







近期一段时间,番茄风控给大家分享了两次关于策略探索与开发的主题课程,干货满满,精华尽出,番茄课堂分别对应:
第78次课《信贷场景多维特征交叉策略的实战分析》
第79次课《信贷风控策略体系效果评估与全面调优》。
课程从实际业务场景出发,围绕信贷风控体系全面解读了各类策略的开发思路与实现方法,并从策略落地角度系统分析了策略效果评估与部署应用的重要内容。为了便于大家对信贷风控策略体系有进一步的理解,本文根据策略规则的多维开发与场景应用,对信贷策略的知识脉络做一个全面总结。
在金融信贷业务中,无论是针对C端个人产品,还是面向B端中小微企业产品,风控始终是整个业务的核心,风控的好坏直接关系到产品客户的质量、贷后还款的表现、业务经营的收益等。从信贷产品业务的生命周期来讲,风控体系的流程阶段往往可以划分为三个模块,分别为贷前、贷中、贷后。其中,贷中和贷后这两个环节针对不同信贷产品,在业务特点表现上存在一定区别,例如银行信用卡与互联网现金贷虽然同为信贷产品,但在业务模式上有明显的差异。对于风控贷前模块,对于不同形式的信贷产品,其风控逻辑与业务流程在体系架构、决策应用等方面大体是一致的。简单来讲,贷前环节都是通过多个维度的策略规则来识别申请用户的综合风险,并结合量化指标来完成用户的风险定价,并根据相关审批规则,实现风控贷前的决策效果。因此,对于信贷产品的风控流程,贷前是风控流程的第一个环节,也是风控体系的最核心模块,更是信贷业务的重点风控内容。
1、贷前风控策略体系
对于贷前风控体系,可以理解都是由多种类型多个维度的策略规则构成,虽然从风控开发的角度来讲有策略和模型之分,但模型应用的本质仍然是策略的表现形式,因此,由策略来架构风控,由风控来应用策略,是信贷风控的核心思想,也是日常策略分析、模型开发、数据挖掘等场景的重要体现,这是我们从事信贷风控工作需要特别认识到的。
贷前风控策略从应用表现形式来看,可以划分为准入条件、逻辑信息、要素核验、名单过滤、欺诈标签、信用标签、模型评分、额度定价等形式,如图1所示。当用户通过产品渠道提交申请信息后,产品流程发起进件状态,大数据风控系统会通过用户已授权获取的自有数据与三方数据,根据风控指定的指标加工逻辑得到策略相关的特征变量,然后按照决策引擎部署好的策略规则及其决策方法,来实现对申请用户多维度信息的风险识别与量化定价,并根据风控决策规则给出最终的审批结果,这样就实现了信贷业务贷前大数据风控系统的线上自动化决策流程,这也是完全满足实际业务需求的。

图1 贷前风控策略流程
风控策略规则在实际应用中,若希望获得满意的业务效果,需要对每个策略规则的加工逻辑与决策类型进行综合性管理。因此,在使用策略规则实现风控效果的同时,务必要学会策略规则开发的思路与方法,这样才能有效保证策略的灵活应用。对于策略规则的开发,根据特征类型、数据分布、实现方法、难易程度等多元化维度,策略规则挖掘的表现形式也是比较丰富。这里从业务类型、数据类型、特征类型、维度类型等维度,简单描述下不同形式下的策略表现类型:
(1)业务类型:准入条件、要素核验、欺诈风险、信用风险、额度定价等;
(2)数据类型:基本信息、人行征信、银联交易、电商网购、信用卡还款、APP设备、多头借贷、社交活动、运营商、网约打车、航旅出行、铁路交通等;
(3)特征类型:连续型、二分类离散型、多分类离散型(有序型、无序型);
(4)维度类型:单维特征变量分布、二维特征交叉组合、多维特征决策树模型等。
2、策略规则的开发
风控策略规则的开发方式,最常见的主要表现为三种情况,分别为单维特征变量分布、二维特征交叉组合、多维特征决策树模型,下面我们对各类方法的实现过程与效果评估进行全面介绍。为了便于量化分析,我们围绕实际业务场景案例来展开描述,并结合具体的样本数据,通过实操完成各类策略规则的探索与分析。
2.1 业务场景介绍
某消费金融公司为了完善线上信贷产品的风控体系,从外部多家三方数据机构引入不同维度的数据源,例如某电商平台的网购黑名单、银联机构的银行卡交易、某设备厂商的APP卸载次数、某网上约车平台的出行系数、非银机构的多头借贷信息、运营商的电话通讯次数、某互金公司的反欺诈等级…。风控策略分析团队围绕以上多维数据,拟开发满足公司信贷产品风控需求的策略规则,具体将从单维度标签分布、双维度决策矩阵、多维度决策树算法共三个方面,来实施策略规则的挖掘与分析,从而优化线上风控流程的综合决策能力。
场景案例的样本数据包含条10000条样本与12个特征,部分数据样例如图2所示,其中ID为样本主键,代表客户申请订单号;X01~X10为特征变量,分别为用户不同维度的字段信息;Y为目标变量,取值二分类,具体定义逻辑为客户贷后表现是否违约(1是/0否),样本数据的详细特征字典信息(变量名称、标签含义、分布类型、取值类型等)如图3所示。

图2 样本数据样例

图3 样本特征字典
2.2 样本特征分析
当样本数据准备完毕,通过数据探索分析,得到特征变量X01~X10、目标变量Y的统计分布信息分别如图4、图5所示。
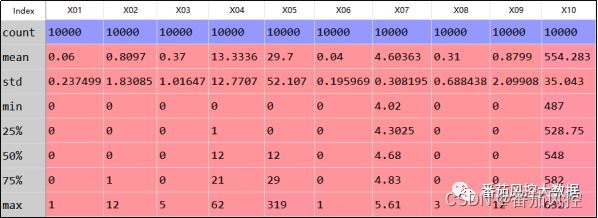
图4 特征变量分布

图5 目标变量分布
由图4特征变量count、图5目标变量num的分布结果可知,各特征字段均不存在缺失值情况,而且根据各变量的标签含义理解,特征分布也不存在明显的异常值情况。因此,后续便可以对各特征变量进行性能分析,主要是为了初步分析哪些字段有利于策略规则的开发,从而实现有针对性的策略探索及其分析。对于特征变量的性能分析,这里主要从特征相关性corr、特征预测性IV这两个维度进行评估。当然,在实践中还可以考虑分布稳定性PSI、模型贡献性inportance等方法。
通过corr()函数实现各变量之间的pearson相关性系数,其分布结果如图6所示,各变量之间的相关系数绝对值都低于0.5。由于在实际场景中,针对pearson系数的相关性评价一般以0.5~0.7(绝对值)范围内的某个阈值作为筛选判断标准,因此样本特征之间的相关性表现较弱,符合实际业务需求。
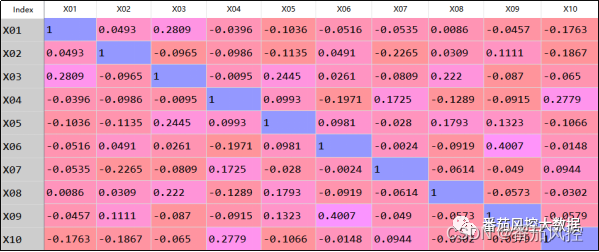
图6 特征相关性分布
以上特征相关性的分析过程,仅仅是对自变量的相互关系进行了探索,如果要分析每个特征自变量与目标因变量间的相关性程度,虽然适用于连续变量与连续变量之间相关性评估的pearson系数也具有一定分析意义,但针对分类变量与连续变量、分类变量与分类变量等情况相关性分析,可以采用更有效的方式来实现,不同情况的具体分析规则如下:
(1)连续自变量与连续自(因)变量:pearson相关系数
(2)连续自变量与二分类因变量:z检验
(3)二分类自变量与连续因变量:t检验
(4)多分类自变量与连续因变量:方差分析
(5)分类自变量与分类自(因)变量:卡方检验
对于特征变量的预测性分析,具体是通过指标IV来衡量的。在实际场景中,一般以0.02~0.1范围内某个阈值作为字段预测性筛选的判断标准,特征IV的批量实现过程如图7所示,最终输出各变量的IV值结果如图8所示。
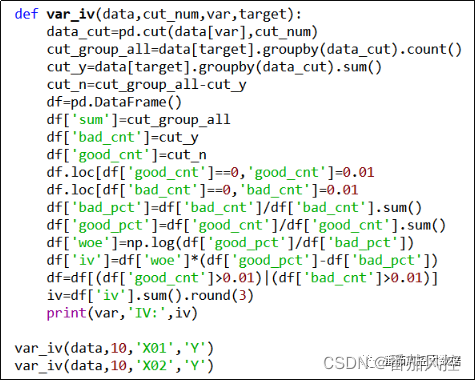
图7 特征预测性实现
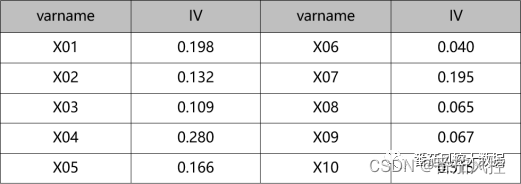
图8 特征预测性结果
从特征变量的IV值结果可知,各字段的预测性表现尚可,IV值没有明显小于0.02的较低情况,因此各字段可以都作为策略开发的特征对象。
2.3 单维特征标签分布
经过以上特征工程的分析之后,接下来到了策略开发的正式环节,首先来介绍单维特征标签分布的方式。这种方法的原理逻辑是将某特征变量进行分箱处理,然后根据不同区间的数据表现来决定是否作为规则,其中样本数据表现主要包含两个维度,分别为坏账率(badrate)与占比(percent)。一般情况下,区间样本坏账率要达到整体样本坏账率的23倍以上,区间样本占比最好保持在1%5%范围内。此外,样本分布趋势最好满足单调性,这样符合实际业务理解,而且规则区间选择尽量是左边界或右边界的范围,可以有效保证策略在后期的稳定性与合理性。
这里以特征X10(贷前申请信用风险评分)为例,来看下变量的分布情况,具体实现过程与输出结果分别如图9、图10所示。

图9 单维特征分布实现

图10 单维特征分布结果
由特征X10的分布结果可知,边界区间(486,501]范围内样本坏账率badrate达到57.8%,是整体样本坏账率18.65%(图5)的3倍以上,说明此区间样本群体的风险很高,而且样本占比也仅有5%,满足策略制定的基本条件。此外,从指标分布的趋势可以直观看出,随着X10(贷前申请信用风险评分)的增加,坏账率badrate整体呈现下降趋势,具有一定单调性而且满足实际业务理解。综上分析,特征X10可以开发出的策略规则为“当贷前申请信用风险评分(X10)<=501时,拒绝”。
根据以上分析方法,对于其他单维度特征,可以按照这个分析思路来分别探索策略规则,此处不再详细展开。
2.4 二维特征交叉组合
二维特征的策略开发,原理逻辑是采用决策矩阵的思想来实现,也就是将两个离散化处理后的特征进行二维交叉,然后根据每个组合单元的数据表现来决定是否可以作为规则,其中数据表现与单维度分析方法一样,也是通过单元组合下样本的坏账率(badrate)与占比(percent)来分析。二维特征交叉组合的原理结构如图11所示,这里需要注意的是,在选取某个组合作为策略规则时,最好是矩阵表的边角组合,可以是单个多区间,例如示意图中的X1-bin1与X2-bin1组合、X1-bin4与X2-bin4组合等,其原因是为了保证规则的业务解释性与分布稳定性。

图11 二维交叉组合原理
这里我们以特征X03(在我司贷款逾期最高天数)与X08(欺诈风险等级)为例,来介绍下二维特征交叉规则的原理逻辑。针对这2个特征的二维矩阵实现过程如图12所示,输出分布结果如图13所示。

图12 二维特征交叉实现
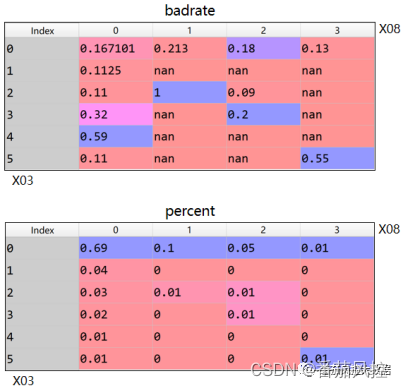
图13 二维特征交叉结果
由以上特征X03与X08的交叉结果指标(badrate与percent)分布可以看出,X03=5与X08=3交叉组合下样本群体的坏账率badrate达到55%,约为整体样本坏账率(18.65%)的3倍,而且样本占比仅有1%,满足二维特征规则开发的指标分布条件。同时,此区间对应X03与X08取值,在场景理解上也是完全满足业务逻辑的,也就是X03(在我司贷款逾期最高天数)与X08(欺诈风险等级)的取值越大风险表现越高。综上分析,根据特征X03与X08开发出的二维规则为“在我司贷款逾期最高天数(X03)>=5,且欺诈风险等级(X08)>=3,拒绝”。
对于其他特征二维组合,可以按照以上分析逻辑来实现,其中有个细节需要说明,针对连续型特征的交叉组合,在构建矩阵之前一定要对特征进行分箱离散化处理,然后根据离散区间来实现二维特征的决策矩阵。
2.5 多维特征决策树模型
多维特征的综合策略开发,决策树模型是非常有效一种实现方式,不仅原理逻辑简单,而且实现过程也较为方便。但是,在特征变量较多的情况下,采用决策树开发策略规则时,模型参数max_depth(树的深度)不要设置太大,主要原因是这样的规则虽然从区分度结果表现来看是比较好的,但在后期应用过程中很容易出现波动的情况,这是由于规则的特征复杂度引起的。因此,通过决策树模型算法开发规则时,参数max_depth最好定义在3~10范围之内。此外,模型训练拟合的特征变量,最好是经过特征工程筛选后的性能较优字段。
这里我们采用决策树回归算法来实现多维特征策略规则的开发,模型训练的拟合变量为X01~X10,具体实现过程如图14所示,最终输出的决策树结果通过可视化展示如图15所示。

图14 多维特征决策树实现
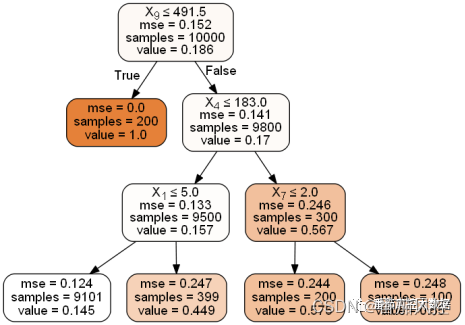
图15 多维特征决策树结果
根据决策树可视化结果,我们可以很方便的归纳出合适的策略规则,图中每个粪桶的samples代表当前区间的样本数量,value代表当前区间样本的坏账率,每个叶子单元的颜色代表了响应率的程度,颜色越深说明坏账率越高,也就是更适合作为策略。此外,需要注意的是,图中字段名称仅代表特征索引,以X9为例,X9具体是指样本数据的第10个特征(X0为第1个特征)。按照以上决策树分布结果与分析思路,可以得到相应的策略规则分别如下:
(1)当贷前申请信用风险评分(X10)<=491,拒绝;
(2)当贷前申请信用风险评分(X10)>491,且近6个月手机APP卸载次数(X05)>183,拒绝;
(3)当贷前申请信用风险评分(X10)>491,且近6个月手机APP卸载次数(X05)<=183,且近1年信贷违约账户数(X02)>5,拒绝。
3、策略规则的测试
通过以上三种方法(单维特征变量分布、二维特征交叉组合、多维特征决策树模型),我们实现了策略规则的开发。但是,此时并不能直接将各风控规则部署到线上来应用,而是需要完成策略规则的线下综合性能测试,以保证后续策略规则上线应用的可靠性。
对于策略规则的线下测试评估,主要包括三个维度,分别为综合命中率、整体坏账率、相互覆盖率。其中,综合命中率是指样本数据经过所有策略规则决策后的风控拒绝率;整体坏账率是指风控策略决策后拒绝样本的响应率;相互覆盖率是指各规则之间的重复命中率。当完成以上三个维度的线下测试之后,可以大体评估出策略规则后期上线后的整体效果,具体反映在拒绝率与坏账率这两个数据结果,这也是信贷业务最关键的指标信息,而相互覆盖率分析,便于我们对策略规则的优化,根据实际情况剔除某些重复拒绝样本且占比较高的规则,这有利于节约引入外部数据的成本,同时也可以精细化管理风控策略引擎,在后期策略效果监测与优化等方面也发挥着很好的效果。
在本文的案例场景中,开发出的部分策略规则如图16所示,具体包括单维、二维、多维共3种类型的规则。下面我们根据这些规则样例,简要描述下策略规则的线下整体测试效果。

图16 策略规则样例
首先是综合命中率与整体坏账率的测试分析,具体实现逻辑是将样本数据经过所有策略规则的决策,分别统计出每个样本命中规则拒绝阈值的数量,这样可以从个体和整体两方面,算出单个规则的命中率以及整体规则的命中率,然后针对策略规则的综合决策状态(通过/拒绝)可以划分为两部分样本群体,结合样本真实标签分布便得到整体坏账率表现,其分析结果如图17所示。
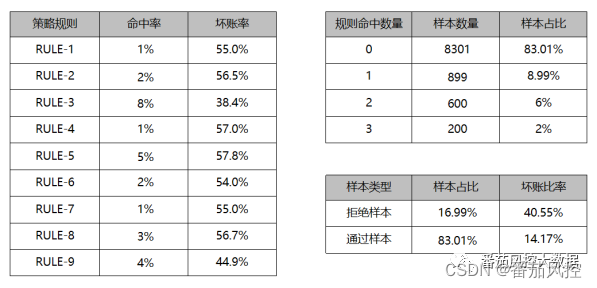
图17 策略命中率与坏账率
由以上结果可知,策略规则综合决策应用后,当前存量样本数据的风控拒绝率为16.99%,对应的坏账率表现为40.55%。对于样本命中规则数量的情况,我们可以初步了解到是否存在规则相互覆盖的情况,也就是规则拒绝的重复情况必然在规则命中数量>=2的样本群体中。通过对此类样本群体分析,分别研究各规则的命中情况,这里以RULE-1与RULE-2为例,来说明规则决策的重复情况,其分析结果如图18所示。
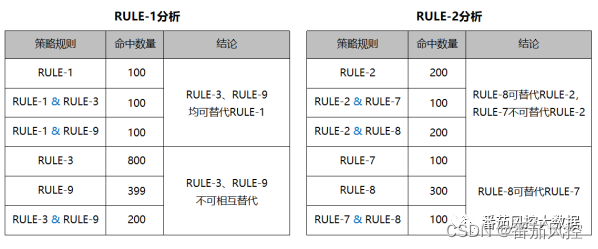
图18 策略规则覆盖率
通过以上分析结果可以很直观的获取相关信息,举个例子,由于RULE-1单独决策命中样本与RULE-1&RULE-3综合决策命中样本完全一致,则RULE-3直接可以替换RULE-1,而RULE-9同理;由于RULE-2与RULE-7的决策覆盖率为50%,则RULE-7不能替换RULE-2,原因是一般情况下重复率最好可以达到70%以上,当然具体需要结合实际场景综合决定。
当经过策略规则的相互覆盖率分析之后,如果有部分规则删除后,为了保证线下评估的效果,可以按照原始逻辑再次评估剩余策略规则应用的综合命中率和整体坏账率,至此便完成了策略规则在线下的综合性能测试。
4、策略规则的应用
在确定了可上线应用的策略规则后,决策引擎的策略部署也是非常重要的一个环节,这不仅需要了解各个策略规则的决策性能,而且要对策略的业务属性要非常熟悉,针对线上风控决策引擎上不同类型策略规则的部署顺序,这里简单举个样例,具体如图19所示。

图19 策略规则部署样例
在实际场景中,风控策略规则的部署需要综合考虑各种情况,这样才能较大程度发挥风控策略的决策效果,这里梳理出以下几个主要维度以供参考,具体如图20所示。

图20 策略部署综合维度
策略在风控流程中的应用,都是围绕实际业务展开的,并没有严格的绝对标准,需要结合信贷产品的业务属性、风控体系的架构模式、策略决策的整体效果等维度,来全面评估风控策略应用的效果。同时,在线上策略应用过程中,务必要对各策略规则的性能进行监测,例如决策阈值优化、配置顺序优化、规则重置优化等,这不仅是策略维护的需要,而且是风控效果的保障。
综合以上内容,我们围绕实际业务场景,给大家全面介绍了风控策略的探索开发与测试评估等重要内容,同时也分析了策略应用的主要思维及其方法。
由于知识干货较多且篇幅有限,需要了解更多详细内容,有兴趣的童鞋可关注:
第78节课:《信贷场景多维特征交叉策略的实战分析》。
第79次课:《信贷风控策略体系效果评估与全面调优》。
让各位小伙伴尽享“风控贷前策略体系的多视角开发与全方位应用”的干货盛宴!
…
~原创文章















 1939
1939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









