







在数据分析任务中,尤其是建立模型的过程,我们常常会对数据进行标准化处理,期望获得较好的模型效果。当然,经过标准化处理后的特征,由于数据分布变得更为均匀,往往是对模型的拟合是有利的。但是,很多童鞋仅仅认为特征标准化是建模过程一个重要环节而直接采用,并没有去真正理解为什么要标准化,或者什么时候需要特征标准化,以及特征标准化适用于什么场景。这些问题才是我们合理利用特征标准化的前提,也是必须掌握好的一项数据理解与分析能力。当明白了特征数据标准化的原理逻辑与应用思路,才能在实际场景中有针对性地使用特征标准化的算法功能。
本文围绕以上实际问题,将给大家介绍下特征标准化的常见方法与实现过程,以及不同应用场景的对比分析等内容。
1、特征标准化背景
在场景化建模时,我们往往会对样本数据进行简单探索,发现样本各个维度特征的数据分布差异较大是很常见的现象。举个实际数据样例如图1所示,通过简单的描述性统计分析,很容易获取各特征变量的取值范围分别为:年龄(2060)、月收入(300012000)、消费等级(1~6)。从数据分布看,三个特征的取值分布存在比较大的差异。
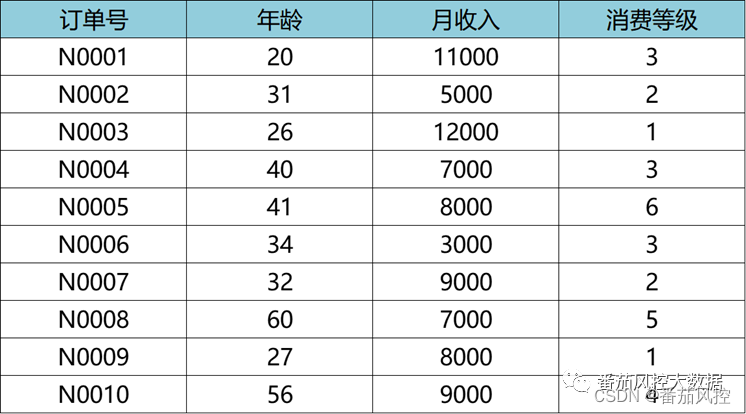
图1原始数据样例
假设我们根据这份样本数据实现业务上的客户画像分群,采用无监督聚类分析算法K-means对样本点距离进行计算时,得到样本N0001与N0002的欧式距离d如下所示:
从以上公式可知,最终距离结果6000.01基本由变量“月收入”距离(6000)决定,而变量“年龄”与“消费等级”在符合客观事实情况下,取值再如何发生变化,对模型距离结果的影响仍然很小。从这里可以看出,针对当前数据进行聚类模型拟合时,各变量存在非常明显的权重差异,而这种差异显然是不符合实际情况的。此时,若将各变量进行标准化处理,可以有效去除数据分布的权重差异,即各字段的量纲保持一致,这样算出的样本点距离才满足算法逻辑与业务解释。特征标准化后的样本数据如图2所示。

图2 标准化数据样例
此时得到样本N0001与N0002的欧式距离d如下所示,这样就有效保证了各特征变量在数据分布上具有相同权重的影响。
以上样例仅仅是举个小案例说明特征标准化的重要性,其实在很多场景下特征标准化发挥着很重要的作用。简单概括下,当建模原始样本数据中各维度特征的分布范围存在较大差异时,若直接采用原始数据进行模型训练,会增强数值尺度较大特征对模型的影响程度,削弱甚至忽略数值尺度较小特征的作用。因此,为了较大程度降低特征在不同取值尺度方面的干扰,保证模型训练拟合过程的有效性,需要对原始样本数据的特征变量进行标准化处理,从而使各维度特征对模型目标函数有相同权重的影响。特征标准化处理除了可以提高模型训练的合理性,而且可以有效加快模型拟合的速度。
2、特征标准化方法
通过以上内容,我们基本理解了特征标准化的原理逻辑与应用思路,那么接下来我们重点介绍下在实际场景中,特征标准化有哪些常使用的方法。在具体内容介绍中,为了便于说明各标准化方法的表现形式与应用效果,我们将围绕实际案例来展开分析。
特征标准化的方法有min-max标准化、z-score标准化、mean归一化、对数归一化、中心化标准化、正则化标准化等。在实际应用中,min-max标准化与z-score标准化最为常用。因此,在以下实操部分内容,我们主要针对min-max与z-score标准化进行分析,其他方法重点介绍原理逻辑以及应用场景。
现有某场景案例,具体需求是通过数据搭建一个价值客户预测模型,建模样本数据共包含2000条样本和5个特征,其中“订单号”为样本主键,“价值客户”为目标变量,“年龄”、“月收入”、消费等级”均为特征X变量,部分样例如图3所示。
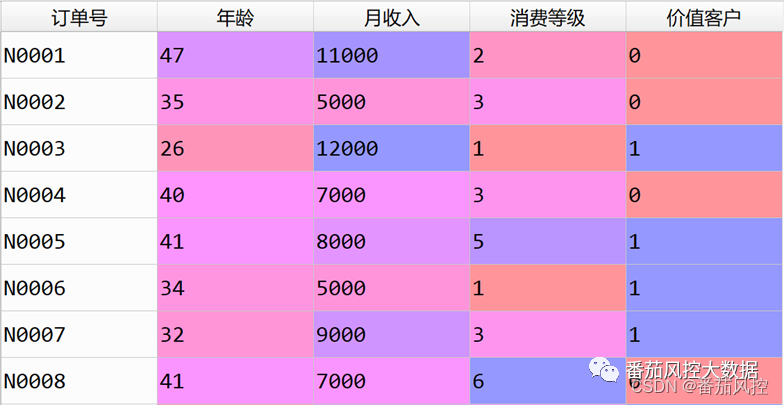
图3 建模数据样例
1、min-max标准化
特征min-max标准化,是根据样本各变量x的数据分布,分别取最大值max与最小值min,然后通过以下公式计算得到标准化后的数据x*,最终结果数据的取值范围会缩放至[0,1]。
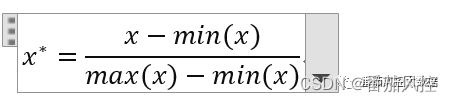
此外,特征min-max标准化,还有另外一种表现形式,即结果数据的取值范围会缩放至[-1,1],对应计算公式如下所示。
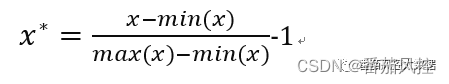
以上两种表现形式,原理逻辑是类似的,只是展现形式的区别,一般情况下以前者应用较多。在python语言中,可以通过图4代码实现,数据转换结果如图5所示。

图4 min-max标准化代码
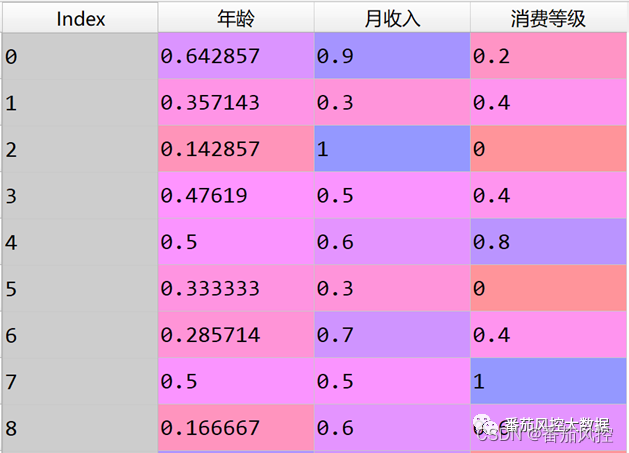
图5 min-max标准化结果
对于min-max标准化,虽然实现了平衡样本各维度特征权重的目标,但是由于不同特征数据分布的差异较大,在数据缩放变换的程度也是不同的,这样从整体上使原始数据的分布情况发生了一定的变化。
2、z-score标准化
特征z-score标准化,是根据样本各变量x的数据分布,分别取均值mean与标准差std,然后通过以下公式计算得到标准化后的数据x*,最终结果数据是以0为中心、标准差为1的分布形态。
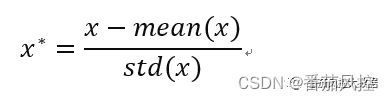
在python语言中,可以通过图6代码实现,数据转换结果如图7所示。
图6 z-score标准化代码
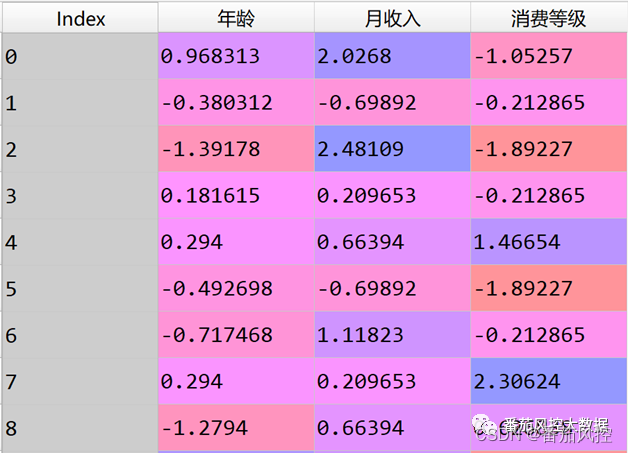
图7 z-score标准化结果
对于z-score标准化,与min-max标准化类似,都是对原始样本的特征数据进行了线性转换,也就是将特征样本点平移且缩短距离,使不同维度特征的原始数据具有可比性,从而保证特征在模型训练时权重得到统一。但是,z-score标准化与min-max标准化最大的区别,是z-score仅将原始数据的量级发生了变化,但数据的分布类型是不变的,而min-max后的结果在数据量级与数据分布上都与原始数据不同。
3、mean归一化
特征mean归一化,与min-max标准化的原理结构是很类似的,二者都是归一化的表达形式,其计算公式如下:
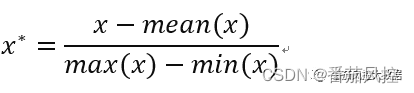
从公式可知,mean归一化的分子参数是特征的均值mean,而min-max归一化是特征的最小值min。
4、对数归一化
特征对数归一化,是对特征的原始数据直接取对数,也是归一化的表达形式,但属于一种非线性标准化的处理方法。因此,对数归一化没有将原始各维特征数据缩放到某一范围内,而是仅仅对各维特征的数据尺度进行了缩放,其计算公式如下:
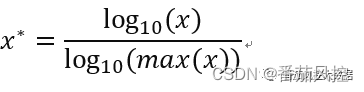
对数归一化的处理方法不仅起到了特征量纲统一的效果,而且并没有特征原始数据的分布性质以及相关程度。但是,这里需要注意的是,采用这种方法的前提是特征数据的取值均大于等于1才能保证公式有效。
5、中心化标准化
特征中心化标准化,也称为零均值化标准化,原理过程可以理解为是将特征原始数据进行了一个平移的过程,对数据的分布性质没有产生影响。经过处理后的数据,mean均值为0,也就是将数据整体平移到原点附近,其计算公式如下:
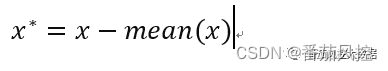
6、正则化标准化
特征正则化标准化,处理过程是对每个特征样本值除以对应范数,可以是L1范数或L2范数,使得转换后特征样本值的范数为1。数据转换前后,特征数据分布的性质没有发生变化,其计算公式如下:
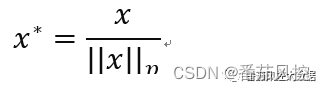
3、特征标准化应用
针对以上特征标准化方法,我们来介绍下特征标准化处理在建模过程中主要的应用场景以及注意事项。
(1)采用K-means、DBSCAN、KNN、SVM等算法建立模型时,由于原理涉及样本点距离计算,需要将特征的数据量纲标准进行统一,需要特征标准化处理,常采用min-max标准化或z-score标准化;
(2)采用PCA算法对特征数据进行降维时,由于模型需要去中心化,可以使用z-score标准化;
(4)若对特征转换后数据有具体取值范围的要求,需要进行min-max或mean等归一化处理;
(5)若特征数据存在较多异常值,可采用z-score标准化,避免异常值或极端值对数据分布的影响;
(6)若特征数据整体分布较为稳定,不存在明显的极端值,可采用min-max等归一化处理;
(7)处理使用梯度下降的参数估计模型时,对特征数据进行归一化处理,可以有效提高模型训练过程的收敛速度;
(8)建立决策树等概率模型时,由于决策树对特征数据量纲差异的敏感性较小,可以不采用特征标准化处理;
(9)对于最常采用的min-max和z-score标准化,在建模时当不确定使用哪种方式时,优先选择z-score标准化进行处理,原因是z-score处理方式不会影响特征原始数据的分布类型。
4、特征标准化对比
在以上内容中,我们共介绍了6种常用的特征标准化方法,同时重点对min-max标准化和z-score标准化进行了描述,并通过实际案例实操展示了数据处理后的分布结果。接下来我们根据min-max与z-score标准化的数据转换结果,采用KNN与XGBoost分类算法来分别实现本案例的价值客户预测模型,进一步对比下在不同模型算法、不同特征标准化的场景下,模型训练拟合后的模型性能表现。模型训练与模型评估的主要代码分别如图8、图9所示。
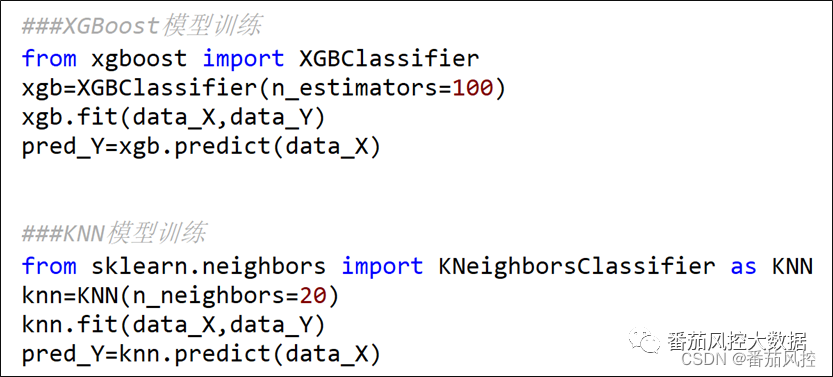
图8 KNN与XGBoost模型训练
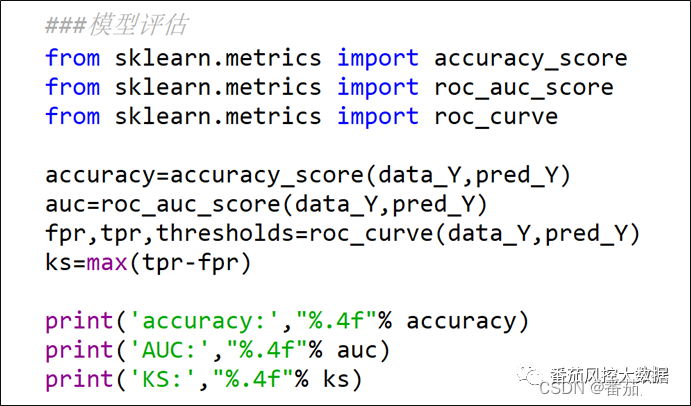
图9模型性能评估
最终各模型的性能指标(Accuracy、AUC、KS)如图10所示。
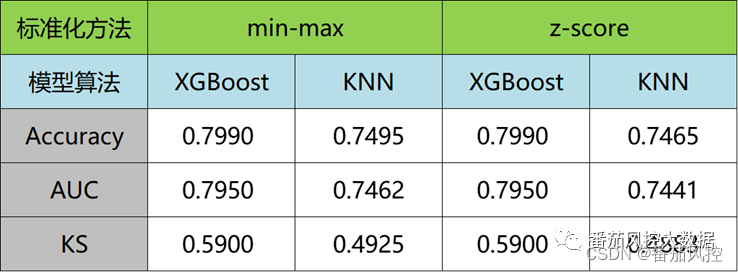
图10模型性能指标
从以上图结果可知,对于KNN分类算法,由于算法原理是根据样本点的距离进行模型拟合,因此对特征标准化数据非常敏感,虽然min-max与z-score转换方法有效保证了特征数据的量纲得到统一,但由于二者的数据转换逻辑不同,使得模型指标结果也有一定差异,例如Accuracy、AUC、KS,但数值之间的差异很小,说明min-max与z-score标准化方法对KNN分类算法建模都有很好的效果。对于XGBoost分类算法,从指标数据可以看到,二者结果是相同的,原因为XGBoost的本质原理是将多个决策树进行集成学习,而建立决策树概率模型的过程,对特征数据的量纲差异敏感性很小,可以不需要采用特征标准化处理。
综合以上内容,我们从整体上介绍了特征标准化的业务背景、常见方法、应用场景等,同时通过实际案例数据,对比分析了不同特征标准化方法的建模效果。当然,在实际工作中,大家在熟悉各种特征标准化方法原理的基础上,要重点掌握min-max与z-score的处理方法与应用场景。为了便于大家进一步对本文特征标准化内容的了解与熟悉,我们准备了与本文同步分析的编程代码与样本数据,供大家参考学习,详情请移至知识星球查看相关内容。

…
~原创文章















 5697
5697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









