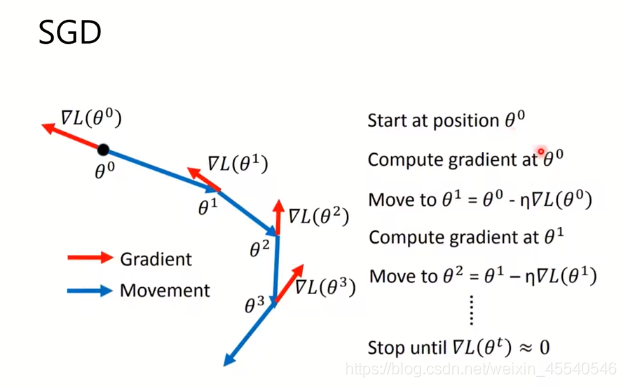
随机梯度下降:
带动量的梯度下降:
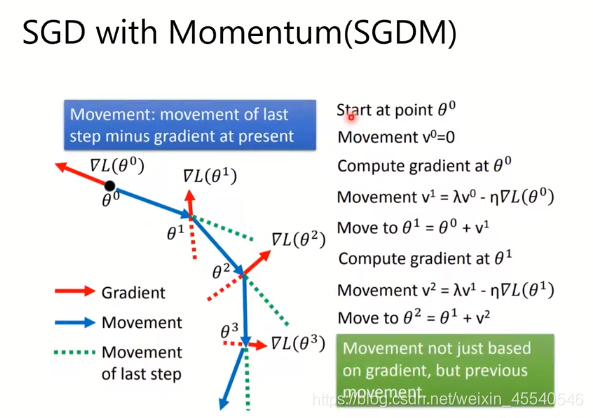
结果不只取决于当前梯度,还与之前的值有关系。

如上图所示,如果简单的使用梯度下降,在
∂
L
∂
w
=
0
\frac{\partial L}{\partial w} = 0
∂w∂L=0处,就不会再继续移动,但是,当使用有动量的随机梯度下降,会受动量的影响,继续移动。
Adagrad
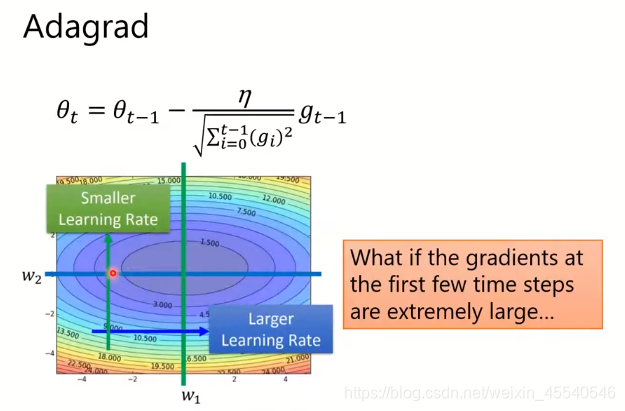
如图所示Adagrad的η,加上了一个分母,为了防止前几个时间点的梯度过大,出现梯度爆炸的情况,反而得到更差的结果。
RMSProp

RMSProp是Adagrad的改进,最大的区别是分母部分,不会无止境的增加。
Adam
Adam综合了SGDM算法和RMSProp算法:
















 2004
2004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









