







玩过数据挖掘竞赛的同学应该听过stacking这种“大杀器”,它不是算法,而是一种模型的集成框架,通过集多个模型的长处来产生更好的结果。番茄风控将会在文章中介绍stacking的原理结构以及其在实际工作中的应用,并且会跟大家介绍相关的数据集来实操演示如何搭建一个基本的stacking框架。本次内容,干货十足,我们将会分成上下两部分别跟各位同学介绍这个内容。
本次总体内容,分享大纲如下:
Part1. stacking的原理及框架结构
Part2. stacking在实际工作中的使用分享
Part3. 实操演示搭建stacking框架
Part4. Stacking效果展示
好了,废话不多说,今天我们来手撕Stacking算法。
Part1. stacking的原理及框架结构
做stacking的目的是为了提升模型的预测效果,大家都知道,数据内部的空间结构和数据之间的关系是十分复杂的,而不同的算法对于挖掘数据关系的侧重点不一样:例如KNN关注样本之间的距离关系,决策树则更关注特征分裂前后样本的不纯度变化。
既然不同的算法观测数据的角度不同,那把它们都结合一下,相互取长补短,那对数据的挖掘能更加全面,预测结果能更好。stacking就是基于这个方法的一种集成策略。
stacking既然是对多个不同算法模型的融合,那它的搭建流程简单来说就两步,第一步做多个不同的模型,第二步用一种方法将它们的模型结果进行融合来输出最后的结果,相当于做两层结构。下面通过底下这张图来具体讲下它的运行过程:
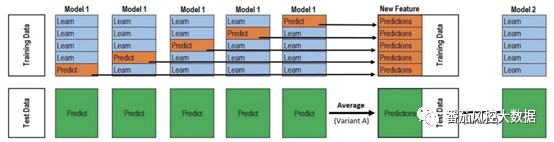
首先我们有一份数据集,把它拆分成训练集(train)和测试集(test),另外我们要选择多种算法来做第一层结构的基模型,例如常用的xgboost,RandomForest,lightgbm,GBDT,LR,SVM等。
然后进行如下操作:
1)选择第一个基模型,将训练集分为不交叉的5份,标记为train1到train5
2)先用train5作为预测样本,将train1到train4作为训练样本建模,然后预测train5, 并保留结果,然后将train4作为预测样本,用train1,2,3,5来建模,预测train4,如此操作下去,直到把train1到train5都预测一遍,train1到train5的预测结果合并在一块就是训练集在基模型上的stacking转换,相当于一个新的特征。
3)在第二步中相当于建立了5个模型,这5个模型分别对测试集做预测,产生5个预测结果,然后将这5个结果取平均值,来作为测试集在基模型上的stacking转换。
4)选择第二个基模型,重复2-3的步骤,得到整个数据集在第二个基模型上的stacking
转换。这样的话有几个基模型就会生成几个新的特征。
5)上述1-4的步骤就是框架的第一层,第二层就是对新生成的特征再用一种算法进行训练预测,一般使用LR做第二层的模型,这样相当于对多个基模型做了融合。
从上述流程中可以看出stacking结果好坏取决于第一层框架,各个基模型要保证自身的效果要好。并且因为每个模型所用的数据和特征是一样的,那做第二层融合时可能就会出现过拟合,所以基模型不仅要效果好,之间的差异化也要大,追求“准而不同”,为了解决stacking的过拟合问题,第二层也倾向用LR这种简单的算法,另外在第一层中用了交叉验证来构造新特征,也可以有效避免过拟合。
Part2. stacking在实际工作中的使用分享
本次我们开发实操介绍stacking算法,借鉴了我们以往的项目基于支付信用分项目,借鉴了stacking这种框架思想,为大家详细讲解这个代码。
这个项目用到的是电商消费类和支付行为类的数据,这类数据由于是弱金融属性,在构建信贷预测模型时遇到的最大问题就是很多特征都是弱特征,我们先用LR做单模型,效果很差,再用xgboost做效果也不是很好,所以想到了用stacking这种方法来尽量提升模型的预测能力。
具体实现流程包括三个部分:线下stacking模型开发,线上stacking部署,后期模型监控。
1.线下stacking模型开发步骤:
1)设计模型框架,第一层用xgboost构建多个子模型,第二层用LR对子模型做融合。相比于传统stacking的不同之处是,第一层只用xgboost,而不是多种算法,另外传统stacking 中每个子模型用的特征都是一样的,但这里子模型之间用到的特征不同,所以子模型间的差异不是在算法上,而是特征上。
2)对特征进行分类,从特征背后的业务含义出发,将反映用户消费能力的特征归为一类,反映用户消费偏好的归为一类,每类特征单独做子模型,这样不仅可以让子模型之间做到差异化,也能提高子模型的业务可解释性。
3)构建第一层子模型,过程跟stacking一样,用交叉验证的方法生成新的特征,并且将预测结果转换为分数,这样就得到了反映用户不同维度风险的模型分,包括消费能力分,消费偏好分,消费稳定性分,支付风险分等。
4)第二层用LR对多个子模型分进行训练,并且要检查子模型分之间的相关性,保证子模型之间尽量是相互独立的,不会对最终模型的可解释性造成影响。
5)stacking与单模型效果的对比,跟LR单模型做比较,KS提升0.05左右,而跟xgboost单模型对比,KS提升0.02左右,说明stacking在实际应用中确实能提升模型效果。
-
线上stacking模型部署
上线时需要部署两层模型,在部署第一层时遇到了一个问题,由于在构建单个子模型时使用了交叉验证,假如用了5折交叉,那生成一个子模型分是用到了5个模型,实际上线如果全部用这5个,上线的复杂度和后期维护成本太大,所以我们采取的方案是用全部的训练集(train)再生成一个模型。
如果这个模型的预测值跟5个模型的平均值相差不大,说明这个模型可以综合代表交叉验证的5个模型。第一层输出并缓存各个子模型的分数,然后第二层再用LR输出最后的模型分。由于第一层子模型数量不是特别多,整个stacking框架的线上预测时间仍可控制在预期之内。 -
后期stacking的监控
上线一段时间后,我们将stacking模型和xgboost单模型做了稳定性和效果的对比,在稳定性方面,由于stacking内部结构更加复杂,所以相比单模型会稍差一些,所以在后期模型迭代中,着重对每个子模型做了调优来保证第二层模型的稳定性。从线上效果来看,stacking模型的KS没有出现明显的下滑,且比单模型的效果要好。 -
对于stacking实际应用的一些思考总结:
1)什么场景下适合用stacking
数据量大且特征维度多,stacking不适合小的数据集。
大量特征都是比较弱的特征,就像这里提到的项目一样,其实就是用stacking将一部分弱特征合成一个强特征。
业务目的更加追求模型的预测能力,而不是可解释性。
线上平台支持这种复杂框架的部署,并且框架的运算开销在预期之内。
2)做stacking的一些注意点
第一层基模型之间一定要体现差异化,要么在算法上,要么在样本和特征上。且每个基模型的效果要好,这样集成后的模型才会更加稳健和精准。
Stacking层数不用过多,两层其实已经够了,多层的stacking会更突显过拟合问题,且带来的提升效果有限。最后一层适合用简单的线性模型。
在构建第一层时,要保证基模型的CV稳定,如果基模型在CV和test上表现差异很大,就很可能出现问题。
本文中所涉及剩余部分第三与四部分,详细敬请继续关注番茄风控!
明天晚上将给童鞋们带来更精彩的内容。
~原创文章
…
end














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









