






Vision Transformer
Introduction
自transformer于2017年提出来在自然语言处理中取得的优异表现,其已经成为自然语言处理领域的标准模型。Transformer不同于以前的卷积神经网络,其摒弃卷积核这一基本操作,从而全面使用注意力机制去完成相关任务。在这篇论文中,作者将尽量不更改原transformer结构的基础上将该结构运用于视觉领域。
网络结构
原transformer在用于语言处理中将每一个token序列化作为输出,在图片领域,如果直接使用pixel层级作为token则用使整个序列长度过大,故需要对图片尺寸进行划分。这里将图片切分为一个个patch,将原尺寸为
H
∗
W
∗
C
H*W*C
H∗W∗C
的图片在二维尺度上以P大小进行切割,同时在C channel上进行拼接,则会最后得到
H
∗
W
/
P
2
H*W/P^2
H∗W/P2个patch,每个patch的大小为
P
∗
P
∗
C
P*P*C
P∗P∗C,再借用BERT中的思想,在最前面加上一个cls token用于最终的分类,故最终的序列长度为
P
∗
P
∗
C
+
1
P*P*C+1
P∗P∗C+1,之后所有序列进行patch+position embedding,得到的便可作为输入直接输入transformer的encoder中。以上描述可以用下图来表示:
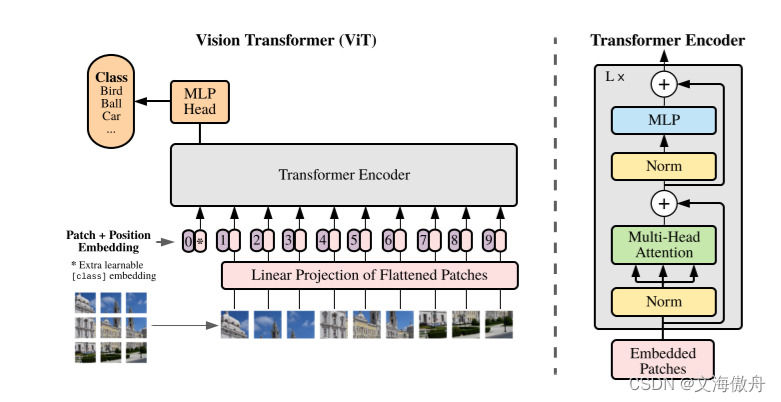
在这里可以看到,正如标题所言,在将一个16*16的patch看出语言处理中的一个token后,便可以实现图像处理和自然语言处理的统一模型。
其在Transformer Encoder中的计算过程如下:
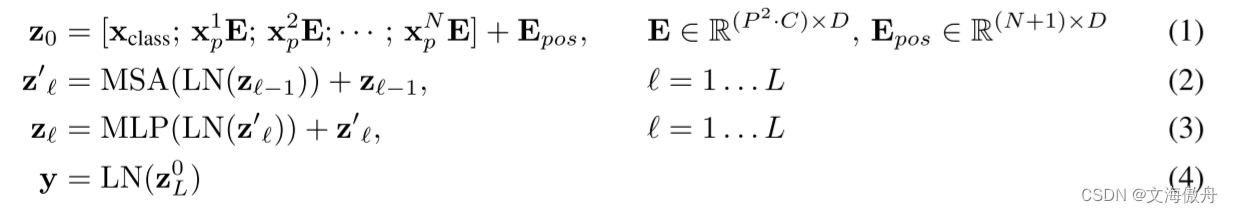
公式是对一个序列计算的完整表述。
模型分析
在论文中作者也有提到在较小数据库中训练时ViT训练可能并没有传统卷积结果好。作者认为其中原因可能是在传统卷积中使用了一些归纳偏置,作者提出了其中两种:局部偏置(locality)和偏移等价性(translationally equivariant)。正是这两种归纳偏置使卷积网络较Transformer有一种先验知识,在较小数据集的情况下可以表现更好。但如果增加数据集,Transformer的表现会更好。正如下图所说:
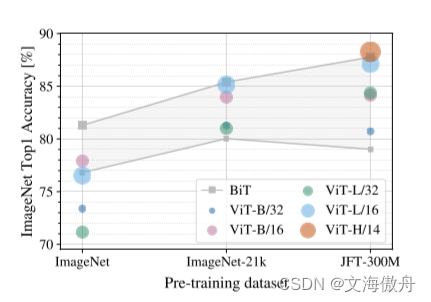
Swim Transformer
Introduction
在transformer用于图片分类任务后,其在大数据集上表现的结果十分优异,但是否以Transformer为基本结果的网络可以广泛运用于所有CV领域呢?Swim Transformer给出了答案,其证明以Transformer为基本结构的网络可以在所有视觉领域应用并取到十分好的结果。
网络结构
首先来看原Transformer在图片处理上的一些缺陷。如下图所示:
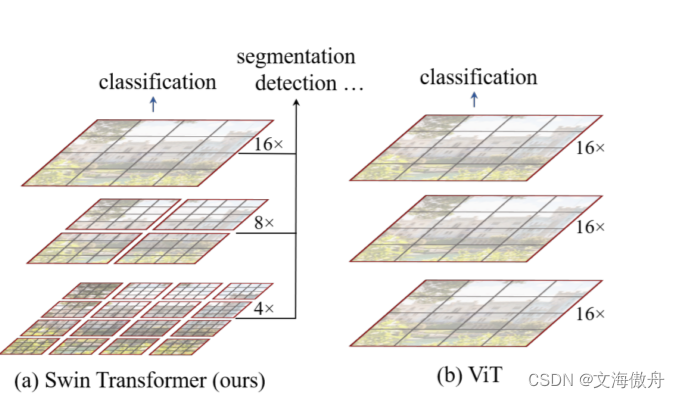
ViT在训练中每一个patch尺寸并不会发现变化,在本图中始终以16倍的采样率存在。这一导致的问题是:首先复杂度会随图片尺寸成平方比率增长,这可以通过
(
H
p
∗
W
p
)
2
(\frac{H}{p}*\frac{W}{p})^2
(pH∗pW)2知道;第二是这样的设计缺乏多尺度的探测,这在对于多尺度尤其重视的目标切割等任务中尤其不利。而Swim Transformer借鉴经典卷积网络的一些设计对原ViT进行改进。
首先采用窗口设计,在每一个窗口中进行自注意力计算,这样保证即使图片尺寸变大,也只会增加窗口数目,但每个窗口计算量仍不变,保证变成线性增长。同时为了保证模拟全局建模和多尺度结果,这里使用了patch merging layers和shifte Windows。
网络具体结构如下所示:
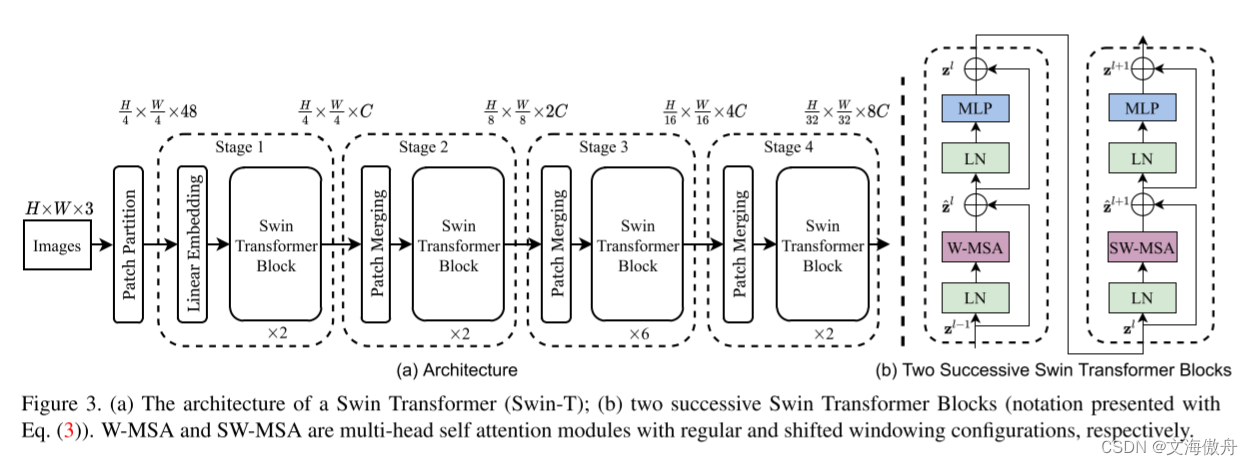
在Swim Transformer Block中首先进行patch merging layers。以论文中的2倍率为例,将一个小patch和周围的4的patch群组成一个大的patch,在图片尺寸为H*W,patch尺寸为p,采样率为2的情况下,
H
p
∗
W
p
/
(
2
∗
2
)
\frac{H}{p}*\frac{W}{p}/(2*2)
pH∗pW/(2∗2),这减少的4倍会拼接成维度,并通过1*1卷积降维成2C。这里增加维度而降低图片尺寸的方法与ResNet类似。而shift windows可以通过移动像素点交换不同windows之间的交流,在具体计算中会涉及到掩码的设计。
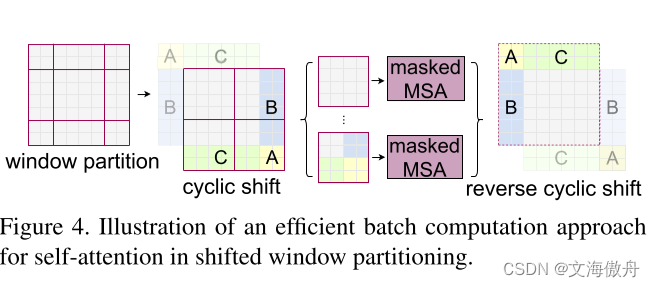
如上图所示,提前根据相关位置设计掩码,便可以保证在计算时快捷便利。
ConvNeXt
introduction
自ViT引入图像处理领域,以transformer为主要框架的模型在图像分类上较传统卷积展现了精确度上的优势。而在Swim Transformer横空出世后,目标检测等任务也被transformer框架所掌握。而Swim Transformer虽然在框架上仍然采用Transformer的主干,但其在设计中仍采取了很多卷积网络中的思想,作者认为这代表了卷积网络网络的一些要素并不是毫无意义的,相反其被证明是在今天仍没有褪色。故遵循同样思想,使用Transformer中的一些设计去“现代化”传统的ResNet网络,是否可以让传统卷积网络变得更好呢,作者在这里给处理肯定的答案。
网络框架
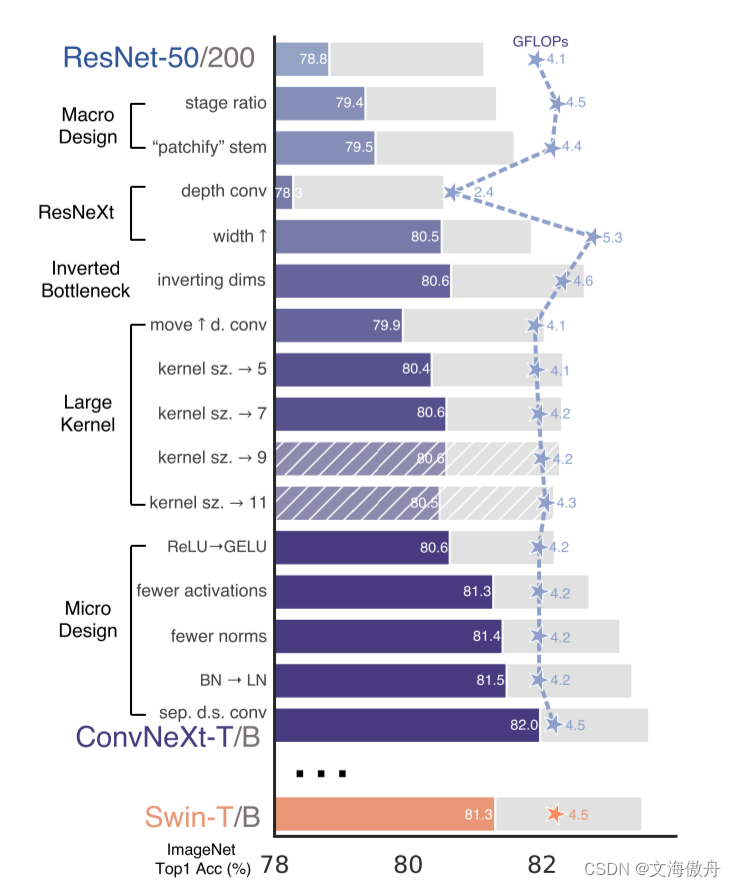
从传统ResNet-50网络进行改造的全过程如上图所示,作者将其分为五个阶段–Macro Design、ResNeXt、Inverted Bottleneck、Large Kernel、Micro Design。
第一个阶段主要是对一些超参数进行改变,首先是stage ratio,即各个stage数目比例,作者由之前的(3,4,6,3)改变为(3,3,9,3),同时借鉴Swim Transformer中的思想,采用类似Swim Transformer中的“patchify stem"。在第二个阶段,作者提出在使用depthwise convolution的捅死要增加网络的宽度。在第三个阶段,如下图所示: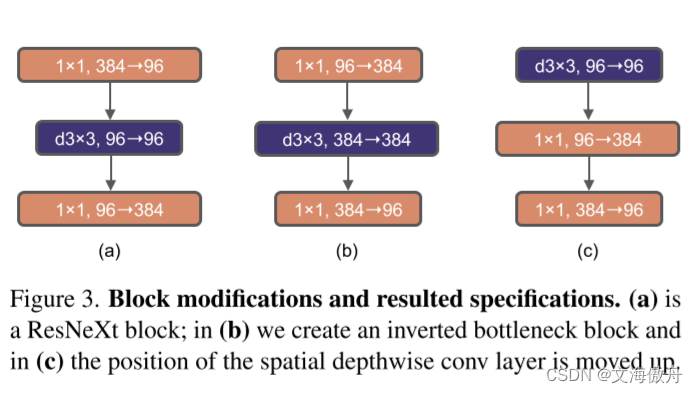
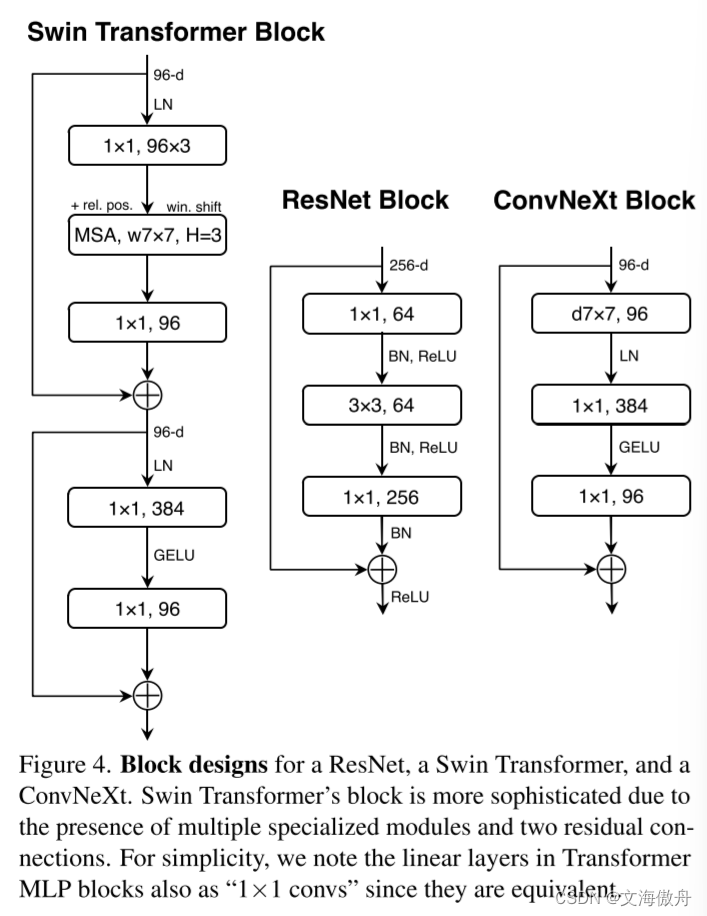
使用了Inverted Bottlenect结构。在第四个阶段采用大卷积核,作者注意到在Swim Transformer中最小的窗口尺寸都是77,这显然比RexNet中的33卷积核大。故作者重新设计了卷积核,仍然如上图所示,将depthwise Convolution前移到piexlwise Convolution前面,同时在每一个块中使用7*7的卷积核。最后的Micro Design中对一些激活函数等设置进行更改。最终这一新改进的卷积模型成为ConvNeXt。最终比较如下:
结论
ConvNeXt的提出重新看到了卷积的重要性,其在多个数据集上都较以Transformer为框架的网络性能优异。作者提出希望这一令人激动的研究成果可以改变目前广泛持有卷积网络不如Transformer的观点。















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









